一种基于DQN和CNN的高速公路自动驾驶专用道车辆汇入方法
- 国知局
- 2024-07-31 20:18:24
本发明属于自动驾驶,特别涉及了一种面向高速公路的自动驾驶专用车道汇入方法。
背景技术:
1、随着无线通信、人工智能、大数据等高新技术的飞速发展,自动驾驶技术的出现和兴起为实现道路交通系统运行安全性、高效性和可靠性提供了重要的解决方法。然而,自动驾驶技术、相关配套设施、相关法律法规等仍需要久远持续地迭代更新,自动驾驶车辆的完全普及也需要经过漫长的过程,因此道路交通系统必然会经历一个人工驾驶车辆和自动驾驶车辆混行的过渡期,两种类型车辆的混行也必然会带来一定的安全隐患。
2、高速公路自动驾驶专用车道的设立可以为自动驾驶车辆提供更安全纯净的行车环境,在减少交通事故、提升道路通行能力、优化车头时距等方面发挥积极的作用。因此,研究自动驾驶车辆如何换道汇入专用道、如何提升换道效率和减少换道事故等问题具有较大的实际价值。目前不少学者借鉴了高速公路合流区匝道交通信号管控的方案,例如汇入线性控制、道路占有率控制、需求容量差控制等方法。这些方法可以有效解决频发性交通拥堵,但需要依赖先验知识和面临模型参数调整的难题,无法较好地适应高速公路系统随机性、时变性、非线性的特点,缺少对实时交通流信息的及时反馈,甚至会导致交通管控异常,具有一定的局限性。
技术实现思路
1、发明目的:为了解决上述技术问题,本发明提出了一种基于深度q网络(deep q-network,dqn)和卷积神经网络(convolutional neural network,cnn)的高速公路自动驾驶专用道车辆汇入方法,能够对实时交通流信息的及时反馈,提高自动驾驶车辆汇入专用道时的安全性和高效性,较好地适应高速公路系统随机性、非线性和时变性等特点。
2、技术方案:为了实现上述技术目的,本发明的技术方案为:
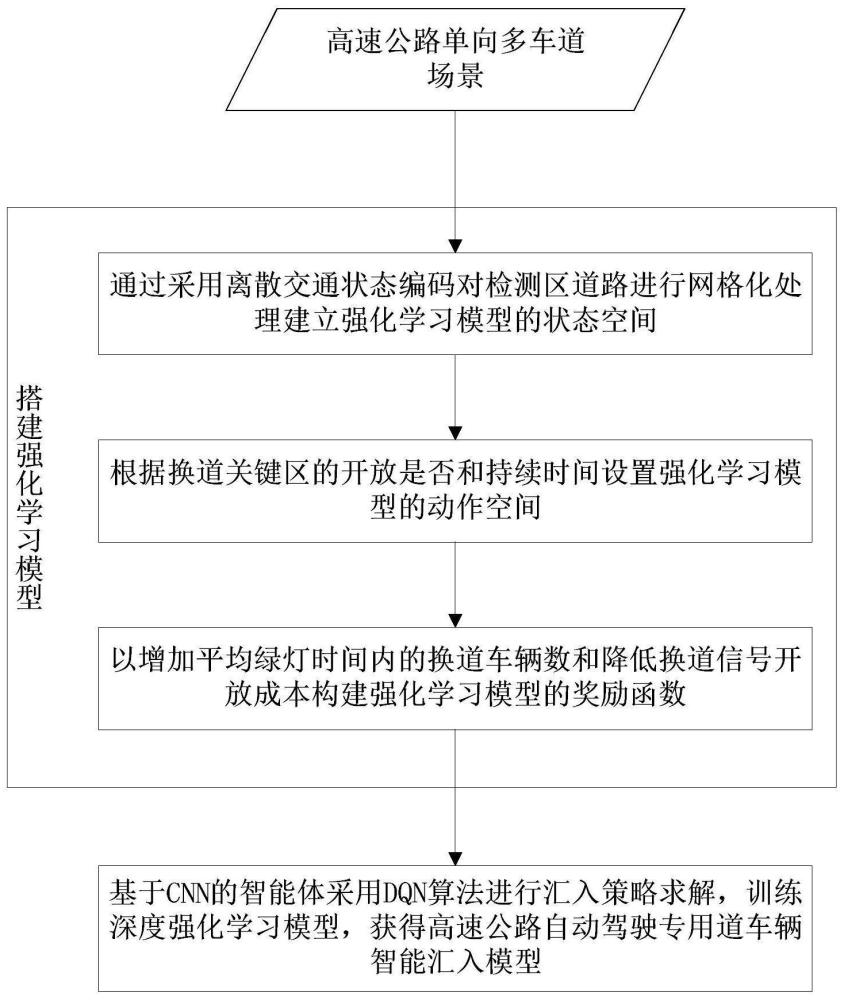
3、一种基于dqn和cnn的高速公路自动驾驶专用道车辆汇入方法,包括以下步骤:依据高速公路单向多车道场景搭建强化学习模型,通过采用离散交通状态编码对检测区道路进行网格化处理建立强化学习模型的状态空间,根据从混行车道至自动驾驶专用道的换道关键区的开放是否和持续时间设置强化学习模型的动作空间,以增加平均绿灯时间内的换道车辆数和降低换道信号开放成本构建强化学习模型的奖励函数;
4、基于cnn的智能体采用dqn算法进行汇入策略求解,训练深度强化学习模型,获得高速公路自动驾驶专用道车辆智能汇入模型。
5、作为优选,所述高速公路单向多车道场景中至少包括一个自动驾驶专用道和一个支持自动驾驶车辆和人工驾驶车辆混合行驶的混行车道;在路侧设置自动驾驶专用道入口距离标志、专用道汇入信号灯、禁止超车标志,设计检测区和换道区。
6、作为优选,所述检测区用于监测车辆速度和位置信息,以支持于自动驾驶车辆换道交通信号控制方案的确定;所述换道区用于向自动驾驶车辆传输交通信号控制和是否可换道指令,长度为:其中,lh为缓冲距离,n为变换车道的次数,v0为车辆到达换道区的速度,t0为车辆完成一次换道所需时间;在换道区尾端设有交通信号灯,当信号为绿灯时自动驾驶车辆被允许换道至专用道,当信号为红灯时自动驾驶车辆被禁止换道至专用道。
7、作为优选,所述深度强化学习模型在仿真环境中进行训练,仿真环境中,人工驾驶车辆采用元胞自动机中的三相交通流模型kkw进行换道控制和跟驰控制;自动驾驶车辆采用kkw模型进行换道控制,采用自适应巡航控制acc或协同式自适应巡航控制cacc进行跟驰控制。
8、作为优选,搭建基于dqn-cnn的深度强化学习模型,具体包括:
9、建立状态空间s:采用离散交通状态编码对检测区道路进行网格化处理,设置网格长度和宽度分别为车辆长度llen和车辆宽度lwid,将生成的位置矩阵作为状态空间的输入φ(st),大小为1×[ldet/llen]×[llane×n/lwid],ldet为检测区长度,llane为车道宽度,n为主线车道数;采用矩阵中的每个元素来描述道路交通状态,以车辆中心点落在网格表示对该网格的占用;
10、设置动作空间a:根据换道关键区的开放是否和持续时间将动作空间设置为a={a1,a2},其中动作空间a1表示换道区交通信号显示为红灯,动作空间a2表示换道区交通信号显示为绿灯,智能体在每个动作完成后再选择执行下一个动作;
11、构建奖励函数r:奖励函数考虑增加平均绿灯时间内的换道车辆数和降低换道信号开放成本,即:
12、
13、其中,为换道信号开放成本,nc为绿灯时间内成功换道至自动驾驶专用道的车辆数,δt1为前一个绿灯持续时间。
14、作为优选,所述强化学习模型基于贪心策略进行动作选择,在每次迭代时产生随机数,若随机数小于阈值ε则采取随机探索策略,若随机数大于ε则根据q表选择使得q值最大的动作。
15、作为优选,所述基于cnn的智能体结构,包括两层卷积层、一层激励层、一层池化层、一层全连接层,输入状态空间矩阵,输出q表;通过dqn算法以目标q值和实际q值之间的时序差分误差更新神经网络的权重参数。
16、作为优选,采用优先经验回放机制,训练基于dqn-cnn的深度强化学习模型,具体包括:
17、初始化样本数为npool的经验回放池d和神经网络权重参数θ,将φ(st)作为当前值网络的输入,通过ε-greedy策略选择动作at,得到下一时刻交通状态st+1和奖励rt+1,将(st,at,st+1,rt+1)存储在经验回放池中;
18、在经验回放池中选取nbatch个样本用于调参,时序差分误差δt计算方式为:
19、δt=rt+1+γmaxq(φ(st+1),at+1;θ′)-q(φ(st),at;θt)
20、其中,γ为折扣因子,q(φ(st+1),at+1;θ′)为目标网络的q值估计,at+1为下一时刻的动作,θ′为下一时刻神经网络的参数,q(φ(st),at;θt)为当前q网络的q值估计,st为当前时刻的状态,θt当前时刻神经网络的参数;
21、采用自适应时刻估计梯度下降法优化神经网络权重参数θ;
22、采用优先经验回放机制,每个样本采样的概率为:
23、
24、其中,ρ1为正数,|δi|为第i个样本的时序差分误差的绝对值,k为经验池中的样本数,为第i个样本经验回放的优先级;
25、引入重要性采样权重修正损失函数来计算每个样本的采样权重ωj:
26、
27、其中,n为经验回放缓冲区中样本总数,p(j)为第j个样本被选中的概率,β为控制权重调整的超参数。
28、有益效果:本发明通过一种基于dqn和cnn的高速公路自动驾驶专用道车辆汇入方法,使得高速公路中的自动驾驶车辆能够安全、高效地汇入自动驾驶专用道。与现有技术相比,具有如下优点:1、本发明建立基于cnn-dqn的深度强化学习模型,利用其“自学习、无模型、数据驱动”的特点可以解决传统管控方案依赖先验知识和参数调整的难题,较好地适应高速公路系统随机性、非线性和时变性等特点;2、本发明通过设计检测区用于监测车辆实时速度和位置信息,采用离散交通状态编码对检测区道路进行网格化处理以建立模型的状态空间,从而根据车辆的实时位置不断调整模型的输入,实现对实时交通流的及时反馈;3、本发明设计换道区用于向自动驾驶车辆传输交通信号控制和是否可换道指令,利用模型输出的交通信号动作空间,生成自动驾驶车辆换道的信号控制方案,拥有传统管控方案所不具备的灵活性、动态性;4、本发明设计以增加平均绿灯时间内的换道车辆数和降低换道信号开放成本为目标的奖励函数,从而促进更多的自动驾驶车辆换道至专用道,提高路段通行能力。
本文地址:https://www.jishuxx.com/zhuanli/20240731/185770.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。