一种基于强化学习的无监督视频摘要算法方法
- 国知局
- 2024-07-31 23:19:18
本发明属于计算机视觉领域,涉及基于强化学习模型的无监督视频摘要方法,以解决在无监督环境下对视频中重要内容进行摘要提取的问题。
背景技术:
1、互联网媒体发展迅捷的当下,视频作为信息载体量大、直观方便获取的视觉内容,已然成为最重要的多媒体传播途径之一,给人们的生活带来了巨大的便利。然而视频格式的媒体含有大量冗余内容,且其高密度的信息容量也造成了直播卡顿、存储不足等问题。对于用户来说,往往一个视频中想要关注的点只有几个片段甚至几个画面,一些视频本质上只是依照文字内容搭配上了相关联的图像,以减少用户的枯燥感。同时,海量的视频内容也为视频检索带来了极大的困难,依照简单的视频标签无法细分视频的具体内容,而依照视频内容进行逐个检索非常消耗时间与精力。
2、针对这个问题,一类视频摘要算法被提出,随着计算机视觉领域和深度学习领域的飞速发展,利用算法自动生成视频摘要可以极大降低原视频的冗余内容,提高存储效率与信息获取效率。通过分析视频信息之间的重合度和依赖性,可以提取出视频中最为重要的镜头片段,并生成简短的视频摘要,使内容得到精简化,有助于使用者在不断增加的庞大视频数据中检索、预览需要寻找的视频内容,同时大大减少了视频分析工作中所需要的人力。
3、然而当前流行的视频摘要大多为有监督算法,较为依赖人工标注的数据集,同样需要消耗大量人力来进行数据标注工作。且依照数据集训练好的视频摘要模型更加难以适应新的视频种类与内容。
技术实现思路
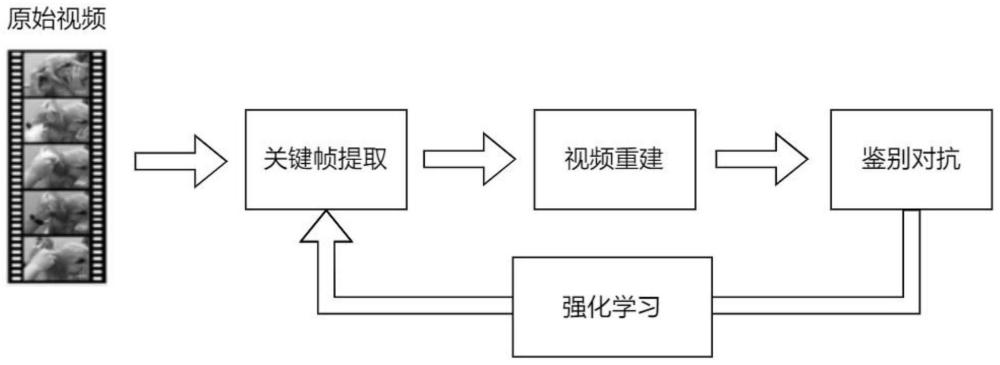
1、为了克服上述现有技术的缺点,本发明提供一个基于强化学习的无监督视频摘要方法,通过强化学习在视频序列问题上产生长期回报的优势来选择视频摘要,然后生成得到的视频摘要进行视频重建,根据重建视频与原视频的信息特征相似度来评价强化学习模型生成摘要的质量,从而训练模型改进。该方法能够有效根据视频摘要工作的定义从视频中提取重要镜头片段,并且训练过程不依赖任何人工标注数据,仅需根据原视频内容即可达成视频摘要训练目的。
2、为了实现上述目的,本发明采用的技术方案一种基于强化学习的无监督视频摘要算法,其特征在于,包括如下步骤:
3、s1:基于演员-评论家模型的关键帧提取,获取最优视频摘要:
4、s1-1:演员模型使用双向lstm网络(lstm,long short-termmemory长短期记忆网络,一种特殊的循环神经网络(rnn),1997年,sepp hochreiter和jürgen schmidhuber[1]提出,可以有效解决rnn难以解决的人为延长时间任务的问题,并解决了rnn容易出现梯度消失的问题。[1]s.hochreiter and j.schmidhuber,“long short-term memory,”neuralcomput,vol.9,no.8,pp.1735–1780,nov.1997.)根据原视频特征序列在时空特征上的依赖关系对视频帧的重要度进行初始化,所述时空特征表示视频存储空间中视频帧根据存储时间依次排列的空间关系,由池化操作将视频分为m个时长为d的非重叠片段,将初始化后的视频帧重要度分数计算为片段重要度分数,公式如下:
5、
6、
7、
8、式中,f表示原视频的片段重要度分数序列,fj表示视频池化后的第j个片段,st表示初始化得到的t时刻帧重要度分数,表示原视频池化后的总片段数量,d表示非重叠片段的时长,m表示池化操作分割的m个时长为d的非重叠片段;
9、s1-2:演员模型根据当前重要度分数选择重要度分数最大的一个片段,根据所述片段中迭代次数与非重叠片段的数量关系,计算加权因子与衰减因子,公式如下:
10、
11、rf=(m-n)/m
12、式中,表示第n轮计算得到的加权因子,rf表示每轮选择过后对每个视频帧的重要度进行衰减处理的衰减因子,n表示第n轮迭代,m表示池化操作分割的m个时长为d的非重叠片段;
13、s1-3:演员模型将加权因子和衰减因子送入评论家模型,评论家模型通过加权因子和衰减因子得到关键帧评论重要度分数,演员模型根据所述分数修改选择关键帧的策略,n轮迭代后得到当前选择出的最优视频摘要;
14、s2:基于注意力自编码器的视频重建:
15、s2-1:注意力自编码器处理任意视频摘要时间为t的步骤时,利用上一步获得的隐藏状态ht-1,所述隐藏状态为视频帧在空间存储中被压缩非重要矢量帧数,计算注意力向量et,公式如下:
16、
17、式中,i表示注意力自编码器处理的第i个视频片段,vi'表示注意力自编码器输出视频帧的转置,wa表示转置矩阵;
18、s2-2:注意力向量送入softmax层进行归一化:
19、
20、式中,exp表示以自然常数e为底的指数函数,表示注意力权重向量;
21、注意力向量与注意力自编码器的输出相乘,得到上下文向量,与前一帧的输出作为注意力自编码器新的输入,通过迭代增量叠加得到与原视频相近的重建视频;
22、s3:通过对抗学习,获得损失值、奖励值:
23、s3-1:演员模型进行片段随机选择,鉴别器获取原视频压缩特征序列x',生成器根据演员模型选择的视频片段重建得到的特征序列通过c-lstm网络(c-lstm[2]利用卷积神经网络(cnn)提取抽象的高级特征,并将其送入长短期记忆递归神经网络(lstm)中得到句子表示。最终通过全连接层来做分类任务[2]zhouc,sunc,liuz,etal.aclstmneuralnetworkfortextclassification[j].computers cience,2015,1(4):3944.doi:10.48550/arxiv.1511.08630)用于鉴别从lstm中解码得到的特征是否还是原来的特征,得到隐向量和根据隐向量之间欧氏距离计算损失值lreconst,公式如下:
24、
25、式中,||||2表示欧氏距离计算符号,lreconst表示生成器在对特征序列的重建过程中造成的信息损失;
26、s3-2:根据损失值计算奖励值并返回到评论家模型,公式如下:
27、ri=1-lreconst
28、
29、式中,ri表示奖励值,演员模型迭代计算损失值和奖励值,自动提升所述步骤s2和s1的性能,完成对抗过程。
30、优选方式下,当所述奖励值的计算在演员模型的采样选择了一个重复片段的特殊情况下,返回的奖励值为0,演员模型会重新进行片段选择。
31、优选方式下,原视频到视频摘要存在隐含的空间映射x=p(v),所述空间映射根据原视频中最具有代表性的特征生成视频摘要。
32、当该奖励值的计算在演员模型的采样选择了一个重复片段的特殊情况下,返回的奖励为0,演员会对重新选择刚才的动作,损失值和奖励值是对抗学习的重要方法,通过计算损失值可以自动集中优势样本,计算奖励值可以判断特定状态下动作的好坏。通过设计损失值和奖励值计算方法,通过对抗学习的持续迭代,可以自动提升修正步骤s2和s1的性能,最后生成对抗过程会持续进行,在一轮迭代后,本次步骤s3中鉴别器区分原始视频与重建视频的能力提升了,随后步骤s2中注意力自编码器根据摘要来还原原视频内容的能力也被提升了,在步骤s2中根据视频内容选择关键帧生成摘要的强化学习模型也在鉴别器给出的摘要质量分数下提升了选择关键帧的策略,最终实现了无监督环境下对强化学习模型进行视频摘要任务的训练过程,并在多轮迭代训练后能够得到生成摘要效果良好,摘要内容准确,代表性强的视频摘要模型,对抗学习算是一种通用技术,通过损失值和奖励值得计算,通过迭代自动完成性能提升,目前在机器学习方面对使用抗方法绝大多数就是用来提升性能的。
33、演员评论家模型是2000年在nips上发表的一篇名为actor-critic algorithms的论文中提出的,是一种策略(policybased)和价值(value based)相结合的方法,automaticavolume 45,issue 11,november2009,pages 2471-2482。所述演员评论家模型包含鉴别器和生成器,所述生成器用于重建视频序列,所述鉴别器用于识别视频的特征序列进行提取。
34、本发明的有益效果:与现有的技术相比,本发明通过强化学习模型对解决视频摘要问题具有的长期回报优势,有效地提取原视频中的重要镜头片段,可以充分概括原始视频内容,自动化地得到基于原视频内容跟生成得到的视频摘要,优化训练准备与训练过程,适应多种不同视频种类。本发明的方法可以应用于视频摘要领域。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197002.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表