一种基于原型动态更新和深度度量学习的增量学习方法
- 国知局
- 2024-07-31 23:14:46
本发明涉及一种基于原型动态更新和深度度量学习的增量学习方法,涉及模式识别领域。
背景技术:
1、随着数字化社会的快速发展,机器人智能技术在多个实际应用中得到了广泛的应用,如工业制造、自动化仓库以及智能物流等。然而,在机器人应用中,随着机器人和环境的交互,机器人需要不断地学习新任务和环境,以满足不同任务的需要,比如导航、物体识别等。这些任务可能是在机器人运行期间动态出现的,并且需要机器人快速地适应和处理。然而,这种动态变化的开放场景对机器人学习构成了严峻的挑战,因为传统的学习方式无法很好地应对新的数据或任务。因此,增量学习技术被引入到机器人应用领域中,并成为了实现机器人智能的重要手段,它帮助机器人能够持续优化以学习新任务的知识,同时又能很好地维持在旧任务上的性能,提高机器人的智能水平和适应能力。
2、在增量学习场景中,模型往往会面临灾难性遗忘问题,即在学习新任务后,模型在已经学习过的旧任务上的表现会急剧下降。因此,如何解决灾难性遗忘问题,让模型在学习新任务的同时保持对旧任务的记忆,是实现高性能增量学习模型的重要难题。为了解决灾难性遗忘问题,现有技术可以分为四类。首先是正则化方法,通过对模型参数的更新设置额外的约束来减少旧知识的遗忘。其次是参数隔离方法,这类方法主要有两种实现思路,一是为新任务扩展更多的参数,二是引入掩码实现任务间的参数隔离。然后是样例回放方法,它基于松弛的增量设置,在学习新任务时,新类样例和少量旧类样例会混合在一起训练,从而防止旧类的知识被遗忘。最后是原型回放方法,它并不需要存储任何旧任务的数据,只要求为每个旧类计算并保存一个原型。
3、本发明从原型回放的角度出发,利用多视角原型动态更新模块和表征级代理损失模块来缓解增量学习过程中的知识遗忘问题。为了解决这个问题,一方面,我们引入多视角原型动态更新模块,通过挖掘旧类原型中的深层表征信息和多样性信息来增强模型对旧知识的记忆能力。另一方面,我们引入表征级代理损失模块,通过约束新类数据的特征分布,拉近类内距离,推远类间距离,从而保证新类知识的高效学习。总的来说,在我们的工作中,通过减少旧知识损耗和缓解表征级分布重叠以解决增量学习过程中存在的灾难性遗忘问题。
技术实现思路
1、技术问题:本发明提供一种能够解决机器人智能应用问题的增量学习算法,通过在传统的原型回放方法中引入多视角原型动态更新模块来丰富原型在其他视角的多样性信息和判别信息,同时根据可访问数据的空间变化信息估测原型的偏移,使得模型能够实时更新旧类原型的表征信息,从而提高增量模型在机器人智能应用问题的分类性能。
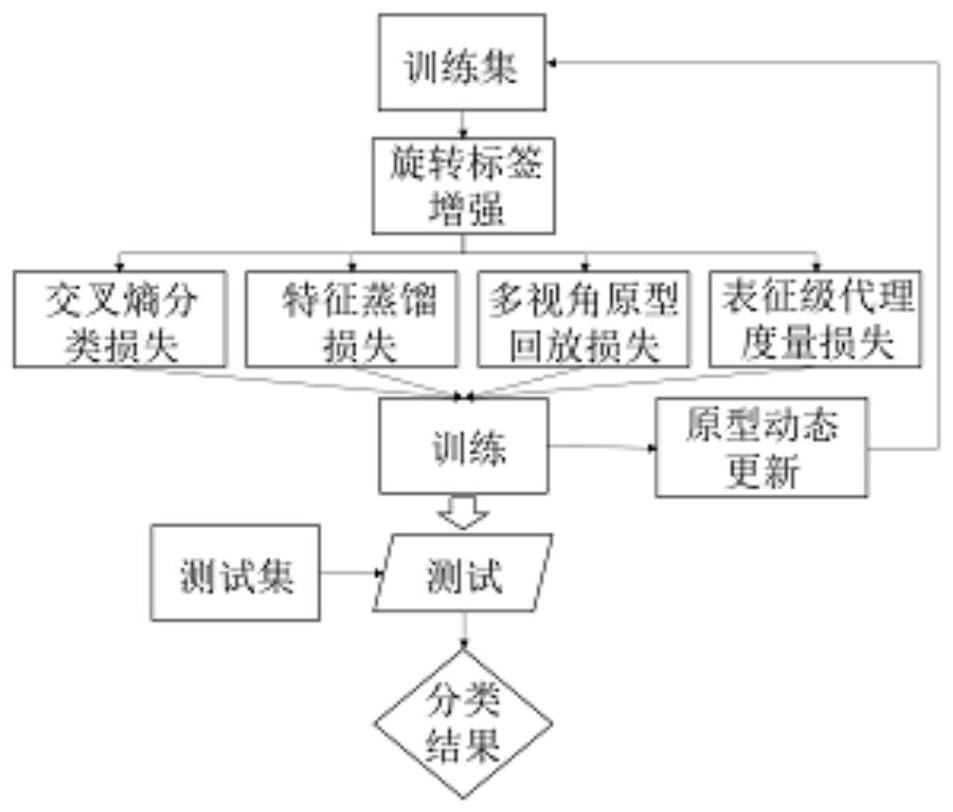
2、技术方案:首先,将原始样本数据划分为训练集和测试集两部分;其次,对训练集中的数据进行旋转标签增强的操作,并将处理后的数据输入到特征提取器中提取特征;接着,在学习新任务时,模型在已有的交叉熵损失和特征蒸馏损失的基础上,进一步融入多视角原型回放损失和表征级代理度量损失,从而得到本方法的优化目标;然后,在每一轮增量阶段后,模型根据当前在线任务中数据的已知偏移,来近似估计已保存的旧类原型的未知偏移并动态更新原型;最后,在测试阶段中,将经过多视角扩展的测试样本代入到基于多视角场景的集成分类器中进行识别。
3、本发明解决其技术问题所采用的技术方案还可以进一步细化。所述的训练阶段的第一个步骤中,表征级代理度量损失是由实时更新的代理和数据在表征层面的几何关系来实现定义的。在实践中,从几何层面约束特征分布可以使用各种改进的度量损失,如基于样本对的度量损失和基于代理的度量损失。为了不增加模型的复杂度,在本发明中采用了深度度量学习领域的代理锚点损失。最后,在原型回放损失的实现中,本发明引入高斯噪声对原始原型进行表征信息的增强,从而提高模型的泛化能力和抗扰动性。
4、有益效果:本发明与现有技术相比,具有以下优点:
5、将现有的增量学习方法应用到机器人智能应用问题时,由于其没有考虑机器人智能应用问题的特征,导致分类结果对旧类样本很不利。而这种结果和机器人智能应用问题本质背道而驰。本发明第一次结合自监督标签增量对原始的旧类原型补充其他视角的多样性信息,来解决机器人智能应用问题。与现有的增量学习方法不同,本方法从特征层面出发,同时考虑新旧数据的分布情况和机器人智能应用问题本身的特点,并利用当前任务中数据点的空间变化信息近似估计旧类原型的偏移,从而动态更新旧类原型的表征信息。
6、另外本方法研究了新任务中类别的代理和数据点之间的几何关系,采用基于表征级代理的度量损失来约束新类在特征空间中的分布过于松散,使得相同类的数据特征更加紧凑,不同类的数据特征更加分离。因此相对于传统的增量学习方法,本方法在机器人智能应用问题中有合理的分类效果。
技术特征:1.一种基于原型动态更新和深度度量学习的增量学习方法,其特征在于,该增量分类器的训练过程包括以下步骤:
2.根据权利要求1所述的基于原型动态更新和深度度量学习的增量学习方法,其特征在于:步骤3)的多视角原型回放损失;在增量阶段t时,为已学习的旧类计算基于原型回放的损失;如果任务t是增量过程中的基任务,则不存在原型回放的阶段,即没有该损失项;否则,在完成任务t-1的增量学习阶段后,利用以下公式计算该任务中的原型:
3.根据权利要求1所述的基于原型动态更新和深度度量学习的增量学习方法,其特征在于:步骤3)的表征级代理度量损失;在任务t的学习阶段,为每个新类别都分配一个表征级代理作为锚点,并引入一个表征级代理损失来差异化约束代理和数据间的几何关系;基于表征级代理的度量损失lrp定义如下:
4.根据权利要求1所述的基于原型动态更新和深度度量学习的增量学习方法,其特征在于:步骤4)的动态更新策略;在完成任务t的学习阶段后,使用动态更新策略实现对旧类原型的实时修正;动态更新的步骤如下:首先,计算当前任务中样本点的已知偏移样本点xi的偏移计算公式如下:
5.根据权利要求1所述的基于原型动态更新和深度度量学习的增量学习方法,其特征在于:步骤5)的基于多视角场景的集成分类器;输入测试样本,首先对测试样本依次旋转η(η=0,90,180,270)度,接着对这些转换后的样本分别测试并得到相应的4v类响应输出,其中v表示测试集中的类别数;然后,对于不同值对应的响应输出,模型分别选取η+1+4·k(k∈n)位的logits输出单元,即不同视角下的v类响应输出;最后,模型对不同视角下的响应输出求和并平均,并将得到的平均值作为最终概率输出。
技术总结本发明公开了一种基于原型动态更新和深度度量学习的增量学习方法。该方法包括:1)引入多视角原型动态更新策略,通过挖掘旧类原型中的表征信息和多样性信息来减少旧知识的损耗;2)为了保证新类知识的高效学习,通过结合深度度量学习中的代理模型,从而约束新类数据的特征分布,拉近类内距离,推远类间距离,从而实现更好的分类性能;3)弥补了现有的增量学习方法忽视对几何信息的利用,结合新类数据的特征分布情况,从表征层面研究并利用代理和样本间的几何关系,将增量学习算法推广到机器人智能应用问题中。技术研发人员:王喆,肖婷,张禹,许鑫磊,傅志凌受保护的技术使用者:华东理工大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/196612.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表