单bit权重产生单元、多bit权重产生单元、阵列组及计算宏
- 国知局
- 2024-07-31 19:22:18
本发明涉及动态随机存取存储,更具体的,涉及一种单bit权重产生单元、由4个该单bit权重产生单元组成的多bit权重产生单元、由多bit权重产生单元阵列分布组成的阵列组、以及存内计算宏。
背景技术:
1、随着“算力时代”到来,大规模数据需要在存储器和处理器之间往返,然而传统冯·诺依曼架构中计算单元与存储单元分离,数据频繁访问会消耗大量的功耗与时间。存内计算(cim)技术的诞生突破了冯·诺依曼瓶颈,打破了传统计算架构中的“存储墙”问题,因此对于“算力时代”具有革命性意义。由于sram读取数据的速度快且与先进逻辑工艺具有较好的兼容性,因此基于sram的存内计算具有很大的发展前景。
2、从图像分类到语音识别,机器学习已经推动了人工智能(artificialintelligence,ai)的广泛应用。尽管云计算为ai训练和计算提供了强大的算力支持,但这是依赖于用户的个人数据进行的,许多用户不愿意将个人数据发送到云端来重新训练模型;同时边缘端的应用需要实时网络连接,离开网络边缘设备无法实时执行重新训练,以应对现场遇到的新情况。基于这些因素,边缘设备学习(或芯片上训练)是一种优选的方法。也就是说,将训练芯片和推理芯片结合为一个整体,芯片在进行一阶段推理操作之后可以对样本进行增量学习,通过更新知识库、学习用户特有的特征来个性化模型以及减轻与隐私相关的担忧,来促进现有模型的训练。
3、但现有的芯片电路设计大部分还是停留在推理阶段,并没有实现与训练的整合。而已有的推理-训练芯片在推理、训练过程都采用相同bit的位宽,这样就会出现在推理操作时速度减慢、后向传播精确度降低的情况。
技术实现思路
1、基于此,有必要针对现有的推理-训练芯片在推理操作时出现速度减慢、后向传播精确度降低的问题,提供单bit权重产生单元、多bit权重产生单元、阵列组及计算宏。
2、本发明采用以下技术方案实现:
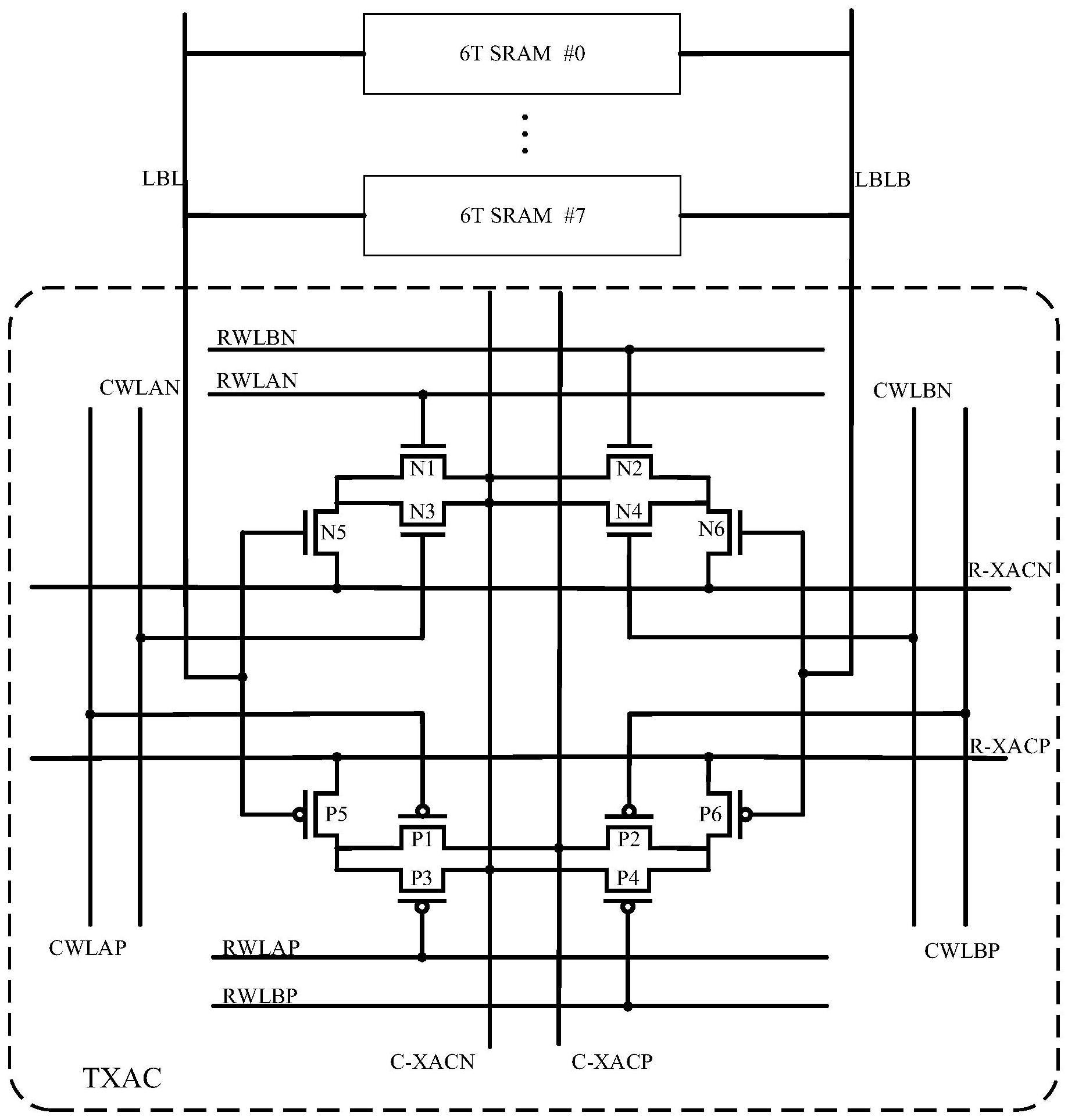
3、第一方面,本发明公开了一种单bit权重产生单元,包括n个标准6t-sram单元、1个转置xnor累加单元。
4、n个标准6t-sram单元作为存储单元;其中,任一个标准6t-sram单元的读取由其字线wl控制,并将其存储的权重值反映在其bl、blb上。n个标准6t-sram单元的位线bl共同连接到局部位线lbl,n个标准6t-sram单元的位线blb共同连接到局部位线lblb;n≥1。
5、1个转置xnor累加单元作为计算单元。转置xnor累加单元包括:nmos晶体管n1~n6、pmos晶体管p1~p6。其中,n1的漏端连接到信号线c-xacn,栅极接到控制信号rwlan。n2的漏端连接到c-xacn,栅极接到控制信号rwlbn。n3的漏端连接n1的源端,栅极接到控制信号cwlan,源端连接到c-xacn。n4的漏端连接n2的源端,栅极接到控制信号cwlbn,源端连接到c-xacn。n5的漏端连接n1的源端、n3的漏端,栅极连接到lbl,源端连接到信号线r-xacn。n6的漏端连接n2的源端、n4的漏端,栅极连接到lblb,源端连接到r-xacn。p1的栅极连接到控制信号cwlap,源端连接到信号线c-xacp。p2的栅极连接到控制信号cwlbp,源端连接到c-xacp。p3的漏端连接到c-xacn,栅极接到控制信号rwlap,源端连接p1的漏端。p4的漏端连接到c-xacn,栅极接到控制信号rwlbp,源端连接p2的漏端。p5的漏端连接到p1的漏端、p3的源端,栅极连接到lbl,源极连接到信号线r-xacp。p6的漏端连接到p2的漏端、p4的源端,栅极连接到lblb,源极连接到r-xacp。
6、该种单bit权重产生单元的实现根据本公开的实施例的方法或过程。
7、第二方面,本发明公开了一种多bit权重产生单元,包括4个如第一方面公开的单bit权重产生单元。
8、4个单bit权重产生单元处于同一行,共用同一条rwlan、同一条rwlbn、同一条rwlap、同一条rwlbp、同一条cwlap、同一条cwlbp、同一条cwlan、同一条cwlbn。同一行的4个单bit权重产生单元中,每个单bit权重产生单元的第m个标准6t-sram单元共用同一条wl,m∈[1,n]。
9、该种多bit权重产生单元的实现根据本公开的实施例的方法或过程。
10、第三方面,本发明公开了一种阵列组,包括n×n个、呈阵列分布的第二方面公开的多bit权重产生单元;n=2i,i>0。
11、其中,位于同一列的多bit权重产生单元共用同一条cwlap、同一条cwlbp、同一条cwlan、同一条cwlbn。同一列的n个多bit权重产生单元中,每个多bit权重产生单元的第q个单bit权重产生单元共用同一条c-xacn、同一条c-xacp;q∈[1,4]。位于同一行的多bit权重产生单元共用同一条rwlan、同一条rwlbn、同一条rwlap、同一条rwlbp。同一行的n个多bit权重产生单元中,每个多bit权重产生单元的第q个单bit权重产生单元共用同一条r-xacn、同一条r-xacp。
12、该种阵列组的实现根据本公开的实施例的方法或过程。
13、第四方面,本发明公开了一种存内计算宏,包括第三方面公开的阵列组、字线驱动器、后向通道输入驱动器、前向位线输入器、前向通道输入驱动器、后向位线输入器、存内计算控制器、闪存模数转换器、逐次逼近模数转换器、时序控制器。
14、阵列组用于进行前向传播或后向传播。字线驱动器用于控制wl开关。后向通道输入驱动器用于控制cwlan、cwlap、cwlbn、cwlbp开关。前向位线输入器用于在前向传播时将c-xacn预充到vdd/2,在后向传播时将c-xacn接vss、c-xacp接vdd。前向通道输入驱动控制器用于控制rwlan、rwlap、rwlbn、rwlbp开关。后向位线输入控制器,其用于在后向传播时将r-xacn预充到vdd、r-xacp预充到vss。后向位线输入器用于在后向传播时将r-xacn预充到vdd、r-xacp预充到vss。存内计算控制器用于切换阵列组的功能。闪存模数转换器用于在前向传播时得到4bit输出。逐次逼近模数转换器用于在后向传播时得到8bit输出。时序控制器用于控制各信号的时钟脉冲。
15、该种存内计算宏的实现根据本公开的实施例的方法或过程。
16、与现有技术相比,本发明具备如下有益效果:
17、1,本发明根据推理和训练操作的特点,分别制定了不同的量化方案,实现了整合,对芯片资源实现了有效的利用。
18、2,本发明相较于现有的4bit输入、4bit输出电路结构,精确度有明显提升,并达到了与现有的8bit输入、8bit输出电路结构相近的水平;并且本发明的能耗比相较于也得到了提升。
技术特征:1.一种单bit权重产生单元,其特征在于,包括:
2.根据权利要求1所述的单bit权重产生单元,其特征在于,n=8。
3.根据权利要求1所述的单bit权重产生单元,其特征在于,
4.根据权利要求1所述的单bit权重产生单元,其特征在于,
5.根据权利要求1所述的单bit权重产生单元,其特征在于,
6.根据权利要求1所述的单bit权重产生单元,其特征在于,
7.一种多bit权重产生单元,其特征在于,所述多bit权重产生单元包括4个如权利要求1-6中任一项所述的单bit权重产生单元;
8.一种阵列组,其特征在于,包括n×n个、呈阵列分布的如权利要求7所述的多bit权重产生单元;n=2i,i>0;
9.根据权利要求8所述的阵列组,其特征在于,
10.一种存内计算宏,其特征在于,包括:
技术总结本发明涉及动态随机存取存储技术领域,具体涉及单bit权重产生单元、多bit权重产生单元、阵列组及计算宏。本发明的单bit权重产生单元包括n个标准6T‑SRAM单元和1个转置XNOR累加单元,将转置XNOR累加单元作为计算单元,并外接在标准6T‑SRAM上,进而实现多bit同或累加的推理和训练操作。本发明的多bit权重产生单元由4个单bit权重产生单元组成,阵列组由阵列分布的多bit权重产生单元组成、存内计算宏基于阵列组构建。本发明根据推理和训练操作的特点,制定了不同的量化方案,实现整合,对芯片资源进行有效的利用,解决了现有的推理‑训练芯片在推理操作时出现速度减慢、后向传播精确度降低的问题。技术研发人员:卢文娟,张宇龙,刘玉,彭春雨,戴成虎,郝礼才,李鑫,蔺智挺,吴秀龙受保护的技术使用者:安徽大学技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240731/182445.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。