基于平行动作网络结构PPO的DSA能耗优化方法
- 国知局
- 2024-08-02 14:45:58
本发明涉及一种认知无线电技术,尤其是涉及一种基于平行动作网络结构(parallel action network structure,pans)ppo(proximal policy optimization,近端策略优化,其是强化学习的一种算法)的dsa(dynamic spectrum access,动态频谱接入)能耗优化方法,其通过平行动作网络结构ppo算法训练主基站的智能体,以实现在dsa网络中,主基站控制其他md(mobile device,移动设备)进行动态频谱接入并控制发射功率,并实现最小化能耗,使得所有md都能最快、最节能地传输完成自己的数据,其适用于使用交织式接入模型(如noma,non-orthogonal multiple access,非正交多址接入)的dsa网络。
背景技术:
1、随着第五代无线通信技术(5g)的迅猛进步,无线设备的数量正通过无线电接入网络实现急剧增长,这进一步加剧了人们对无线通信服务的需求。尽管毫米波通信的研究日益受到重视,但其高频段特性导致的穿透能力不足和覆盖区域有限等问题依然显著。若依赖毫米波通信实现广泛覆盖,则将面临巨大的成本挑战。因此,在5g及物联网(iot)的演进中,提高中低频段的频谱效率同样至关重要。于是,认知无线电(cr,cognitive radio)应运而生,其中dsa应用最为广泛。dsa是一种允许无线频谱更加高效使用的技术。交织式接入是dsa的一种接入方式,在交织式接入模型中,允许多个用户同时接入同一个信道进行传输,因此,如何分配接入同一个信道的各个用户的发射功率是交织式接入模型的重中之重。
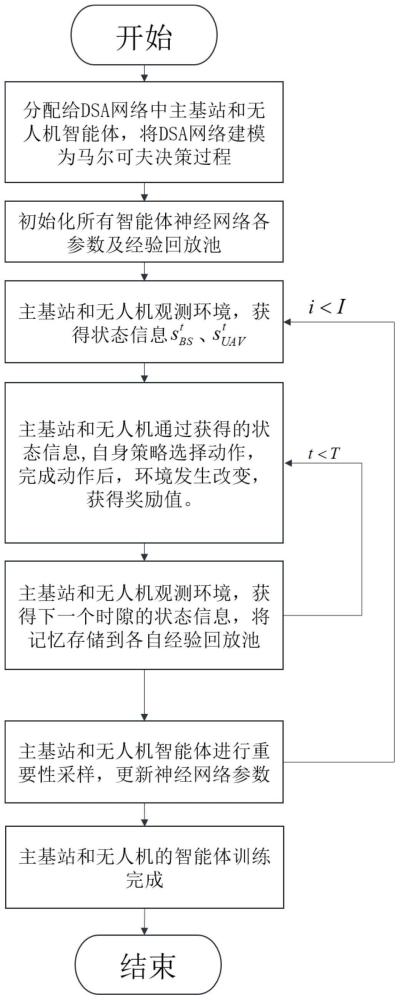
2、考虑到物联网在信息传递中的核心作用,确保联网实体(如基站和车辆)之间建立稳固的通信链路已成为一项迫切需求。这就要求dsa网络具备高效的频谱分配策略。然而,在如此竞争激烈的场景中,设计恰当的连接策略殊为不易。每个md(移动设备)必须能够准确感知系统状态,以适应不断变化的环境动态,这包括移动设备移动模式的变迁、网络运行概况的核心特征,以及单一移动设备决策对其他设备产生的连锁效应。由于多代理系统中访问控制问题的天然分布性,单一移动设备往往无法获取关于环境状态的全面信息,所以,以主机站作为控制中心进行集中控制,分配dsa网络中md的接入信道和发射功率会是一种可行的方案。
3、然而集中控制需要同时选择所有md(移动设备)的动作,这导致动作空间异常庞大,以至于即便是配备了强大计算能力的控制中心也难以实现有效的收敛。现有的研究(如上述集中控制)主要集中在优化md的吞吐量上,这种做法往往忽视了dsa网络中md之间的公平传输问题,从而导致了不必要的时间消耗和能耗浪费。此外,如今无人机与边缘计算器技术的发展与普及,使得dsa网络中的数据传输可以拥有更灵活的方式,使用无人机进行流量卸载也会是数据传输的趋势。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于平行动作网络结构ppo的dsa能耗优化方法,在一个使用交织式接入模型的dsa网络中,每个md拥有固定大小的数据包需要传输,由主基站配备的智能体作为集中控制的控制中心,并通过平行动作网络结构ppo算法训练主基站的智能体,以实现在dsa网络中控制每个md的接入信道和发射功率,并实现最小化能耗,使所有md都能以最快、最小的能耗传输完成自己的数据;且平行动作网络结构ppo算法能够有效的收敛。
2、本发明解决上述技术问题所采用的技术方案为:一种基于平行动作网络结构ppo的dsa能耗优化方法,其特征在于包括以下步骤:
3、步骤1:在认知无线电系统的dsa网络中,设定使用交织式接入模型进行数据传输,数据传输时传输开始到完成的过程定义为episode;设定共有一个主基站、m个移动设备、一架无人机,主基站配备有一个智能体和k个正交信道,无人机也配备有一个智能体,主基站的智能体使用平行动作网络结构ppo算法,无人机的智能体使用标准的ppo算法;设定无人机与主基站或移动设备之间通信使用专属频段;其中,m≥1,k≥1,平行动作网络结构ppo算法和标准的ppo算法均是以表演家-批评家网络为基础的深度强化学习算法,平行动作网络结构ppo算法包括表演家网络和批评家网络,表演家网络由离散动作网络和连续动作网络组成,离散动作网络和连续动作网络以及批评家网络均由输入层、隐藏层和输出层组成,隐藏层包含两个全连接层,离散动作网络的隐藏层和输出层分为m个分支,平行动作网络结构ppo算法的表演家网络的结构称为平行动作网络结构;标准的ppo算法包括表演家网络和批评家网络,表演家网络和批评家网络均由输入层、隐藏层和输出层组成,隐藏层包含两个全连接层;
4、步骤2:将dsa网络建模为马尔可夫决策过程,在马尔可夫决策过程中,主基站的智能体和无人机的智能体分别与环境交互,主基站的智能体和无人机的智能体在同一个episode开始前各自观测环境获得各自的观测状态;之后根据主基站的智能体在这个episode开始前观测环境获得的观测状态以及主基站的智能体自身的策略,主基站的智能体在这个episode内从混合动作空间中选择一个混合动作,在混合动作完成后环境会发生改变,同时主基站的智能体在这个episode内得到奖励值;同样,根据无人机的智能体在这个episode开始前观测环境获得的观测状态以及无人机的智能体自身的策略,无人机的智能体在这个episode内从单一动作空间中选择一个单一动作,在单一动作完成后环境会发生改变,同时无人机的智能体在这个episode内得到奖励值;其中,混合动作空间由离散动作空间和连续动作空间组成,主基站的智能体在这个episode内从离散动作空间中为每个移动设备选择一个离散动作,主基站的智能体在这个episode内从连续动作空间中为每个移动设备选择一个连续动作,主基站的智能体在这个episode内从离散动作空间中选择的所有离散动作和从连续动作空间中选择的所有连续动作构成混合动作,策略本质上是一个概率分布,用于反映观测状态下选择每个动作的概率,主基站的智能体自身的策略有两部分,一部分为离散动作网络相应的离散动作策略,另一部分为连续动作网络相应的连续动作策略,主基站的智能体在这个episode内得到的奖励值是负值;
5、步骤3:在将dsa网络建模为马尔可夫决策过程后,主基站的智能体使用平行动作网络结构ppo算法进行训练阶段,训练阶段的具体过程如下:
6、步骤3.1.1:初始化主基站的智能体使用的平行动作网络结构ppo算法的算法参数;初始化主基站的智能体对应的经验回放池;设定训练阶段共进行i个循环,每个循环共进行t个episode;其中,i>1,t>1;
7、步骤3.1.2:对于第t个episode,将第t个episode作为当前episode,主基站的智能体在当前episode开始前观测环境获得观测状态其中,t的初始值为1,t=1,2,…,t;
8、步骤3.1.3:根据主基站的智能体在当前episode开始前观测环境获得的观测状态使用平行动作网络结构ppo算法,得到主基站的智能体在当前episode内选择的混合动作然后主基站的智能体在当前episode内做出混合动作在混合动作完成后,也就是所有移动设备的数据传输完成,环境会发生改变,同时主基站的智能体在当前episode内得到奖励值接着主基站的智能体在当前episode的末尾即下一个episode开始前观测环境获得观测状态
9、步骤3.1.4:主基站的智能体在当前episode内将自身的记忆存储在自身的经验回放池中;其中,主基站的智能体在当前episode内的记忆为
10、步骤3.1.5:令t=t+1,将第t个episode作为当前episode,然后返回步骤3.1.3继续执行,直至一个循环所进行的t个episode结束,再执行步骤3.1.6;其中,t=t+1中的“=”为赋值符号;
11、步骤3.1.6:对主基站的智能体对应的经验回放池中的记忆进行重要性采样,更新平行动作网络结构ppo算法的表演家网络中的离散空间网络和连续空间网络以及批评家网络的网络参数,再执行步骤3.1.7;
12、步骤3.1.7:令t=1,然后返回步骤3.1.2继续执行,直至i个循环结束,完成了主基站的智能体的训练阶段,得到了主基站的智能体对应的训练好的平行动作网络结构ppo模型;
13、同步地,无人机的智能体使用标准的ppo算法进行训练阶段,训练阶段的具体过程如下:
14、步骤3.2.1:初始化无人机的智能体使用的标准的ppo算法的算法参数;初始化无人机的智能体对应的经验回放池;设定训练阶段共进行i个循环,每个循环共进行t个episode;其中,i>1,t>1;
15、步骤3.2.2:对于第t个episode,将第t个episode作为当前episode,无人机的智能体在当前episode开始前观测环境获得观测状态其中,t的初始值为1,t=1,2,…,t;
16、步骤3.2.3:根据无人机的智能体在当前episode开始前观测环境获得的观测状态使用标准的ppo算法,得到无人机的智能体在当前episode内选择的单一动作然后无人机的智能体在当前episode内做出单一动作在单一动作完成后,也就是所有移动设备的数据传输完成,环境会发生改变,同时无人机的智能体在当前episode内得到奖励值接着无人机的智能体在当前episode的末尾即下一个episode开始前观测环境获得观测状态
17、步骤3.2.4:无人机的智能体在当前episode内将自身的记忆存储在自身的经验回放池中;其中,无人机的智能体在当前episode内的记忆为
18、步骤3.2.5:令t=t+1,将第t个episode作为当前episode,然后返回步骤3.2.3继续执行,直至一个循环所进行的t个episode结束,再执行步骤3.2.6;其中,t=t+1中的“=”为赋值符号;
19、步骤3.2.6:对无人机的智能体对应的经验回放池中的记忆进行重要性采样,更新ppo算法的表演家网络以及批评家网络的网络参数,再执行步骤3.2.7;
20、步骤3.2.7:令t=1,然后返回步骤3.2.2继续执行,直至i个循环结束,完成了无人机的智能体的训练阶段,得到了无人机的智能体对应的训练好的ppo模型;
21、步骤4:将训练好的平行动作网络结构ppo模型和训练好的ppo模型用于实施阶段,在实施阶段中,对于主基站的智能体,根据其对应的训练好的平行动作网络结构ppo模型,自行在一个episode开始前观测环境获得观测状态,在这个episode内从混合动作空间中选择一个混合动作,并做出混合动作;同时,对于无人机的智能体,根据其对应的训练好的ppo模型,自行在一个episode开始前观测环境获得观测状态,在这个episode内从单一动作空间中选择一个单一动作,并做出单一动作。
22、所述步骤2中,将主基站的智能体在第t个episode开始前观测环境获得的观测状态表示为将无人机的智能体在第t个episode开始前观测环境获得的观测状态表示为其中,t=1,2,…,t,t表示预设的一个循环所进行的episode的总个数,表示在第t个episode开始前第1个移动设备到主基站在第1个正交信道上的信道增益,表示在第t个episode开始前第1个移动设备到主基站在第2个正交信道上的信道增益,表示在第t个episode开始前第m个移动设备到主基站在第k个正交信道上的信道增益,在第t个episode开始前第m个移动设备到主基站在第k个正交信道上的信道增益为当t=1时dt-1=0,当t>1时dt-1表示在第t-1个episode内被无人机辅助卸载流量的移动设备的索引,移动设备的索引从1开始编号,pt表示在第t个episode内无人机的位置。
23、所述步骤2中,将主基站的智能体在第t个episode内从混合动作空间中选择的混合动作表示为的确定过程如下:
24、步骤2.1:将主基站的智能体在第t个episode内从离散动作空间ψ中为第m个移动设备选择的离散动作表示为的确定过程为:将主基站的智能体在第t个episode开始前观测环境获得的观测状态输入到离散动作网络中,离散动作网络的m个分支各输出一个离散动作,离散动作网络的第m个分支输出的离散动作即为其中,t=1,2,…,t,m=1,2,…,m,ψ={[1],[2],…,[m]},离散动作网络构建于平行动作网络结构ppo算法的表演家网络中,的确定表明主基站的智能体在第t个episode内分配给第m个移动设备的正交信道已确定;
25、步骤2.2:将主基站的智能体在第t个episode内从连续动作空间ω中为第m个移动设备选择的连续动作表示为的确定过程为:将主基站的智能体在第t个episode开始前观测环境获得的观测状态输入到连续动作网络中,连续动作网络输出m个值,根据m个值确定了其中,t=1,2,…,t,m=1,2,…,m,ω=(0,pmax],pmax表示移动设备的发射功率上限,连续动作网络构建于平行动作网络结构ppo算法的表演家网络中,的确定表明主基站的智能体在第t个episode内已明确第m个移动设备的发射功率;
26、步骤2.3:将主基站的智能体在第t个episode内从离散动作空间ψ中为每个移动设备选择的离散动作和从连续动作空间ω中为每个移动设备选择的连续动作合并构成主基站的智能体在第t个episode内从混合动作空间中选择的混合动作
27、所述步骤2中,将无人机的智能体在第t个episode内从单一动作空间中选择的单一动作表示为根据无人机的智能体在第t个episode开始前观测环境获得的观测状态以及策略来选择,其中,γ表示单一动作空间,γ={[1],[2],…,[m]},的确定表明被无人机辅助卸载流量的移动设备已确定。
28、所述步骤2中,将主基站的智能体在第t个episode内得到的奖励值表示为其中,表示在第t个episode内第m个移动设备的发射功率,表示在第t个episode内第m个移动设备传输完成数据所花费的时间;将无人机的智能体在第t个episode内得到的奖励值表示为其中,表示在第t个episode内无人机帮助被其辅助卸载流量的移动设备节省的能耗,表示在第t个episode内无人机飞行的功率,表示在第t个episode内无人机飞行所消耗的时间,无人机飞行的速度设置为恒定速度vuav。
29、与现有技术相比,本发明的优点在于:
30、1)本发明方法中提出了平行动作网络结构ppo算法,一方面将表演家网络分支为离散动作网络和连续动作网络,使得主基站的智能体能同时输出离散动作和连续动作,另一方面将离散动作网络根据移动设备数量分成多个分支,以上分支极大地减少了离散和连续动作空间的维度,降低了计算复杂度,避免了维度诅咒。采用平行动作网络结构的表演家网络使得算法更容易收敛,并有更好的训练效果。
31、2)本发明方法中主基站的智能体在一个episode内得到的奖励值是负值,在训练过程中这个负值越来越大,也就是能耗越来越小,达到了能耗优化的目的,即本发明方法以最小化能耗为优化目标,相比现存的大量优化吞吐量的研究,优化能耗在时间和功耗上拥有极大优势。
32、3)现今使用无人机或是边缘计算器来作为数据中继已成为趋势,多智能体多任务合作也以成为趋势,本发明方法引入无人机辅助移动设备的流量卸载,进一步降低了传输能耗。
33、4)本发明方法在稳定性方面表现出色,即使在场景中移动设备数量增加的情况下,依然能够保持高效的性能;此外,还显著降低了计算的复杂度,提升了传输的效率,使其在实际应用中更具可行性和实用性。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243846.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表