对基于多模态大模型的智能体的任务数据进行处理的方法、系统与流程
- 国知局
- 2024-07-31 23:26:25
本发明涉及大模型应用,具体涉及对基于多模态大模型的智能体的任务数据进行处理的方法、计算机程序产品和企业问答系统。
背景技术:
1、通用的多模态大模型(mllm)能够处理和理解多种类型数据(如文本、图片、音频、视频等),在智能搜索、智能问答等任务处理领域被广泛关注。随着大模型技术的普及,以大模型为核心驱动的问答系统进入人们的视线。例如企业问答系统,其包含企业大模型和智能体两部分内容,其中:(1)企业大模型系以通用的多模态大模型为基础,用企业自身的各类数据进行微调训练形成,其能够精准识别并理解企业术语和专业词汇,能够完成与企业相关的特定任务,例如客户问答等;(2)智能体是连接企业大模型和企业应用流程的应用系统,基于智能体可以实现客户问答功能,该客户问答功能可以快速识别客户提出的问题并调用工具来提供应答信息。
2、在企业问答系统中,企业大模型不会长期记忆在问答过程中产生的问答数据,即企业大模型不会提取问答数据中的有效经验来实现大模型优化,只能通过人工整理问答数据来形成问答知识库,以该问答知识库对企业大模型进行微调优化。人工整理的效率低下,人工整理问答数据来形成问答知识库需要耗费大量的人力和时间。
技术实现思路
1、本发明的目的在于提出一种对基于多模态大模型的智能体的任务数据进行处理的方法、计算机程序产品以及企业问答系统,为问答数据整理形成问答知识库的工作提高效率。
2、为达到上述目的,本发明提供一种对基于多模态大模型的智能体的任务数据进行处理的方法,包括以下步骤:
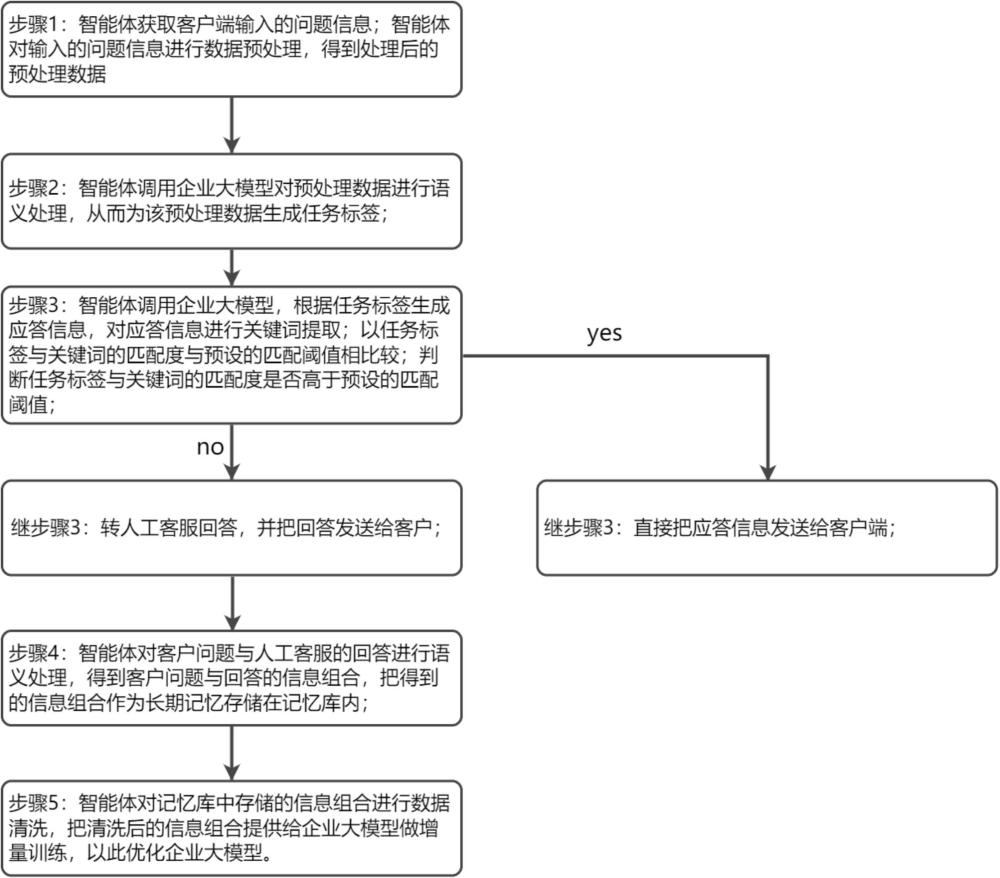
3、步骤1:智能体获取客户端输入的问题信息;智能体对输入的问题信息进行数据预处理,得到处理后的预处理数据;
4、步骤2:智能体调用企业大模型对预处理数据进行语义处理,从而为该预处理数据生成任务标签;
5、步骤3:智能体根据所述任务标签执行策略管理;
6、所述策略管理包括以下步骤:
7、智能体调用企业大模型,根据任务标签生成应答信息,对应答信息进行关键词提取;
8、以任务标签与关键词的匹配度与预设的匹配阈值相比较;
9、若匹配度高于预设的匹配阈值,则直接把应答信息发送给客户端;
10、若匹配度低于预设的匹配阈值,则转人工客服回答,并把回答发送给客户端;
11、还包括在人工客服回答之后执行的数据处理步骤4:智能体对客户问题与人工客服的回答进行语义处理,得到客户问题与回答的信息组合,把得到的信息组合作为长期记忆存储在记忆库内;
12、还包括执行完步骤4之后的步骤5:智能体对记忆库中存储的信息组合进行数据清洗,把清洗后的信息组合提供给企业大模型做增量训练,以此优化企业大模型。
13、优选地,步骤2中,智能体调用企业大模型对预处理数据进行语义处理,从而为该预处理数据生成任务标签,包括:
14、智能体采用企业大模型对预处理数据进行语义理解来识别客户的问题类别、用户情绪和问题的优先级,在识别问题类别的同时,还采用预训练的企业大模型识别客户输入中的命名实体;
15、智能体结合问题类别、用户情绪和问题的优先级和命名实体,生成任务标签。
16、优选地,步骤3中,智能体调用企业大模型,根据任务标签生成应答信息,对应答信息进行关键词提取,得到多个关键词之后,智能体还包括:
17、采用自然语言处理对多个关键词进行识别,得到对应的识别标签,将任务标签和所有识别标签用词袋模型或者tf-idf方法表示为向量形式;使用余弦相似度方法计算任务标签向量和每一个识别标签向量之间的相似度作为匹配度,并预设匹配阈值。
18、优选地,若至少一个匹配度高于预设的匹配阈值,则直接把应答信息发送给客户端;若所有匹配度低于预设的匹配阈值,则转人工客服回答,并把回答发送给客户端。
19、优选地,步骤4中,智能体对客户问题与人工客服的回答进行语义处理,得到客户问题与回答的信息组合,把得到的信息组合作为长期记忆存储在记忆库内,包括:
20、智能体采用自然语言处理技术对客户问题与人工客服的回答进行语义处理,得到客户问题与回答的信息组合,客户问题设为二级存储机制,一级目录为问题类别,二级目录为关键词,确定客户问题的二级目录后,把客户问题与对应回答的信息组合存储在二级目录下。
21、优选地,步骤5中,智能体对记忆库中存储的信息组合进行数据清洗,包括:
22、智能体调用记忆库中全部二级目录信息,识别各个二级目录分别存储的信息组合的数量x,对一级目录下的全部二级目录,若数量x的排序低于预设程度,则将该数量x对应的二级目录从记忆库中删除或标记为不可用状态。
23、优选地,所述数量x的排序低于预设程度是指:在一级目录下的全部二级目录的数量x中,该二级目录的数量x低于25%分位数。
24、优选地,把清洗后的信息组合提供给企业大模型做增量训练后清空记忆库。
25、本发明还提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上述的对基于多模态大模型的智能体的任务数据进行处理的方法的步骤。
26、本发明还提供一种企业问答系统,包括企业大模型、智能体和处理器,还包括计算机程序产品,该计算机程序产品的计算机程序可被处理器执行,计算机程序产品上述所述。
27、与现有技术相比,本发明实施例具有以下有益效果:
28、本发明的对基于多模态大模型的智能体的任务数据进行处理的方法,对人工客服与客户端问答过程中产生的问答数据进行语义处理,得到客户问题与回答的信息组合,智能体内预先存储有对信息组合进行数据清洗的策略,智能体自动执行记忆库的数据清洗策略,提高了整理问答数据来形成问答知识库的效率,智能体还把清理后的信息组合作为企业大模型的增量训练数据对企业大模型进行优化,提高了企业大模型的准确度。
技术特征:1.对基于多模态大模型的智能体的任务数据进行处理的方法,包括如下步骤:
2.根据权利要求1所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:步骤2中,智能体调用企业大模型对预处理数据进行语义处理,从而为该预处理数据生成任务标签,包括:
3.根据权利要求1所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:步骤3中,智能体调用企业大模型,根据任务标签生成应答信息,对应答信息进行关键词提取,得到多个关键词之后,智能体还包括:
4.根据权利要求3所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:
5.根据权利要求1所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:步骤4中,智能体对客户问题与人工客服的回答进行语义处理,得到客户问题与回答的信息组合,把得到的信息组合作为长期记忆存储在记忆库内,包括:
6.根据权利要求5所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:步骤5中,智能体对记忆库中存储的信息组合进行数据清洗,包括:
7.根据权利要求6所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是:所述数量x的排序低于预设程度是指:在一级目录下的全部二级目录的数量x中,该二级目录的数量x低于25%分位数。
8.根据权利要求1所述的对基于多模态大模型的智能体的任务数据进行处理的方法,其特征是,把清洗后的信息组合提供给企业大模型做增量训练后清空记忆库。
9.一种计算机程序产品,包括计算机程序,其特征是,该计算机程序被处理器执行时实现权利要求1至8任一项所述的对基于多模态大模型的智能体的任务数据进行处理的方法的步骤。
10.企业问答系统,包括企业大模型、智能体和处理器,还包括计算机程序产品,该计算机程序产品的计算机程序可被处理器执行,其特征是,计算机程序产品如权利要求9所述。
技术总结本发明涉及大模型应用技术领域,提供了一种对基于多模态大模型的智能体的任务数据进行处理的方法,智能体对人工客服与客户端问答过程中产生的问答数据进行语义处理,得到客户问题与回答的信息组合,智能体内预先存储有对信息组合进行数据清洗的策略,智能体自动执行记忆库的数据清洗策略,提高了整理问答数据来形成问答知识库的效率,智能体还把清理后的信息组合作为企业大模型的增量训练数据对企业大模型进行优化,提高了企业大模型的准确度。技术研发人员:高伟,王全胜,周小敏,林敏,张晓光受保护的技术使用者:广州信安数据有限公司技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/197565.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表