一种Transformer嵌入式人工情感深度确定性策略梯度的多频段电力系统稳定器控制方法
- 国知局
- 2024-07-31 23:37:57
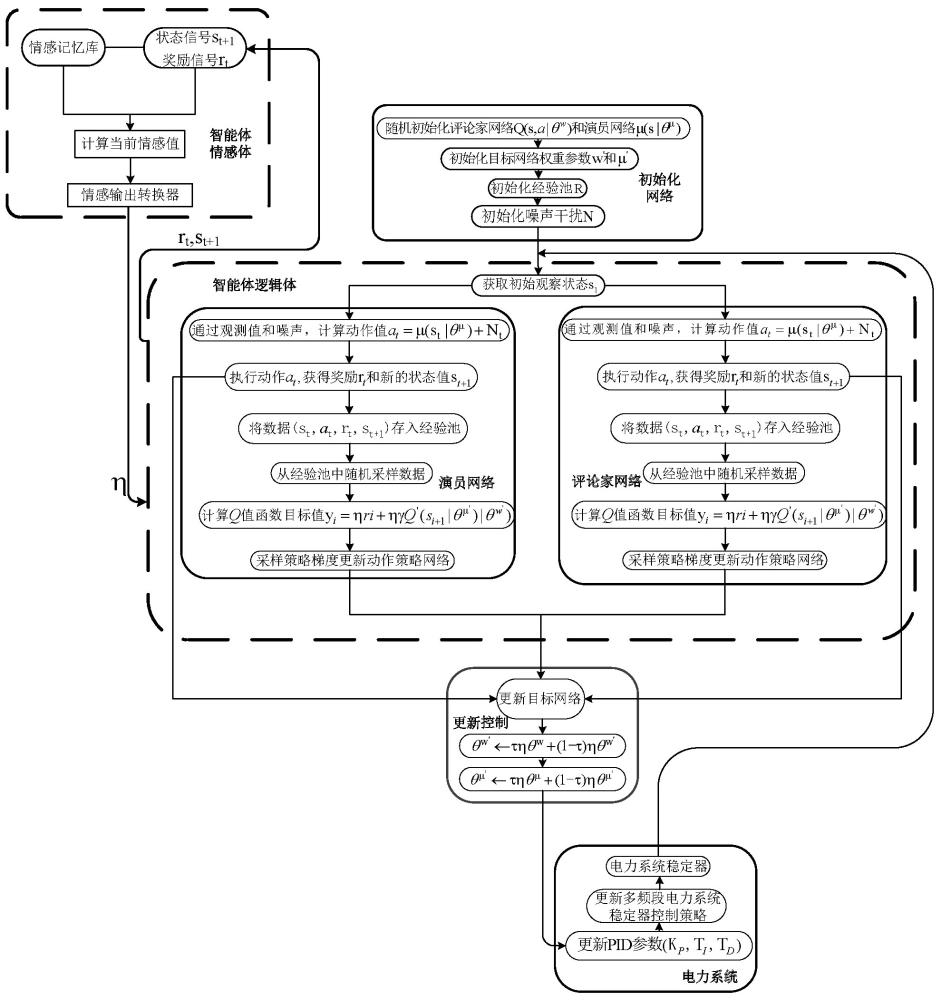
本发明属于电力系统稳定控制、人工心理学、深度强化学习、自然语言处理领域,涉及一种transformer嵌入式人工情感深度确定性策略梯度的控制方法,适用于电力系统多频段电力系统稳定器的控制。
背景技术:
1、现有深度确定性策略梯度方法,存在输入参数维度过低导致训练效果很差,导致电力系统稳定器控制精度低的问题。
2、另外,现有比例积分微分方法在系统运行工况发生变化时,控制参数无法及时更新,对电力系统稳定器的控制较差。
3、现有的强化学习方法存在智能体的训练速度过慢的问题。
4、因此,提出一种transformer嵌入式人工情感深度确定性策略梯度的方法,来解决深度确定性策略梯度方法输入参数维度低、比例积分微分方法无法及时更新参数、参数优化方法存在迭代次数过多导致陷入局部最优解、q学习方法存在智能体的训练速度过慢的问题。
技术实现思路
1、本发明提出一种transformer嵌入式人工情感深度确定性策略梯度的多频段电力系统稳定器控制方法,将人工情感和transformer嵌入式深度确定性策略梯度进行结合,用于多频段电力系统稳定器的控制,具有控制效率和精度提高、减小控制误差、实现自我整定和在线优化的功能,能够提高多频段电力系统稳定器控制精度;在使用过程中的步骤为:
2、步骤(1):深度确定性策略梯度网络中的智能体从电力系统中观测到多频段电力系统稳定器输出的角速度与设定的角速度的差值,即初始观察状态s1;
3、其中,s1是t=1时刻多频段电力系统稳定器输出的角速度与设定的角速度差值;
4、引入含自注意力机制的transformer模型能提高深度确定性策略梯度网络的输入维度,智能体能在电力系统中获取到更多的观测值,即角速度偏差、角速度偏差的微分和角速度偏差的积分;
5、transformer的输入矩阵x由多频段电力系统稳定器不同时刻角速度差值和不同时刻组成;不同时刻在矩阵中的位置由pe表示,计算公式为:
6、petime,2i=sin(time/100002i/d) (1)
7、petime,2i+1=cos(time/100002i/d) (2)
8、式中,time表示不同时刻,即∆k, ∆k+1,…,∆k+d-1; ∆k为第k个小时刻; ∆k+1为第k+1个小时刻; ∆k+d-1为第k+d-1个小时刻;d表示pe设定的维度值;2i表示偶数的维度,2i+1表示奇数维度;
9、将计算得到的pe矩阵与多频段电力系统稳定器不同时刻角速度差值矩阵相加,即得到k时刻角速度差值构成的矩阵,即transformer的输入矩阵x;
10、自注意力机制是transformer的核心,包含查询矩阵h,键值矩阵k和值矩阵v;
11、三个矩阵通过输入矩阵x和设定的线性变换矩阵wh,wk,wv进行线性变换得到;
12、查询矩阵h的线性变换为:
13、h=x × wh (3)
14、式中,h为查询矩阵;x为transformer的输入矩阵;wh为线性变换矩阵; ×为矩阵相乘;
15、键值矩阵k的线性变换为:
16、k=x × wk (4)
17、式中,k为键值矩阵; wk为线性变换矩阵;
18、值矩阵v的线性变换为:
19、v=x × wv (5)
20、式中,v为值矩阵; wv为线性变换矩阵;
21、计算得到h,k,v矩阵后,自注意力机制的输出矩阵attention(x)为:
22、attention(x)=attention(h, k, v)=softmax(hkt/sqrt(dk))v (6)
23、式中,kt为键值矩阵的转置矩阵; dk为k矩阵的列数,即为向量维度;sqrt(dk)为dk的算术平方根; softmax( )是softmax激活函数;
24、通过编码器能让输入矩阵x在计算过程中将计算获得的参数与上一次计算获得的参数进行线性相加,提高输入参数的维度; 编码器的输出为:
25、layernorm(x+attention(x)) (7)
26、其中,layernorm( )为编码器的输出函数,即层归一化输出函数; attention(x)为输入矩阵x通过注意力机制后输出的矩阵;
27、智能体通过layernorm输出矩阵获得到多频段电力系统稳定器输出的角速度和设定的角速度差值的微分和积分后,智能体经过计算得出动作值为:
28、at=µ(st|θµ)+nt (8)
29、式中,at是t时刻智能体采取的动作,为[kp,ti,td]; kp为比例积分微分控制器的比例常数;ti为比例积分微分控制器的积分时间常数;td为比例积分微分控制器的微分时间常数; nt是t时刻设置的噪声函数; st是t时刻的智能体状态,即t时刻多频段电力系统稳定器输出的角速度与设定的角速度差值; θµ是深度策略梯度网络在µ权重参数下的深度确定性策略梯度网络中的评论家网络参数; µ(st|θµ)是在µ权重参数θ参数下并通过状态st获得的µ函数;
30、智能体在训练过程中通过观测值、动作值和奖励值进行学习策略的更新,然后对比例积分微分控制器参数[kp,ti,td]进行更新,但更新速度很慢;
31、通过将人工情感与深度策略性策略梯度网络结合,能提高智能体的学习效率,加快对比例积分微分控制器参数的更新;
32、通过人工情感与深度确定性策略梯度法结合,能在深度确定性策略梯度法的动作值、q值矩阵和奖励值三个方面进行情感更新,能提高深度确定性策略梯度网络的训练速度,提高比例积分微分控制器的控制精度,提高对多频段电力系统稳定器的稳定控制;
33、智能体的人工情感量化值fn为:
34、fn=sum(i=1,n, φiξi) (9)
35、式中,sum(i=1,n, φiξi)是从i=1到i=n对φiξi的求和; φi为人工情感感知得到的信息,即多频段电力系统稳定器输出的角速度和设定的角速度的差值; ξi为角速度差值的权重,0≤ξi≤1;fn为角速度差值和角速度差值权重的乘积的累加和;人工情感能采用一次输出、二次输出和指数输出三种方法进行转换输出;
36、人工情感一次输出转换为:
37、η=aηfn+bη (10)
38、式中,aη为人工情感量化器的一次因子;bη为人工情感量化器的常数因子;
39、人工情感二次输出转换为:
40、η=cηfn2+dηfn+eη (11)
41、式中,cη为人工情感量化器的二次因子; dη为人工情感量化器的一次因子;eη为人工情感量化器的常数因子;
42、人工情感指数输出转换为:
43、η=gηexp(hηfn)+kη (12)
44、式中,gη为人工情感量化器的指数因子; hη为人工情感量化器的一次因子;kη为人工情感量化器的常数因子;exp()为以自然常数为底数的指数函数;
45、智能体情感体与智能体逻辑体进行交互,产生情感因子η对深度确定性策略梯度网络中的策略和q值函数进行情感化更新;
46、将人工情感作用于智能体采取动作的策略为:
47、πθ←ηπθ (13)
48、式中,η为情感因子,0≤η≤1; πθ为在θ参数下取得策略;
49、将人工情感作用于智能体学习率的策略为:
50、α←ηα (14)
51、式中,α为设定的智能体学习率;
52、将人工情感作用于奖励函数的策略,智能体在状态st下的奖励值为:
53、r(st,st+1,at)←ηr(st,st+1,at) (15)
54、式中,r()为奖励函数; st+1为t+1时刻的状态,即t+1时刻多频段电力系统稳定器输出的角速度与设定的角速度差值;
55、深度确定性策略梯度网络包含2个神经网络用于对q值函数的近似表示;评论家目标网络用于近似估计下一个时刻的状态-动作的q值函数qw,next(st+1,πθ,next(st+1));下一动作值是通过演员目标网络近似估计得到t+1时刻权重参数θ,next下采取的策略πθ,next(st+1);通过q值函数、下一状态值和情感因子η得到当前状态下q值函数的目标值:
56、yt=ηrt+ηγqw,next(st+1,πθ,next(st+1)) (16)
57、式中,yt是t时刻的q值函数目标值; yt+1是t+1时刻的q值函数目标值;rt是t时刻的奖励; γ是设定的奖励函数折扣因子; qw是当前时刻的q值函数; qw,next是下一时刻的q值函数;
58、评论家策略网络输出当前时刻状态-动作的q值函数qw(st,at)用于对当前策略的评价;评论家策略网络的目标为:
59、yt-qw(st,at) (17)
60、深度确定性策略梯度法通过最小化损失值来更新评论家策略网络参数;评论家策略网络更新时的损失函数为:
61、loss=sum(t=1,n, (yt- qw(st,at))2)/n (18)
62、式中,loss是损失函数值;sum(t=1,n, (yt- qw(st,at))2)是从t=1到t=n对(yt- qw(st,at))2的求和; ( )2是平方;
63、演员目标网络用于提供下一个状态的策略;演员策略网络是提供当前状态的策略并结合评论家策略网络的q值函数得到演员策略网络更新的策略梯度:
64、∇πθ j= sum(t=1,n, ∇at qw(st,at)∇θπθ(st))/n (19)
65、式中,∇πθ j是在θ参数下采取策略πθ的梯度j; ∇at是t时刻采取动作a的梯度;∇θ是在参数θ下的梯度; πθ(st)是t时刻在参数θ下获得的状态下采取的策略;
66、对于演员和评论家目标网络参数wnext和θnext的更新,深度确定性策略梯度法通过软更新机制保证参数缓慢更新,同时通过人工情感参数因子η保证更新速度:
67、wnext←τηw+(1-τ) ηwnext (20)
68、θnext←τηθ+(1-τ) η θnext (21)
69、式中,w是更新前的评论家目标网络参数; wnext是更新后的评论家目标网络参数;θ是更新前的演员目标网络参数; θnext是更新后的演员目标网络参数; τ是更新权重参数,0≤τ≤1;
70、步骤(2):将经过transformer提高深度确定性策略梯度网络输入参数,并将人工情感优化深度确定性策略梯度法中的q值函数和策略的输出应用于比例积分微分控制器参数[kp,ti,td]的更新;
71、步骤(3):将更新整定参数后的比例积分微分控制器作用于多频段电力系统稳定器的控制,为:
72、uk=kp(mk+integral(k=0,k, mk)/ti+td×differential(mk,k)) (22)
73、式中,uk为比例积分微分控制器对多频段电力系统稳定器的控制策略; mk为多频段电力系统稳定器输出角速度与设定角速度的差值; integral(k=0,k, mk)为mk从k=0到k=k的积分; differential(mk,k)为mk对k的微分。
74、所述的多频段电力系统稳定器作为电力系统的稳定控制环节,拥有3个频段,分别为低频段0.04~0.1hz,中频段0.1~1hz,高频段1~4hz;
75、多频段电力系统稳定器根据系统运行频段的频率范围选择对应的频段,频率在0.04~0.1hz选择低频段,频率在0.1~1hz选择中频段,频率在1~4hz选择高频段,并通过调整时间常数和不同频段增益达到所需频段特性;多频段电力系统稳定器的低频段传递函数为:
76、vpss=ka(ztω)(1+zta1)(1+zta3)/(1+ztω)/(1+zta2)/(1+zta4)∆ω (23)
77、式中,vpss为多频段电力系统稳定器的输出电压;∆ω为多频段电力系统稳定器的输入角速度偏差;ka为低频段增益常数;tω为隔直时间常数;ta1和ta3为超前时间常数;ta2和ta4为滞后时间常数;z为拉普拉斯变换中的拉普拉斯变量;
78、多频段电力系统稳定器由中心频率滤波环节、两级超前/滞后环节、频段增益环节和总增益环节四个环节组成,各频段中心滤波器参数设置满足在中心频率处增益最大且相位为零,三个频段对称;多频段电力系统稳定器低频段的超前时间常数为:
79、tl2=tl7=0.5πflsqrt(m) (24)
80、式中,tl2和tl7为低频段超前时间常数;π为圆周率;fl为中心频率;m为低频段比例系数;
81、多频段电力系统稳定器低频段的滞后时间常数为:
82、tl1=tl2/m (25)
83、tl8=tl7m (26)
84、式中,tl1和tl8为滞后时间常数;
85、多频段电力系统稳定器低频段的比例系数为:
86、kl1=kl2=(m2+m)/(m-1)2 (27)
87、式中,kl1为低频段中心频率比例系数;kl2为低频段中心频率比例系数。
88、所述的智能体在使用前需要对深度确定性策略梯度网络进行初始化;
89、初始化深度确定性策略梯度法网络初始化评论家网络q(st, at|θw)和演员网络µ(st|θµ); θ为深度确定性策略网络参数; θw是在w权重参数下的演员动作网络参数; q(st,at|θw)是在w权重参数、θ参数下通过状态st和动作at所获得q值函数;
90、初始化目标网络权重参数wnext和µnext; wnext是初始化后的w权重参数; µnext是初始化后的µ权重参数;
91、初始化经验池r和噪声干扰n; r是储存状态s、动作a和奖励r的经验池;n为设定的噪声函数;
92、智能体执行动作at,获取奖励rt和环境状态st+1,将(at, rt, st, st+1)存入r中;rt为t时刻获得的奖励,即多频段电力系统稳定器有更高的控制精度。
93、本发明相对于现有技术具有如下的优点及效果:
94、(1) 现有深度确定性策略梯度方法有输入参数维度过低导致训练效果很差,导致电力系统稳定器控制精度低的问题。而本发明能通过transformer与深度确定性策略梯度网络结合解决这个缺点,能提高深度确定性策略梯度网络的输入参数维度。
95、(2) 现有比例积分微分方法在系统参数发生变化时,所控制的效果比较差。而本发明能通过深度强化学习方法给出的策略是,随着环境动作而变化的在线学习的能够应对系统结构与参数发生的变化。
96、(3) 现有强化方法有智能体训练速度过慢的问题。而本发明通过与人工情感方法的结合,能够避免强化学习方法的这个缺点,提高了智能体的训练速度。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197996.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表