基于图注意力和值分解强化学习的区域交通信号控制方法
- 国知局
- 2024-07-31 21:05:11
本发明涉及智能交通控制,特别是涉及一种基于图注意力和值分解强化学习的区域交通信号控制方法。
背景技术:
1、当前城市的交通拥堵问题已经造成了巨大的经济和时间浪费,而交通拥堵是由多种因素引起的,如不合理的信控方案、车道结构缺陷等,而有效的交通信号控制是提高车道通行效率最直接、成本最低的途径。当前城市里最广泛使用的交通信号控制方式是分时段的人工配时,这种方式依赖于传统信控原理和大量的人工设计经验,能够一定程度缓解交通拥堵问题,然而任然存在固定配时无法自适应针对变化车流量的问题,且配时效率比较低,因此当前的交通信号控制方法仍有大量提升空间。
2、随着人工智能技术的快速发展,基于强化学习的交通控制方法是当前自适应交通信号控制领域的研究重点。此类方法能够根据当前交通状态输出最优的信号控制策略,这相比于固定配时进一步提升了交通效率和路网吞吐能力,此外还能够适用于高峰期、路口拥堵等各种复杂的交通场景。
3、基于强化学习的交通控制方法存在如何设计交通状态的重要问题,现有研究通常将队列长度、速度、等待时间等固有状态组合拼接,这一方面增大状态设计的困难度,另一方面忽略了大量路网拓扑结构信息。此外面对区域信号控制问题时多使用多智能体强化学习,而多智能体协同决策存在价值函数估计问题和动作选择困难问题。所以如何提取交通状态特征以及协同训练多智能体成了亟需解决的问题。
技术实现思路
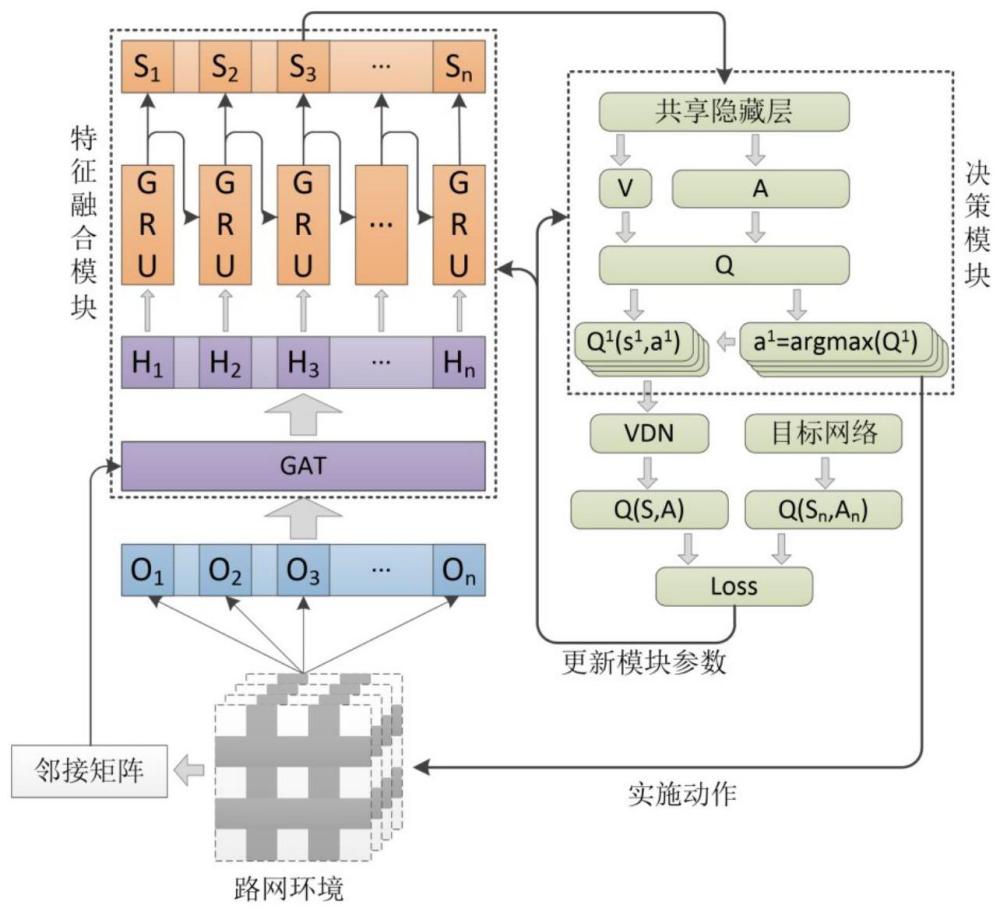
1、本发明的目的在于提出一种基于图注意力和值分解强化学习的区域交通信号控制方法,一方面通过包含多头图注意力网络和门控循环单元的特征融合模块获取当前路网状态的时空特征,有效减轻状态设计的困难度,另一方面通过值分解网络训练减轻多智能体的价值函数估计问题和动作选择问题。
2、实现本发明目的技术解决方案为:一种基于图注意力和值分解强化学习的区域交通信号控制方法,包括如下步骤:
3、步骤1,根据路网环境和车流量数据建立仿真环境,并根据路网计算邻接矩阵作为图结构;
4、步骤2,采集到交通流量信息,包括相位、队列长度、车辆密度、相位切换许设计强化学习的状态、动作和奖励;
5、步骤3,构建区域交通信号控制模型,包括特征融合模块、d3qn决策模块和值分解网络vdn,特征融合模块由多头图注意力网络和门控循环单元组成,各个路口的状态记通过多头图注意力网络得到路口各自的输出特征,再通过门控循环单元得到融合历史信息的最终特征;d3qn决策模块由两个决斗网络组成,以各个路口的最终特征拼接上对应的路口标识序号为输入,得到状态动作价值;vdn只包含一个求和网络,通过对输入的所有路口的状态动作价值求和来近似全局的状态动作价值;
6、步骤4,收集智能体与交通仿真环境的交互经验,并存储到经验池中;
7、步骤5,对经验池抽样,使用抽样所得样本训练区域交通信号控制模型,完成区域交通信号控制。
8、进一步的,步骤1,根据路网环境和车流量数据建立仿真环境,并根据路网计算邻接矩阵作为图结构,具体方法为:
9、步骤11,根据真实控制区域需求编写路网文件和车流量文件,路网文件包括所有路口、道路之间的连接信息,车流量文件包括每辆车的最大加速度、最大速度、路由信息和出发时间;
10、步骤12,根据路网文件、车流量文件建立交通仿真环境;
11、步骤13,根据路网连接信息计算邻接矩阵,二维矩阵的行列号代表对应路口编号,矩阵中的元素表示其对应行列号的路口是否存在连接,若有连接元素设置为1,否则设置为0。
12、进一步的,步骤2,采集到交通流量信息,包括相位、队列长度、车辆密度、相位切换许设计强化学习的状态、动作和奖励,具体方法为:
13、(1)状态
14、状态表示为一个一维矩阵s={p,min,d,q},包含相位、队列长度、车辆密度、相位切换许可四个子状态矩阵,相位p使用独热编码表示,第i个相位pi记为{0,…,pi,…,0},pi为1,其余元素为0;车道的队列长度q表示为{q1,…,qi,…,qn},其中第i个车道的队列长度qi=nsi(lv+2.5)/ll,nsi为车道上停止的车辆数,lv为车道上车辆的平均长度,2.5为车辆之间的最小间距,ll为车道的长度;车道的车辆密度d表示为{d1,…,di,…,dn},其中第i个车道的车辆密度di=ni(lv+2.5)/ll,ni为车道上所有车辆数;相位切换许可min记为{1}或{0};
15、(2)动作
16、动作设为信号灯的下一个相位选择,动作空间为信号灯的所有相位,信号灯设置为随机相位切换,即从当前相位切换到任意相位;
17、(3)奖励
18、奖励r为路口所有车道的队列长度之和的负数,
19、进一步的,步骤3,构建区域交通信号控制模型,包括特征融合模块、d3qn决策模块和值分解网络vdn,具体方法为:
20、步骤31,构建特征融合模块,为多头图注意力网络和门控循环单元的串联构架,其中多头图注意力网络由多个结构一致、输入一致的图注意力网络并联组成;
21、(1)多头图注意力网络
22、针对单个图注意力网络,将各个路口的状态记作原始特征si通过一个33×64的全连接层分别得到嵌入特征hi,将所有嵌入特征输入一个64×64的全连接层分别得到增强特征,将任意两个路口的增强特征拼接得到联合特征,将所有联合特征通过一个128=1的全连接层输出得到路口两两之间的相似系数eij,包括路口对自身的相似系数eii;将相似系数排列为相似系数矩阵,与邻接矩阵类似的,相似系数矩阵中的元素表示其对应行列号的路口之间的相似系数;将相似系数矩阵通过邻接矩阵的掩膜操作后输入一个softmax函数获得路口之间注意力系数αij,使用注意力系数对嵌入特征加权求和并使用elu函数激活得到融合特征h′i;以上为单个图注意力网络所得的融合特征,将多个图注意力网络输出的融合特征拼接得到路口各自的输出特征;
23、(2)门控循环单元
24、门控循环单元先将多头图注意力网络中所有路口各自的输出特征输入一个64×64的全连接层得到统一尺寸的空间特征,在初始时刻使用门控循环单元前需要初始化一个尺寸与空间特征一致的历史时序特征,所初始化的历史时序特征所有元素为0,将所有路口各自的空间特征和历史时序特征输入gru层,输出融合历史信息的最终特征,并将该最终特征作为下一时刻的历史时序特征使用;
25、步骤32,构建多智能体共享参数条件下的d3qn决策模块,所构建的d3qn决策模块包含两个结构相同、参数不同的决斗网络,输出决策时只使用第一个决斗网络,而更新参数时同时使用两个决斗网络;
26、决斗网络为区别不同路口需要对特征添加路口标识序号的独热编码,将特征融合模块输出的各个路口的最终特征拼接上对应的路口标识序号,输入一个80×128的全连接层得到过渡特征,决斗网络有值函数和优势函数两个网络分支,将过渡特征分别输入值函数网络和优势函数网络,值函数网络由两个全连接层串联组成,尺寸分别为128×128、128×1,优势函数网络由两个全连接层串联组成,尺寸分别为128×128、128×8,对优势函数网络的输出求取平均差并与值函数网络的输出求和得到状态动作价值,根据ε-greedy策略取状态动作价值中最大值对应的动作作为输出策略;
27、步骤33,构建训练时使用的值分解网络vdn,vdn只包含一个求和网络,通过对输入的所有路口的状态动作价值求和来近似全局的状态动作价值;
28、步骤34,设置损失函数为huber损失函数,优化器为adam优化器,初始化超参数,包含学习率、折扣因子、抽样数量、经验池尺寸、时序长度、决策频率、训练频率、训练轮数。
29、进一步的,步骤4,收集智能体与交通仿真环境的交互经验,并存储到经验池中,其中:
30、经验池为一个python队列,元素个数最多为经验池尺寸,每个元素为一个python列表,每个列表代表一条完整仿真过程,列表的每个元素表示一个状态转移{s,a,snext,r},s为所有路口当前状态,a为所有路口选择的动作,snext为动作执行后所有路口的下一个状态,r为根据下一个状态计算得到的奖励,s和snext间隔一定数量的仿真步数,取决于决策频率,智能体与交通仿真环境交互产生经验,当经验数量达到经验池尺寸上限,会丢弃最旧的经验。
31、进一步的,步骤5,对经验池抽样,使用抽样所得样本训练区域交通信号控制模型,完成区域交通信号控制,具体方法为:
32、步骤51,按抽样数量在经验池中随机抽取经验样本,若经验池样本数量小于1,则退出训练继续采样;否则按照时序长度随机从抽取的经验样本中截取一段连续的状态转移作为输入;
33、步骤52,将状态转移前后原始状态s和snext分别通过特征融合模块得到状态转移前后的最终特征h和hnext;
34、步骤53,使用构建的两个决斗网络,将h和a输入第一个决斗网络获得当前状态下的状态动作价值q(s,a;θ),将hnext输入第一个决斗网络获得下一个状态的最佳动作将hnext和a′输入第二个决斗网络获得θ和分别为两个决斗网络的网络参数;
35、步骤54,使用构建的vdn,将所有智能体当前和下一个状态动作价值输入值分解网络获得全局状态动作价值的估计q(s,a;θ)=∑q(s,a;θ),其中s和snext表示当前和下一个全局状态;
36、步骤55,根据奖励计算目标值其中γ为折扣因子;
37、步骤56,计算目标值和当前状态动作价值的损失loss=q(s,a;θ)-t,并根据该损失反向传播更新多头注意力网络、门控循环单元和d3qn模块的网络参数。
38、一种基于图注意力和值分解强化学习的区域交通信号控制系统,实施所述的基于图注意力和值分解强化学习的区域交通信号控制方法,实现基于图注意力和值分解强化学习的区域交通信号控制。
39、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,实施所述的基于图注意力和值分解强化学习的区域交通信号控制方法,实现基于图注意力和值分解强化学习的区域交通信号控制。
40、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实施所述的基于图注意力和值分解强化学习的区域交通信号控制方法,实现基于图注意力和值分解强化学习的区域交通信号控制。
41、本发明与现有技术相比,其显著优点在于:
42、(1)特征融合模块采用多头图注意力网络和门控循环单元的串联架构,有效提取当前交通路网状态的时空特征,减轻状态设计的困难度。
43、(2)d3qn决策模块采用双决斗深度q网络,有效减轻单个网络的价值高估问题,有效提高了对不同动作优劣估计的准确度。
44、(3)使用共享参数条件下的值分解网络来协助训练,有效减轻多智能体的价值函数估计问题和动作选择问题。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188283.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。