一种基于深度学习算法的水库边坡形变预警方法与流程
- 国知局
- 2024-07-31 21:20:01
本发明涉及水库安全,特别涉及一种基于深度学习算法的水库边坡形变预警方法。
背景技术:
1、水库边坡预警是水库安全保障的重要手段之一。目前的边坡预警手段大多采用传感器监测结合预警判断算法的技术手段,采用的传感器包括图像传感器、超声波探测传感器、振动监测传感器等等,采集的特征信息包括位移量、裂痕监测、土壤湿度等等,均为可直接或间接影响滑坡的要素。
2、预警判断算法,最常用也是最简单的是阈值判断,当某一或某几个特征信息超过阈值时,进行边坡预警。其不足之处在于:1、对于不同的边坡阈值设定不同,容易出现误判;2、对于由好几个特征引起的滑坡,无法通过单一的阈值判断实现预警。
3、随着人工智能的发展,预警判断算法也开始采用大数据算法,其原理是采集大量历史数据信息,由历史数据信息训练预测模型,再通过预测模型完成边坡预警。其不足之处在于:1、边坡之间差异巨大,都于相同的诱发条件,不同边坡有着不同的结果,无法通过一个预测模型完成所有边坡预测;2、若采用分类构建预测模型的方式,可在一定程度上提高预测准确度,但相同类别之中的边坡也有较大差异,每个类别以同一个模型进行预测,准确度也较差;3、若针对每一边坡都构建一个预测模型,该边坡的历史数据量较少,不足以训练预测模型,且构建模型太多,算力成本高。
技术实现思路
1、本发明公开了一种基于深度学习算法的水库边坡形变预警方法。
2、它通过这样的技术方案实现的,具体方法如下:
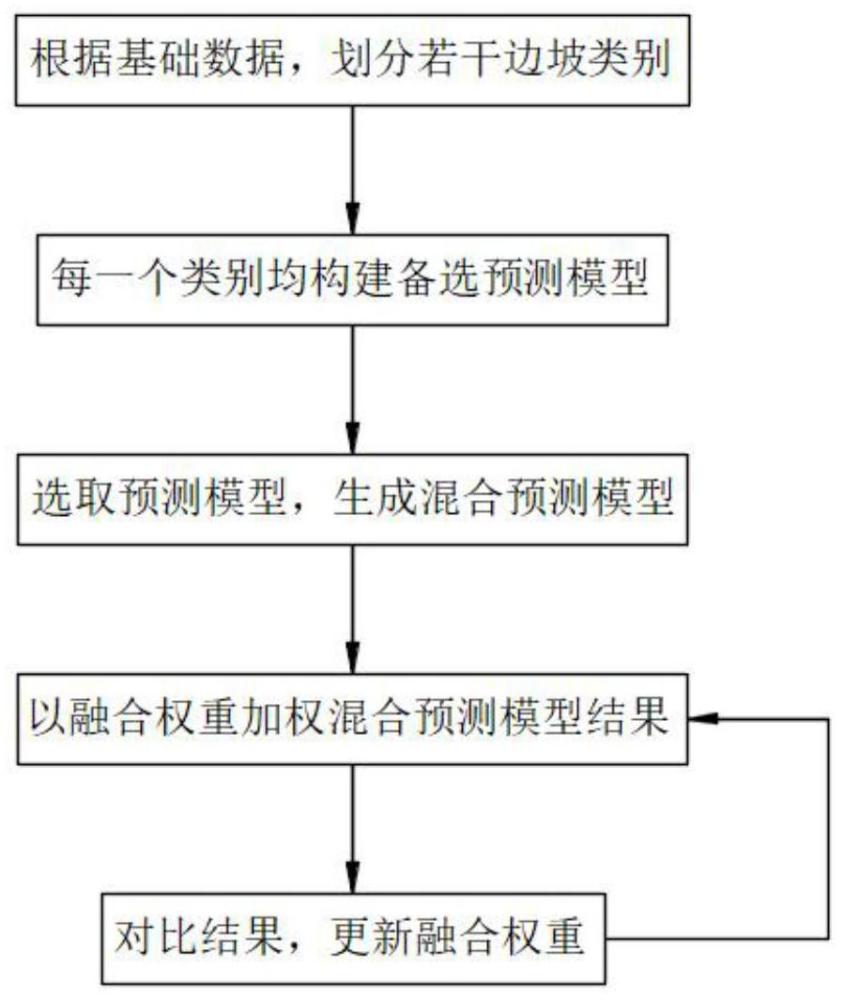
3、确定待预警边坡的基础数据;
4、根据待预警边坡的基础数据确定一个主预测模型和若干次预测模型;
5、获取待预警边坡当前特征数据;
6、将当前特征输入主预测模型,获取主预测结果;将当前特征输入若干次预测模型,获取若干次预测结果;
7、以初始融合权重加权主预测结果和若干次预测结果,作为当前滑坡预测结果;
8、将待预警边坡的当前实际结果与当前滑坡预测结果进行比对,根据对比结果调整融合权重,作为该待预警边坡下一次预警时的融合权重。
9、进一步,基础数据包括:边坡土石比例、边坡植被覆盖比较、边坡平均坡度、边坡最大坡度、水位线以下边坡高度、水位线以上边坡高度;
10、所述特征数据包括:边坡位移速率、单位时间边坡滚石滑落量、过去预设时间段至当前时刻的降雨量、当前时刻至未来预设时间的预测降雨量。
11、进一步,所述主预测模型和若干次预测模型,构建方法如下:
12、获取若干历史边坡的基础数据;
13、以k-means均值聚类算法对若干历史边坡进行聚类,划分为若干个边坡类别;
14、针对每个边坡类别均构建一个神经网络模型,获取对应历史边坡在滑坡前的特征数据;
15、以特征数据作为训练样本,以训练样本训练对应的神经网络模型,获取若干训练完成的神经网络模型作为备选预测模型;
16、根据待预警边坡的基础数据,判断待预警边坡的边坡类别;
17、以待预警边坡所属边坡类型所对应的备选预测模型作为主预测模型,在其余备选预测模型中选取次预测模型。
18、进一步,在备选预测模型中选取次预测模型的具体方法如下:
19、计算待预警边坡的基础数据分别到每个边坡类别中心点的欧式距离;
20、选取欧式距离在阈值范围之内的若干边坡类别所对应的备选预测模型,作为若干次预测模型。
21、进一步,所述初始融合权重的设置方法如下:
22、分配主预测模型初始权重为次预测模型初始权重均为
23、其中,w表示权重,main表示主预测模型,se,l表示第l个次预测模型;
24、令
25、其中k为初始倍率,k>1
26、根据公式求取次预测模型初始权重
27、
28、根据公式求取主预测模型初始权重
29、
30、进一步,待预警边坡的当前实际结果的获取方法为:
31、经过预设时间未发生滑坡,则当前实际结果为未发生滑坡,标记为0;
32、预设时间之内发生滑坡,则当前实际结果为发生滑坡,标记为1。
33、进一步,加权主预测结果和若干次预测结果,具体方法如下:
34、假设待预警边坡有记录的滑坡次数为i-1次,需预警第i次滑坡;
35、待预警边坡的当前权重集合为
36、待预警边坡的当前主预测模型和若干次预测模型的输出表示为:
37、fneural network={fmain(x)、fse,1(x)、fse,2(x)、...、fse,l(x)}
38、其中,每个预测模型输出结果为0或1;
39、加权结果results表示为:
40、
41、若results大于固定判断阈值th,则判断为预设时间内会发生滑坡;
42、若results小于固定判断阈值th,则判断为预设时间内不会发生滑坡。
43、进一步,根据对比结果调整融合权重,具体方法如下:
44、比较待预警边坡的当前实际结果与results‘i与主预测模型和若干次预测模型的输出结果fneural network;
45、选出预测结果正确的正确预测模型fcorrect,以及预测错误的错误预测模型ferror;
46、增加正确预测模型fcorrect对应的权重weightcorrect,降低错误预测模型对应的权重weighterror。
47、进一步,增加正确预测模型fcorrect对应的权重weightcorrect,降低错误预测模型对应的权重weighterror,具体方法如下:
48、记录每个预测模型历史预测正确的次数ncorrect以及历史预测错误的次数nerror;
49、将历史预测正确的次数ncorrect和历史预测错误的次数nerror代入权重调整计算公式,算得当前权重调整的具体数值。
50、进一步,正确预测模型fcorrect的权重调整计算公式如下:
51、
52、错误预测模型fcorrect的权重调整计算公式如下:
53、
54、式中,a1、a2、a3和a4均为常数。
55、由于采用了上述技术方案,本发明具有以下有益效果:
56、1、根据边坡基础数据,将边坡划分为若干类别,针对每个类别分别构建一个预测模型,相较于单一预测模型,提高了预测精度。
57、2、对于特定边坡预测,采用多个预测模型分别进行预测,再以权重融合,可避免单一预测模型出错的概率。
58、3、若干备选模型可针对所有边坡,对于每一个边坡都可构建最符合的独有混合预测模型,既可提高模型的应用范围,又可根据单一边坡的独特性针对性提高预测精度。
59、4、融合权重具有可更新的能力,针对每一边坡所构建的混合预测模型,在长期预测的过程中可优化独有混合预测模型的精度,每个边坡的预测模型都具有独自学习能力,并不影响备选模型。
60、5、对于所有备选模型,可保持收集所有边坡数据,持续优化神经网格模型,使备选模型性能提高。
本文地址:https://www.jishuxx.com/zhuanli/20240731/189296.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表