一种基于可重构智能反射面与人工噪声的无人机双模式安全通信方法
- 国知局
- 2024-08-02 14:01:14
本发明涉及安全无线通信,具体为一种基于可重构智能反射面与人工噪声的无人机辅助安全通信方法。
背景技术:
1、无线通信安全对于保护通信隐私和数据完整性至关重要。传统上,加密和认证技术被广泛采用作为被动安全防护措施,旨在防止未经授权的访问和数据篡改。然而,这些基础安全机制在抵御主动攻击手段方面存在局限性。即使通信数据经过加密,攻击者仍可能通过窃取无线信号并尝试解密来获取敏感信息。此外,在中间人攻击中,攻击者可能会伪造身份绕过认证机制,从而控制或干扰通信链路。因此,仅依赖传统的被动安全防护措施难以充分应对各种主动攻击手段,需要采取更加先进和主动的安全防护策略来确保无线通信的绝对安全。
2、为了增强无线通信安全,研究者们提出了包括人工干扰法和基于可重构智能反射面等的安全通信技术等主动防御方案。人工干扰法通过在通信链路中引入人工噪声信号来扰乱潜在的窃听者,虽然能够在一定程度上阻断窃听,但需要一定的先验知识,并可能因增加噪声而降低系统频谱和能量效率。另一方面,ris由众多可编程控制的无源反射单元组成,能够主动重塑无线信道环境,为合法用户营造理想的信号传输路径,最大程度地集中无线信号能量,同时有效抑制对潜在窃听者的信号泄露。
3、人工干扰法和基于ris的方案在原理和作用机制上存在显著差异,但二者可以相互补充,发挥协同作用。人工干扰可为ris调制相位提供保护,防止恶意攻击者对ris进行干扰;而ris则可以辅助干扰信号的精准产生和高效传播,提高人工干扰对窃听者的影响效果。此外,ris还可用于主动增强合法用户的信号接收质量,从而抵消人工干扰可能带来的吞吐量损失。通过优化人工干扰和ris的协同配置,可实现无线通信的高安全性和高效率两手并重,满足未来更高级的安全通信需求。
4、尽管ris技术和人工干扰在理论上为安全通信提供了新的主动防御手段,但现有研究存在一些局限性。一方面,大多数工作仍局限于理想化的单径或简化信道模型,忽视了实际复杂的多径传播环境,如城市场景。另一方面,无论采用人工干扰还是ris辅助的防御方案,在建立系统模型和求解优化问题时,研究者们普遍面临着非凸约束优化的挑战。
5、传统的迭代优化算法,如逐次二次规划法和对偶分解法等,需要良好的初始点和满足凸性假设,在高维复杂问题上容易陷入次优解。虽然智能优化算法(诸如蚁群算法和模拟退火算法等)具有全局搜索能力,但收敛速度慢且计算效率低下,尤其在寻找可行解的迭代过程中耗费巨大。相比之下,深度强化学习(drl)提供了一种基于试错思想的端到端优化策略,能够自主学习并不断调整策略以适应复杂环境,突破了传统算法的诸多局限。将drl引入无线通信安全优化领域,不仅可摆脱凸性假设和初始点的限制,而且为复杂场景下主动防御策略的自主优化设计提供了全新的思路和工具,有望显著提升系统的安全性和鲁棒性,具有广阔的应用前景。
技术实现思路
1、本发明的是针对现有技术所存在不足,提供一种基于可重构智能反射面与人工噪声的无人机辅助安全通信方法,旨在解决实际应用中存在的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于可重构智能反射面与人工噪声的无人机辅助安全通信方法,包括以下步骤:
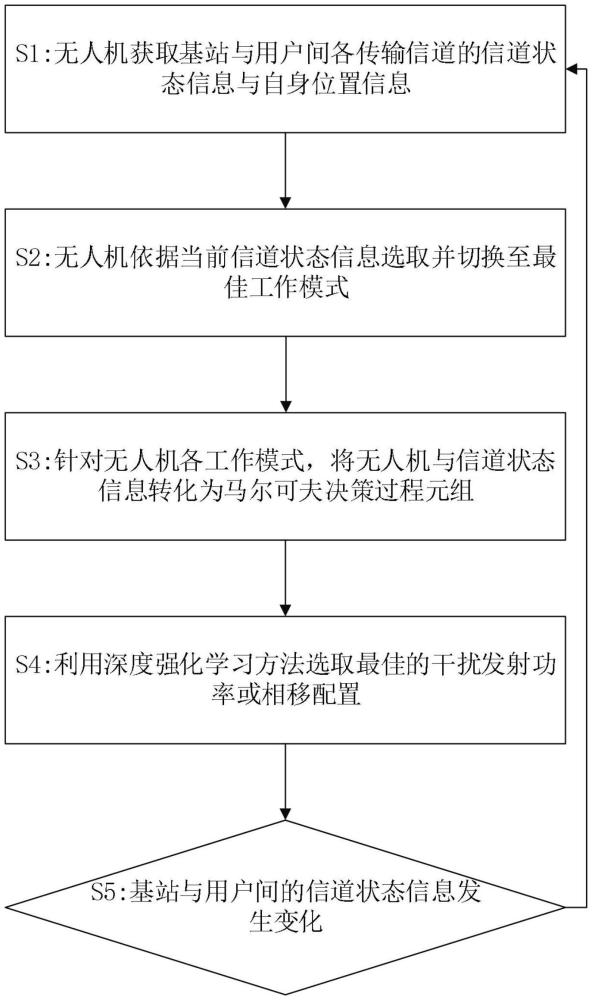
3、s1:无人机获取基站与用户间各传输信道的信道状态信息与自身位置信息;
4、s2:无人机依据当前信道状态信息选取并切换至最佳工作模式;
5、s3:针对无人机各工作模式,将无人机与信道状态信息转化为马尔可夫决策过程元组;
6、s4:利用深度强化学习方法选取最佳的干扰发射功率或相移配置;
7、s5:当基站与用户间的信道状态信息发生改变则回到步骤s1。
8、作为本发明的一种优先技术方案:还包括实施该通信方法的系统,该系统构成如下:
9、p1:一个配备na个发射天线地面通信基站bs;
10、p2:k个配备单天线的固定地面用户设备ue;
11、p3:一个详细位置未知的潜伏窃听者eav;
12、p4:一个多功能无人机uav同时搭载了具有mc×mr个反射单元组成的均匀平面阵列可重构智能反射表面与具有最大发射功率为pmax的人工噪声发生装置。
13、作为本发明的一种优先技术方案:步骤s1中无人机自身位置信息为:将无人机的任务持续时间划分为共nt个长度为δ的等长不重叠的时间区间,每个时间区间可表达为n∈[1,...,nt],无人机在第n时间区间中的坐标表示为q[n]=(qu[n],hu[n]),其中qu[n]=(xu[n],yu[n])为其水平坐标,hu[n]则为其垂直坐标;此外无人机的动力学模型建模为:
14、
15、
16、hu[n+1]=hu[n]+vsinψ[n] (3)
17、其中v为无人机在该时间区间的速度,ψ与则分别为无人机在该时间区间的偏航角与俯仰角;
18、地面的用户设备坐标记作qk=(xk,yk),潜伏窃听者的精确坐标记作qee=(xee,yee),窃听者估计位置记作qe=(xe,ye),并将水平方向的估计误差分别记作δxe与δye,则实际坐标与估计坐标间关系表示为:
19、xe=xee+δxe,ye=yee+δye (4)
20、同时,将坐标估计误差记作ε,并要求误差满足从而将窃听者的估计位置限定在以其精确位置为圆心的圆形区域中。
21、作为本发明的一种优先技术方案:步骤s2中所述的最佳工作模式具有不同的通信信道,针对两种工作模式的信道建模分别如下:
22、t1:将使用ris增强地面基站与地面合法用户设备间通信的模式记作模式1,则在模式1下将主要存在bs-ue/eav的直射信道与bs-ris-ue/eav的反射信道;考虑到复杂环境中地面障碍物对直射信道的阻挡,采用莱斯衰落模型对地信道进行表达:
23、
24、
25、其中,与是服从零均值与单位方差的圆对称复高斯变量,为虚数向量或矩阵,na为基站天线数,dbk与dbe分别为bs与ue和eav间的欧式距离,κ1为地对地信道的路径损失系数;
26、t2:模式1下的反射信道采用瑞丽衰落对信号的小尺度衰落进行建模,则空地的信道表达为:
27、
28、其中mc与mr分别为ris阵列中垂直方向于水平方向的反射单元个数,ρ为在参考距离1m处的路径损失,k2为空对地间的路径损失系数,βr为瑞丽系数,与分别为确定的直射信道与由零均值与单位方差的圆对称复高斯变量组成的非直射信道,其中直射阵列响应表示为:
29、
30、其中,λ为波长,di为均匀平面阵列ris上反射单元的间距,与分别为水平到达角的余弦值与正弦值,则为垂直到达角的正弦值,相似可得ris-ue/eav的信道与
31、t3:模式1下ue与eav处的可达率分别表示为:
32、
33、
34、其中pb为基站恒定的发射功率,σ为加性高斯白噪声,为ris的反射系数矩阵,其中为每个反射单元的相移;
35、t4:模式2中无人机使用人工噪声发射器干扰潜在窃听者,该模式下ue与eav处的可达率分别表达为:
36、
37、
38、其中,pj为人工噪声信号的发射功率,guk与gue分别为干扰信号对ue与eav的增益;
39、t5:模式1与模式2下的最坏保密率分别为:
40、
41、
42、t6:安全率优化问题定义为:
43、
44、其中,q为无人机轨迹,θ为ris相移,p为干扰功率,nt为任务总时隙数,k为总用户数,约束条件c1与c2分别限制了无人机水平及垂直方向运动的最大速度,与分别为无人机在水平与垂直方向上的最大速度,δ为时隙长度;c3与c4限制了无人机运动的场地,qmin与qmax为场地水平方向边界,hmin与hmax为场地垂直方向边界;c5与c6限制了无人机的最大偏航角与俯仰角,ψmin与ψmax为最小与最大偏航角,与为无人机的最小与最大俯仰角;c7与c8分别对与ris相移与人工噪声发射功率做出限制,θk[n]为当前ris相移,pj[n]为当前干扰发射功率,pmax为无人机的最大干扰发射功率;c9中c[n]为工作模式指示变量,限制同一时间中无人机只可在一种工作模式。
45、作为本发明的一种优先技术方案:步骤s3中马尔可夫决策过程建模的步骤如下:
46、s3-1:为模式1定义状态空间smode1(n)={q[n],hbr[n],hrk[n],hbk[n]},为模式2定义状态空间smode2(n)={q[n],hbk[n]};
47、s3-2:为模式1定义动作空间为模式2定义动作空间
48、s3-3:奖励设计为r(n)=r[n]-ξv[n],其中,为当前时隙的保密率,v为违反约束条件的惩罚,ξ为惩罚系数。
49、作为本发明的一种优先技术方案:步骤s4中所述的基于深度强化学习的方法具体使用了一种深度学习网络架构,该架构的包括以下内容:
50、原actor网络、原critic网络与目标actor网络、目标critic网络均由三层全连接网络所构成,actor网络的前两层网络分别具有256与128个神经元,采用leakyrelu函数作为激活函数;
51、输出层的神经元数量等同于当前工作模式下动作空间的维度,并采用tanh函数作为激活函数critic网络的前两层分别配置有128和64个神经元,采用leakyrelu函数作为激活函数;
52、输出层维度为1,不使用激活函数,经验回放池为两个大小为1000000的独立池bmode1与bmode2,智能体的互动环境包括主环境e与两个主环境副本e1与e2。
53、作为本发明的一种优先技术方案:步骤s4中所述基于深度强化学习的方法具体包括以下训练步骤:
54、s4-1:初始化主环境e,与两个主环境的副本e1与e2;
55、s4-2:使用随机参数为模式1和模式2分别初始化critic网络使用随机参数为模式1与模式2分别初始化actor网络πmode1与πmode2;
56、s4-3:使用随机参数为模式1和模式2分别初始化目标critic网络使用随机参数为模式1与模式2分别初始化目标actor网络π'mode1和π'mode2;
57、s4-4:为模式1与模式2分别初始化各自经验回放池bmode1与bmode2;
58、s4-5:将主环境e同步至e1与e2;
59、s4-6:在主环境e中观测得到各模式状态smode1(n)与smode2(n);
60、s4-7:根据各模式状态,通过分别为各模式选择动作amode1(n)与amode2(n),其中φ为actor网络参数,为具有0均值与0.1方差的高斯随机变量,amin与amax分别为动作的最小与最大取值,clip函数将其限制到合法范围中;
61、s4-8:在环境e1中执行模式1的动作amode1(n)并得到模式1的奖励rmode1(n)与次状态smode1(n+1),在环境e2中执行模式2的动作amode2(n)并得到模式2的奖励rmode2(n)与次状态smode2(n+1);
62、s4-9:将取得更高奖励的环境复制至主环境e中;
63、s4-10:将模式1与模式2的经验元组(smode1(n),amode1(n),rmode1(n),smode1(n+1))与(smode2(n),amode2(n),rmode2(n),smode2(n+1))分别存入各自经验回放bmode1与bmode2;
64、s4-11:通过计算各模式的目标q值;
65、s4-12:通过更新各模式所属的critic网络,其中nb为采样大小,θi为第i个critic网络的参数;
66、s4-13:若当前训练轮数为偶数,则通过更新各模式的actor网络,其中j为策略期望回报;
67、s4-14:若当前训练轮数为偶数,则通过θ′i←τθi+(1-τ)θ′i,i=1,2与φ′←τφ+(1-τ)φ′分别更新各模式的目标actor网络与模板critic网络参数,其中θ'与φ'分别为目标critic网络与目标actor网络的参数,τ为神经网络更新系数;
68、s4-15:若已达预先设置的训练次数,则完成训练,否则重复步骤s4-5至步骤s4-14。
69、与现有技术相比,本发明的有益效果为:
70、本发明提出将ris与人工噪声相结合的创新性安全通信方法,将两者分别运用于不同的工作模式,并采用基于深度强化学习的智能优化策略,在安全性、效率、鲁棒性等多方面展现出卓越性能。具体而言,ris模式通过重塑无线信道,为合法用户创造理想传输路径,最大限度集中无线信号能量,同时有效抑制对窃听者的信号泄露,从而显著增强通信安全性;人工噪声模式则通过引入干扰信号扰乱窃听者接收,对传统加密技术形成有力补充,进一步提高防窃听能力。两种模式可根据场景灵活切换协同,而基于深度强化学习的优化则可自主调控ris相位和人工噪声参数,在确保安全的前提下最大限度提升通信效率和质量。该创新方法有机结合了ris和人工噪声的优势,并融入了先进的智能优化手段,在安全通信领域展现出了优于现有技术的卓越性能和广阔的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20240801/241388.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表