基于视觉上下文稀疏正则化与隐注意力的视频描述方法
- 国知局
- 2024-07-31 23:26:21
本发明涉及视频描述生成领域,尤其是涉及一种基于视觉上下文稀疏正则化与隐注意力的视频描述方法。
背景技术:
1、视频描述生成是一个复杂的过程,它旨在通过计算机算法来自动产生对视频内容的自然语言描述。目前在多数流行的工作中,视觉和语言特征被结合并表示在密集的多模态特征空间中,如专利申请cn113869324a公开的一种基于多模态融合的视频常识性知识推理实现方法,这使得模型只能学习到普遍的粗粒度类别特征而不是针对不同样本的独特性细粒度特征,同时模型在训练过程中易于陷入过拟合状态并损害模型的泛化能力。另一方面,模型直接从复杂且密集的多模态特征空间中进行学习,这会导致模型需要侧重于对视觉特征与语言特征之间的关联进行建模,而相对削弱模型在解码阶段中最终文本生成的能力,这使得模型生成的描述语句在词汇的正确率以及语句的整体流畅性等方面都受到较大影响。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的模型在训练和测试过程中对由视觉信息和语言语义组成的复杂多模态特征难以学习的缺点,而提供一种基于视觉上下文稀疏正则化与隐注意力的视频描述方法,以改善最终生成的视频标题句子的流畅度和准确度。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于视觉上下文稀疏正则化与隐注意力的视频描述方法,包括以下步骤:
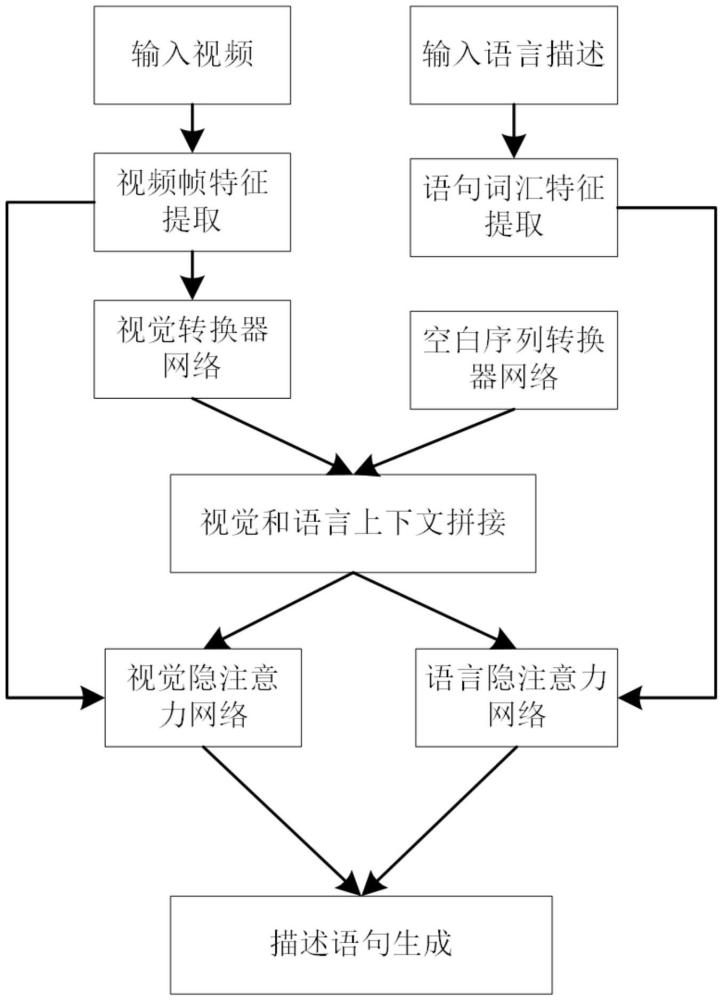
4、提取待描述视频的视觉特征和当前视频的所有人工标注文本语句的语言特征;
5、生成与当前待描述视频的所述人工标注文本语句长度对齐的空白填充序列,对所提取的视觉特征和空白填充序列进行编码,得到视觉上下文特征和伪文本上下文特征;
6、将所述伪文本上下文特征和视觉上下文特征沿序列长度方法拼接,得到稀疏正则化上下文特征;
7、将所述稀疏正则化视觉上下文特征、视觉特征和语言特征共同作为输入送入视频描述生成模型,通过所述视频描述生成模型获得每个当前时间步上的词汇概率输出,最终将所有生成的词汇按时间步顺序合并,获得当前待描述视频的最终描述语句,所述视频描述生成模型为视觉语言隐注意力双分支网络解码结构。
8、进一步地,通过在大规模图像和文本数据集上预训练获得的视觉转换器网络提取所述视觉特征。
9、进一步地,基于所有人工标注文本语句中每个标注词汇编码之后得到的嵌入式特征向量获得所述语言特征。
10、进一步地,所述视频描述生成模型包括均带有隐注意力机制的视觉隐注意力分支网络和语言隐注意力分支网络,所述隐注意力机制是指将所述稀疏正则化上下文特征分别与各分支网络中前续的隐藏状态结合并进行多模态语义对齐。
11、进一步地,所述视觉隐注意力分支网络以经隐注意力机制处理后的输出与视频特征的拼接特征为输入,所述语言隐注意力分支网络以经隐注意力机制处理后的输出与语言特征的拼接特征为输入。
12、进一步地,所述视觉隐注意力分支网络和语言隐注意力分支网络均基于长短时记忆网络构建。
13、进一步地,采用因子分解结构和非因子分解结构联合训练的方式对所述视频描述生成模型进行优化训练。
14、进一步地,在每个时间步上,所述视觉隐注意力分支网络和语言隐注意力分支网络分别输出各自的词汇概率分布,采用加权融合的方式获得最终的所述词汇概率输出。
15、进一步地,所述视觉特征通过视觉时空关联编码器生成所述视觉上下文特征,所述空白填充序列通过伪视觉特征编码器生成所述伪文本上下文特征。
16、进一步地,所述视觉时空关联编码器和伪视觉特征编码器均为带有多头自注意力机制的编码器。
17、与现有技术相比,本发明具有以下有益效果:
18、一、和目前流行的其他同类视频描述方法相比,本发明方法通过稀疏正则化的方式使模型避免从密集的模态特征中进行学习,并通过隐注意力机制对多模态特征进行语义上的关注与对齐,实现语义补偿,提高视频描述的准确性。
19、二、本发明为视频描述生成任务设计了视觉语言隐注意力双分支网络,成功地对来自不同模态的特征信息之间的关系进行建模,并且能挖掘出当前时间步下重要的部分特征,减少冗余信息的干扰,使得模型能够实现从视觉模态到语言模态的跨越。本发明通过加权平均的方式将两个分支的输出概率进行融合,利用更全面的信息,进一步提高生成句子的准确性和语义性。
20、三、多项实验证明本发明相比于其他同类其他模型取得了更好的性能,具体表现为能够生成更为准确、流畅、语义更为丰富的视频描述语句。
技术特征:1.一种基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,通过在大规模图像和文本数据集上预训练获得的视觉转换器网络提取所述视觉特征。
3.根据权利要求1所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,基于所有人工标注文本语句中每个标注词汇编码之后得到的嵌入式特征向量获得所述语言特征。
4.根据权利要求1所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,所述视频描述生成模型包括均带有隐注意力机制的视觉隐注意力分支网络和语言隐注意力分支网络,所述隐注意力机制是指将所述稀疏正则化上下文特征分别与各分支网络中前续的隐藏状态结合并进行多模态语义对齐。
5.根据权利要求4所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,所述视觉隐注意力分支网络以经隐注意力机制处理后的输出与视频特征的拼接特征为输入,所述语言隐注意力分支网络以经隐注意力机制处理后的输出与语言特征的拼接特征为输入。
6.根据权利要求4所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,所述视觉隐注意力分支网络和语言隐注意力分支网络均基于长短时记忆网络。
7.根据权利要求4所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,采用因子分解结构和非因子分解结构联合训练的方式对所述视频描述生成模型进行优化训练。
8.根据权利要求4所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,在每个时间步上,所述视觉隐注意力分支网络和语言隐注意力分支网络分别输出各自的词汇概率分布,采用加权融合的方式获得最终的所述词汇概率输出。
9.根据权利要求1所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,所述视觉特征通过视觉时空关联编码器生成所述视觉上下文特征,所述空白填充序列通过伪视觉特征编码器生成所述伪文本上下文特征。
10.根据权利要求9所述的基于视觉上下文稀疏正则化与隐注意力的视频描述方法,其特征在于,所述视觉时空关联编码器和伪视觉特征编码器均为带有多头自注意力机制的编码器。
技术总结本发明涉及一种基于视觉上下文稀疏正则化与隐注意力的视频描述方法,包括以下步骤:提取待描述视频的视觉特征和当前视频的所有人工标注文本语句的语言特征;生成空白填充序列,对所提取的视觉特征和空白填充序列进行编码,得到视觉上下文特征和伪文本上下文特征;将伪文本上下文特征和视觉上下文特征沿序列长度方法拼接,得到稀疏正则化上下文特征;将稀疏正则化视觉上下文特征、视觉特征和语言特征共同作为输入送入视频描述生成模型,获得每个当前时间步上的词汇概率输出,将所有生成的词汇按时间步顺序合并,获得当前待描述视频的最终描述语句。与现有技术相比,本发明生成的语言描述具有准确性高、语义丰富等优点。技术研发人员:汤鹏杰,张家钰,谭云兰受保护的技术使用者:井冈山大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/197556.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表