一种智能导盲方法、装置及系统
- 国知局
- 2024-07-31 23:16:22
本发明涉及计算机视觉的目标检测及智能导盲设备研发领域,具体涉及一种智能导盲方法、装置及系统。
背景技术:
1、随着中国社会的发展,虽然居家出行已经越来越方便了,但就近几年来看,我国盲人或者视力障碍的人也越来越多。而近年来伴随着日常生活环境、小区等一些休闲地方障碍物的增多以及物体车辆的乱摆乱放问题,所以视障人士面对居家出行有着很大的问题,同时也增加了视障人士居家出行的安全隐患,所以解决视障人士居家出行问题显得尤为重要。
2、相较于传统目标检测算法,考虑到日常生活环境中的障碍物种类繁多,形状大小以及障碍物背景不一的特点,会导致目标检测算法可能会难以准确检测到它们。而过去传统的一些目标检测算法过于复杂,运行速度慢。深度学习算法虽然本身性能不错,但由于目标障碍物种类繁多,形状大小不一等不确定性因素,导致深度学习算法不能精确的提取障碍物特征。
技术实现思路
1、为解决以上现有技术存在的问题,本发明提出了一种基于人工智能算法的智能导盲方法、装置和系统。
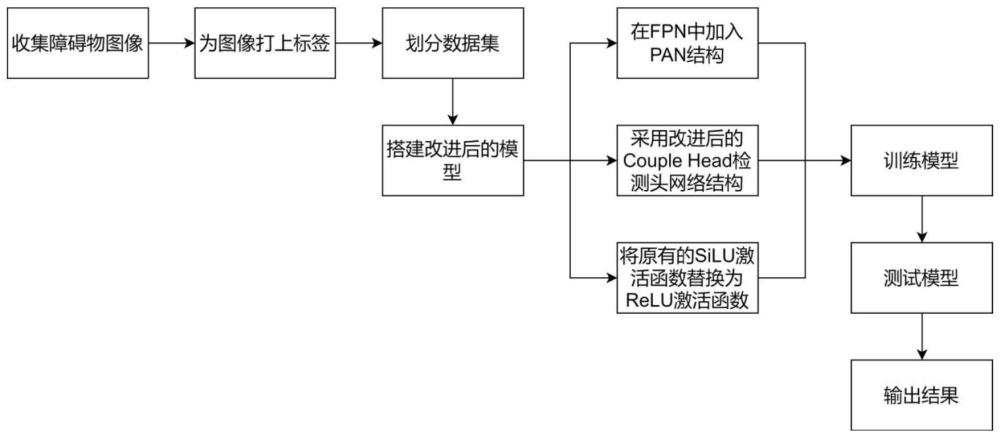
2、本发明的第一方面,提供一种智能导盲方法,包括:实时检测前方是否有障碍物,将摄像头获取的图片数据输入到训练好的深度学习模型中,得到障碍物检测结果,根据结果来发出不一样的语音进行提醒;
3、训练深度学习模型的过程包括:
4、s1:获取原始数据集,对原始数据集进行数据增强处理,得到增强数据集;增强数据集中的图片包括不同种类的障碍物原始图片和增强后的图片;
5、s2:对增强的数据集进行划分,得到训练集,验证集和测试集;
6、s3:将训练集中的数据输入到改进后的深度学习模型的输入端进行预处理;
7、s4:将预处理后的图片输入到骨干网络中进行特征提取,得到特征图;
8、s5:将特征图输入到neck网络中进行特征融合处理,得到检测框;
9、s6:对检测框进行筛选,得到预测框;
10、s7:将测试集中的数据输入到模型中,根据预测框得到检测的结果;
11、s8:根据检测结果计算模型的损失函数,不断调整参数,当损失函数的值最小时,完成模型的训练。
12、进一步地,通过mosaic数据增强方法对原始数据通过裁剪的方式保留重要的信息部分,然后将四张截取后的图片进行随机的组合及随机缩放的操作组成一张新的图片。
13、进一步地,深度学习模型的backbone中采用改进后的sppf,将原有的silu激活函数替换为relu激活函数,其中relu的运行过程为:
14、s1:给定一个输入值x;
15、s2:计算relu函数的输出值y,即max(0,x),如果输入值x大于0,则输出为x本身;如果输入值x小于等于0,则输出为0;
16、s3:计算得到的输出值y作为relu激活函数的结果。
17、进一步地,深度学习模型的neck网络包括fpn单元和pan单元,pan引入了横向连接,将相邻层级的特征图进行融合,pan通过在fpn的每个层级之间添加横向连接,将低分辨率特征图上采样并与高分辨率特征图进行融合,并且pan网络通过自顶向下的路径聚合和自底向上的像素聚合来整合不同层级的特征。
18、进一步地,采用改进后的coupled head检测头网络结构,其过程包括:
19、s1:使用卷积神经网络(cnn)对输入图像进行特征提取,这些特征将用于后续的目标检测任务;
20、s2:构建特征金字塔,通过在网络中添加多个分支或多个卷积层来实现,每个分支或卷积层负责处理不同尺度的特征图;
21、s3:在每个分支或卷积层上,使用卷积操作对特征图进行处理,以生成目标检测的预测结果,预测结果包括目标的位置、类别和置信度;
22、s4:对于每个尺度的预测结果,应用后处理技术以过滤重叠的检测框并选择最佳的检测结果;
23、s5:将不同尺度的预测结果整合在一起,得到最终的目标检测结果。
24、进一步地,将检测头分为两个独立的部分,一个检测头负责检测小尺度目标,另一个检测头负责检测大尺度目标。
25、进一步地,计算模型的损失函数为:
26、
27、α=2-e-γρx-e-γρy
28、
29、
30、
31、
32、
33、其中,iou表示两个矩形框重叠部分的的交并比iou的损失,α表示距离损失,β表示形状损失;e为自然底数;ρx,ρy分别为x,y轴方向上的步长;γ表示随角度的增加,被赋予距离值的时间优先级;λ为角度损失;rw,rh是宽和高方向上的形状损失;cw,ch为真实框和预测框最小外接矩形的宽和高;w,h,wgt,hgt分别为预测框和真实框的宽和高;θ控制对形状损失的关注程度;为真实框中心坐标(bcx,bcy)为预测框中心坐标;σ为真实框和预测框中心点的距离。
34、本发明的第二方面,提供一种智能导盲装置,包括用于实现上述的智能导盲方法的功能模块。
35、本发明的第三方面,提供一种智能导盲系统,包括盲杖及安装于盲杖上的控制主板、摄像头、超声波装置及扩音器,摄像头、超声波装置及扩音器分别与控制主板电性连接,控制主板包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述的智能导盲方法的步骤。
36、进一步地,包括:
37、第一模块,被配置为:通过控制主板(1)对图片运用改进的深度学习算法对目标障碍物进行检测分类,图像在输入端进行数据增强,然后通过深度学习算法的核心卷积层网络特征提取结构,对图像进行特征提取,最后在输出端进行数据分类,将障碍物的种类反馈给视障人士;
38、第二模块,被配置为:通过摄像头(2)将实时的图片传入到控制主板(1)中去;
39、第三模块,被配置为:先通过超声波装置(3)测距,判断前方障碍物的距离,如果障碍物的距离小于设定的安全距离,通过障碍物检测模块将盲道上的障碍物进行识别判断,最终以蓝牙语音提示的方式将障碍物的距离和种类反馈给视障人士;
40、第四模块,被配置为:通过扩音器(4)将控制主板(1)检测出来的结果传递给视障人士。
41、与现有技术相比,本发明的优点在于:相较于传统的深度学习模型,改进后的深度学习模型提升了对于检测日常生活环境小型障碍物的检测的泛化能力和精确度,能过更好的帮助盲人规避路上的障碍物,为广大盲人的出行提供便利。
技术特征:1.一种智能导盲方法,其特征在于,包括:实时检测前方是否有障碍物,将摄像头获取的图片数据输入到训练好的深度学习模型中,得到障碍物检测结果,根据结果来发出不一样的语音进行提醒;
2.根据权利要求1所述的智能导盲方法,其特征在于,通过mosaic数据增强方法对原始数据通过裁剪的方式保留重要的信息部分,然后将四张截取后的图片进行随机的组合及随机缩放的操作组成一张新的图片。
3.根据权利要求1所述的智能导盲方法,其特征在于,深度学习模型的backbone中采用改进后的sppf,将原有的silu激活函数替换为relu激活函数,其中relu的运行过程为:
4.根据权利要求1所述的智能导盲方法,其特征在于,深度学习模型的neck网络包括fpn单元和pan单元,pan引入了横向连接,将相邻层级的特征图进行融合,pan通过在fpn的每个层级之间添加横向连接,将低分辨率特征图上采样并与高分辨率特征图进行融合,并且pan网络通过自顶向下的路径聚合和自底向上的像素聚合来整合不同层级的特征。
5.根据权利要求1所述的智能导盲方法,其特征在于,采用改进后的coupled head检测头网络结构,其过程包括:
6.根据权利要求5所述的智能导盲方法,其特征在于,将检测头分为两个独立的部分,一个检测头负责检测小尺度目标,另一个检测头负责检测大尺度目标。
7.根据权利要求1所述的智能导盲方法,其特征在于,计算模型的损失函数为:
8.一种智能导盲装置,其特征在于,包括用于实现如权利要求1-7任一项所述的智能导盲方法的功能模块。
9.一种智能导盲系统,其特征在于,包括盲杖及安装于盲杖上的控制主板(1)、摄像头(2)、超声波装置(3)及扩音器(4),摄像头(2)、超声波装置(3)及扩音器(4)分别与控制主板(1)电性连接,控制主板(1)包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现权利要求1至7中任一项所述的智能导盲方法的步骤。
10.根据权利要求9所述的智能导盲系统,其特征在于,包括:
技术总结本发明公开了一种智能导盲方法、装置及系统,涉及计算机视觉的目标检测及智能导盲设备研发领域,该方法包括:采用ReLU激活函数用于深度学习中的SiLU激活函数,同时结合使用上采样模块(PAN)进行自下而上的上采样用于捕捉小型障碍物的局部特征信息,增加小型障碍物特征信息的提取能力;针对复杂环境下,容易出现同类型障碍物多背景下的场景,导致检测回归精度低、模型泛化能力低的问题。采用改进后的耦合头(Coupled Head)检测头模块,将分类和回归任务单独进行,并且结合采用新的SIoU边界框损失函数,提高对多背景下障碍物的检测精度和模型的鲁棒性。同时本发明还提供了一种基于智能导盲方法的装置及系统,智能导盲系统包括盲杖及安装于盲杖上的摄像头、超声波测距装置及扩音器。经实验结果表明,应用该智能导盲方法、装置及系统,其障碍物检测得检测精度、召回率和平均精度等各项指标都有提升。技术研发人员:邓华,张细政,李直鸿,禹锦明,谭腾飞受保护的技术使用者:湖南工程学院技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/196742.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表