一种存算一体智能计算架构的模型预处理方法与流程
- 国知局
- 2024-07-31 23:26:59
本发明涉及存算一体智能计算架构,特别涉及一种存算一体智能计算架构的模型预处理方法。
背景技术:
1、近年来,人工智能迅猛发展。以神经网络为代表的人工智能算法属于计算和内存密集型任务,传统的cpu(处理器)中大部分硬件资源被用于通用控制而不是计算,因此无法为人工智能算法的部署提供足够的算力,而gpgpu(通用图形处理器)以牺牲通用控制性能为代价提供更多的计算资源,为人工智能算法提供了理想的部署平台。但gpgpu仍然属于冯诺依曼架构,其计算和存储是分离的,所以在gpgpu中,神经网络层间的数据传递必须经过存储器。随着gpgpu计算速度的提升,执行一次计算的耗时越来越小,这使得计算单元和存储器之间的数据交换耗时所占的比重不断增大,甚至超过了计算耗时,形成了内存约束(memory bound)。内存约束代表着存储器访问成为了计算的瓶颈,这时,单纯通过扩展计算单元规模已经难以实现算力的扩充。
2、为了根除内存约束,必须减少或避免计算单元和存储器间的数据移动,但在计算与存储分离的冯诺依曼架构中,存储器是无法被数据绕过的,所以需要走出冯诺依曼架构的范畴,探索将存储和计算融为一体的计算体系架构,即存算一体架构。在存算一体架构中,存储器被赋予计算的功能,因此存储器产生的数据能够实现当场计算,从而大幅减少甚至避免了计算时的数据移动、消除了内存约束。
3、目前的存算一体系统根据其基于的存内计算器件类型主要分为三类:sram(静态随机存储器)存算一体、dram(动态随机存储器)存算一体和nvm(non-volatile memory,非易失性存储器)存算一体。由于sram存储密度较低,sram存算一体难以实现大容量,不足以支撑规模较大的人工智能算法的部署。dram拥有极其复杂且封闭的硬件模型和协议栈,因此只有存储器厂商具备进行dram存算一体研究的条件。而nvm,如reram、mram、pcm、nor-flash,不仅拥有高存储密度,而且硬件模型简单统一、普适性强。此外,nvm还具有低功耗的优势。因此,如何设计nvm存算一体智能计算架构,实现高能效的人工智能算法部署平台,成为了一个开放且极具价值的研究课题。
4、在nvm存算一体智能计算架构中(下称存算一体智能计算架构),通常将多个计算单元(tile)组成一个计算阵列,计算阵列中设有专门的互连结构用于多个计算单元间的通信。在执行算法任务时,每个tile负责执行一部分矩阵乘法运算,多个tile之间能够以并行的方式执行计算,并依靠互连网络发送输入数据、传递运算结果,最终实现神经网络的前向推理过程。
5、在存算一体智能计算架构中,提升系统对预训练模型的支持性具有必要性。onnx(open neural network exchange)文件格式是当今业界通用的预训练模型存储方式之一,包括华为、英特尔、amd和高通在内的厂商都对该格式提供支持。因此,通过支持该格式的预训练模型,可极大地提升存算一体系统的兼容性、易用性。
6、然而,onnx模型需要进行一定转化才能映射到存算一体系统的各个tile中,并且存算一体系统并不支持模型中的部分运算操作。这需要开发一套算法,将模型中存算一体系统支持的运算高效操作地映射到tile中,并将其不支持的运算操作交由外部硬件处理。
技术实现思路
1、本发明的目的在于提供一种存算一体智能计算架构的模型预处理方法,旨在开发一种适配存算一体系统的转化方法,以实现该系统对onnx模型的适配。
2、为解决上述技术问题,本发明提供了一种存算一体智能计算架构的模型预处理方法,包括如下步骤:
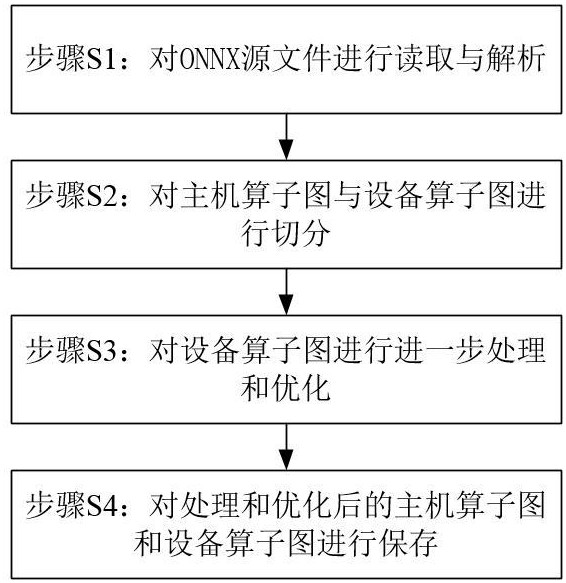
3、步骤s1:对onnx源文件进行读取与解析;即:读取onnx源文件之后,对其索引和各个节点进行遍历,检查是否存在存算一体系统完全不支持的sigmoid操作,并将各个节点的操作类型转化为对应的算子,记录节点的前驱和后继节点、以及边信息,然后对各个算子的操作类型进行分类为卷积、矩阵乘法和池化类型,并针对onnx源文件的模型中拼接类型的算子进行配置;
4、步骤s2:对主机算子图与设备算子图进行切分;即:通过深度优先搜索算法,寻找算子图中不适合由存算一体系统执行的操作,并在此操作处切分形成设备算子图与主机算子图;
5、步骤s3:对设备算子图进行进一步处理和优化;即:删除设备算子图中的冗余的主机算子图中的算子,然后根据onnx源文件的模型种类,通过融合设备算子图中的部分操作,进一步优化设备算子图在存算一体架构上的运行效率;
6、步骤s4:对处理和优化后的主机算子图和设备算子图进行保存。
7、优选的,所述onnx源文件包括:各个节点、数据流程图和模型中各个元素的索引;
8、其中,通过所述onnx源文件,将深度学习算法的计算图中每一个计算操作作为一个节点,算法中所有节点按照拓扑排序的方式构成了一个没有环的数据流图,节点与节点之间由边链接,边表示了不同节点之间的数据流动;
9、所述一个节点包括:名称、属性、调用的运算符、输入和输出元素;其中所述运算符指定了该节点的运算类型,所述运算类型包括relu和conv;输入、输出则规范了该节点的输入、输出节点信息;
10、所述索引包括:每个节点中各个运算符、输入和输出元素的编号和位置,以帮助定位和处理模型中的各个组件,便于访问模型的各个操作和中间结果。
11、优选的,所述步骤s1中对onnx源文件的模型中拼接类型的算子进行配置,具体包括:若一个算子为拼接类型,则需要按照给定的顺序配置该算子的输入,确保拼接按照原模型给定的顺序进行。
12、优选的,所述步骤s1还包括:对处理后的算子图进行简化,移除无用的算子,并对修改部分模型中不规范的卷积、池化算子进行规范化。
13、优选的,所述步骤s3中onnx源文件的模型种类包括:resnet、googlenet、vgg、yolov3和squeezenet模型。
14、优选的,当所述onnx源文件的模型种类为resnet类型时,对设备算子图进行整形,具体包括如下步骤:
15、(a)寻找设备算子图中的激活函数节点,将该激活函数节点与前驱节点融合,并将原激活函数节点到后继节点的边,更改为前驱节点到后继节点的边,然后删除该激活函数节点;
16、(b)寻找设备算子图中的池化函数节点,将该池化函数节点与前驱节点融合,并将原激活函数节点到后继节点的边,更改为前驱节点到后继节点的边,然后删除该池化函数节点;
17、(c)寻找设备算子图中的add操作节点,将该add操作节点与前驱节点融合,并将原激活函数节点到后继节点的边,更改为前驱节点到后继节点的边,然后删除该add操作节点;
18、(d)根据不同卷积层间的依赖关系,使用递归方法计算数据到达各层的时间。
19、优选的,所述onnx源文件为通用的预训练模型存储方式,支持linux、mac和windows操作系统,以及支持不同硬件架构读取模型和进行推理。
20、本发明与现有技术相比,具有如下有益效果:
21、1、本发明的该预处理方法实现了onnx预训练模型在存算一体平台的部署,极大地提高了存算一体平台对现有人工智能模型的适配性。
22、2、本发明的该预处理方法针对存算一体平台的特点,通过将部分节点融合的方式,进一步优化了onnx预训练模型在存算一体平台上的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197636.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表