一种基于信息熵的非线性自适应隐私预算划分方法
- 国知局
- 2024-07-31 23:22:23
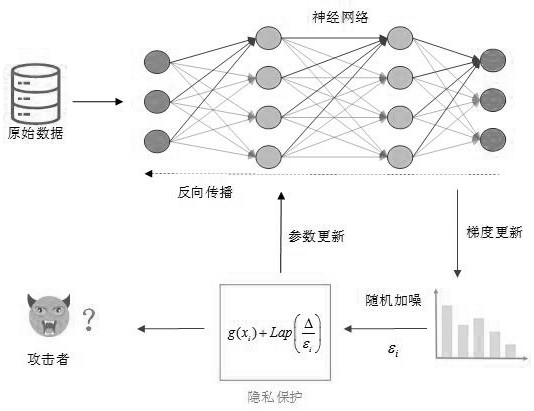
本发明属于信息安全,涉及隐私预算划分方法,具体涉及一种基于信息熵的非线性自适应隐私预算划分方法。
背景技术:
1、大数据环境下,深度学习、联邦学习等理论和技术的迅猛发展,为机器学习在多个领域的迅猛发展提供了坚实的数据和算法基础。其中,神经网络模型因其在训练过程中具备的强大适应性、特征学习能力以及非线性建模能力等优势,已成为解决各类复杂任务和大规模数据分析的重要工具。然而,大多数神经网络模型在设计时并未考虑到潜在的安全问题。虽然这些模型在处理复杂数据和执行任务上具有高度的效率和准确性,但在训练和推理过程中可能涉及到大量的敏感数据,如个人身份信息、生物识别信息、地理位置等,而未经适当保护的情况下,可能会导致隐私泄露和数据滥用,进而引发严重的隐私隐患。因此,如何在保证模型性能的同时有效保护用户隐私成为了当前亟待解决的问题。
2、基于神经网络梯度下降算法,现有技术中提出了各种隐私预算分配方法,通过构建自适应差分隐私保护模型来实现隐私预算的灵活分配以保护用户隐私,但现有的隐私预算自适应方案大多采用线性划分的方法。然而,在模型训练过程中梯度对损失函数的影响往往存在着一种非线性关系,即随着梯度的更新,损失函数先是快速下降,后逐渐变缓,最终趋于收敛。因此若采用简单的线性划分,将导致隐私预算的累积和不必要的损耗,影响模型训练效率和准确性,因此有必要继续优化隐私预算的差异化分配,提高模型的准确性。
技术实现思路
1、有鉴于此,为解决上述现有技术的不足,本发明的目的在于提供一种基于信息熵的非线性自适应隐私预算划分方法,采用信息熵对输入特征相关性进行隐私度量,设计满足损失函数变化趋势的隐私预算分配方法,解决现有模型训练时在梯度更新过程注入等量噪声导致模型准确性下降、预算分配难以满足损失函数随梯度的更新变化的问题。
2、为实现上述目的,本发明所采用的技术方案是:
3、一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,包括以下步骤:
4、步骤1、计算输入特征贡献度;
5、步骤2、通过信息熵计算每个输入特征贡献度的客观权重;
6、步骤3、引入隐私预算比,为每一个输入特征分配隐私预算;
7、步骤4、使用最小化损失函数的sgd优化算法训练学习模型,为特征梯度自适应地添加噪声。
8、进一步地,所述步骤1具体包括以下子步骤:
9、1.1)采用逐层相关性算法计算每一个输入特征对于模型输出的贡献度;
10、1.2)计算每一个输入特征的平均相关性,利用平均相关表示输入特征对输出的贡献度。
11、进一步地,所述步骤2具体包括以下子步骤:
12、2.1)计算每个输入特征的平均相关性占全部特征平均相关性的比例;
13、2.2)计算某个输入特征的信息熵值hj(d),对输入特征相关性进行隐私度量;
14、2.3)使信息熵值hj(d)∈[0,1],使每一个输入特征的信息熵标准化。
15、进一步地,所述步骤3具体包括以下子步骤:
16、3.1)计算每一个输入特征的隐私预算比αj;
17、3.2)根据隐私预算比对输入特征分配隐私预算。
18、进一步地,所述步骤4具体包括以下子步骤:
19、4.1)计算梯度g(xi);
20、4.2)更新模型参数,根据自适应梯度扰动算法进行梯度扰动,对输入特征的特征梯度自适应添加噪声。
21、更进一步地,所述步骤4.2中,所述自适应梯度扰动算法具体内容如下:
22、
23、其中,为拉普拉斯噪声,为扰动版梯度,ε隐私预算。
24、本发明的有益效果是:
25、本发明提供了一种非线性自适应隐私预算划分方法,通过计算输入特征的相关性量化不同输入特征对模型输出结果的影响,同时采用信息熵对输入特征相关性进行隐私度量以满足损失函数变化趋势,解决模型训练过程的线性隐私预算分配难以满足损失函数随梯度的更新先迅速降低、后逐渐减缓并趋于收敛的变化趋势的问题,达到隐私预算的非线性自适应分配,提高了隐私预算的利用率和模型训练的准确率;
26、根据逐层相关性计算输入特征的相关性,并通过信息熵对每一个特征的隐私预算比进行计算,为梯度自适应地添加噪声,解决现有模型训练的隐私保护方案在梯度更新过程中注入等量噪声导致模型准确性下降的问题;
27、本发明方法通过信息熵计算每个输入特征贡献度的客观权重,熵值越小包含的信息量越大,因此在模型训练过程中熵值小的特征会需要的隐私保护强度更大,即为其分配的隐私预算越小,利用信息熵作为输入特征贡献度权重的衡量方法,以达到隐私预算的非线性自适应分配。
技术特征:1.一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,所述步骤1具体包括以下子步骤:
3.根据权利要求2所述的一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,所述步骤2具体包括以下子步骤:
4.根据权利要求1所述的一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,所述步骤3具体包括以下子步骤:
5.根据权利要求1所述的一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,所述步骤4具体包括以下子步骤:
6.根据权利要求5所述的一种基于信息熵的非线性自适应隐私预算划分方法,其特征在于,所述自适应梯度扰动算法具体内容如下:
技术总结本发明公开了一种基于信息熵的非线性自适应隐私预算划分方法,首先根据逐层相关性计算输入特征的相关性,量化不同输入特征对模型输出结果的影响;然后采用信息熵对输入特征相关性进行隐私度量,根据度量结果进行隐私预算分配;最后使用最小化损失函数训练学习模型,为特征梯度自适应地添加噪声。本发明利用信息熵作为输入特征贡献度权重的衡量方法,以达到隐私预算的非线性自适应分配,提高了隐私预算的利用率和模型训练的准确率,为梯度自适应地添加噪声,解决现有模型训练的隐私保护方案在梯度更新过程中注入等量噪声导致模型准确性下降的问题。技术研发人员:张丽丽,张志勇,张东彦,张中亚,宋斌,李玉祥,向菲,赵长伟受保护的技术使用者:河南科技大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/197256.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。