一种基于AI模型语音增强的方法及其装置和辅听设备与流程
- 国知局
- 2024-08-02 14:49:56
本发明涉及通信处理,尤其涉及一种基于ai模型语音增强的方法及其装置和辅听设备。
背景技术:
1、目前,专业助听器价格较为昂贵,且需要验配等环节,而辅听设备,可以随买随用,但只能一定程度放大人声,无法达到好的听力补偿效果。
2、经检索,专利:结合ai模型的特征域语音增强方法及相关产品(cn202011046052.4),所述方法包括:将初始语音信号执行初始操作得到特征域信号;基于ai模型确定特征域信号的增益,依据所述增益对特征域信号进行增强处理得到特征域增强信号;将特征域增强信号作为输入数据输入到运算模型,执行运算得到所述初始语音信号的输出结果。上述的方法及相关产品辅助的音质不高。
3、辅听设备,需要根据人耳损伤的特性,对特定频段声音进行增强“响度补偿技术”,然而这样的方式,只能小幅度提升对话过程中的识别率,与专业的助听器,效果差距较大。
技术实现思路
1、为解决上述技术问题,本发明的目的是提供一种基于ai模型语音增强的方法及其装置和辅听设备。
2、为实现上述目的,本发明采用如下技术方案:
3、一种基于ai模型语音增强的方法,
4、ai人声源定位,采用神经网络训练;
5、其中,采用麦克风阵列采集的信号作为输入信号,x1~x8,输出信号y1~y8,代表人声源空间角度,将空间三维角度每个维度360度,以10度为分辨率,共需要36×36,共1296个输出点,那么输出层为y1~y1296,其中,共2个隐藏层l,每个隐藏层,65536个数据,l1,1~l1,65536和l2,1~l2,65536;
6、通过声音的信号输入,根据梯度下降法,选取均方误差作为损失函数,公式所示:
7、
8、通过上述梯度下降法,将逐步训练出合适的,l1,1~l1,65536和l2,1~l2,65536的值,在神经网络训练完成后,通过查询y1~y1296的值,即可判断出人声方位
9、接着采用波束形成算法,其中,y0(n)~y8(n)为8个麦克风输入,wa,b为权重矩阵,z-1为延迟符号;
10、其传递函数如下:
11、
12、其中,矩阵d为方向矩阵,用来对不同角度的语音信号进行频域对齐,其中用虚线隔开的部分分别为不同入射角度的语音信号;
13、ω0~ωj分别代表了不同的频率分量;
14、τ0~τ8分别代表了不同的麦克风所对应是时间延迟;
15、矩阵f是目标响应矩阵,用虚线隔开的部分分别对应着不同入射角度信号的目标响应;
16、wa,b为权重矩阵,通过求解方程,得到的矩阵系数解,便是最终需要的设计的滤波器系数;
17、神经网络训练完成后,通过查询y1~y1296的值,即可判断出人声方位根据得到的方位,再计算出目标响应矩阵:
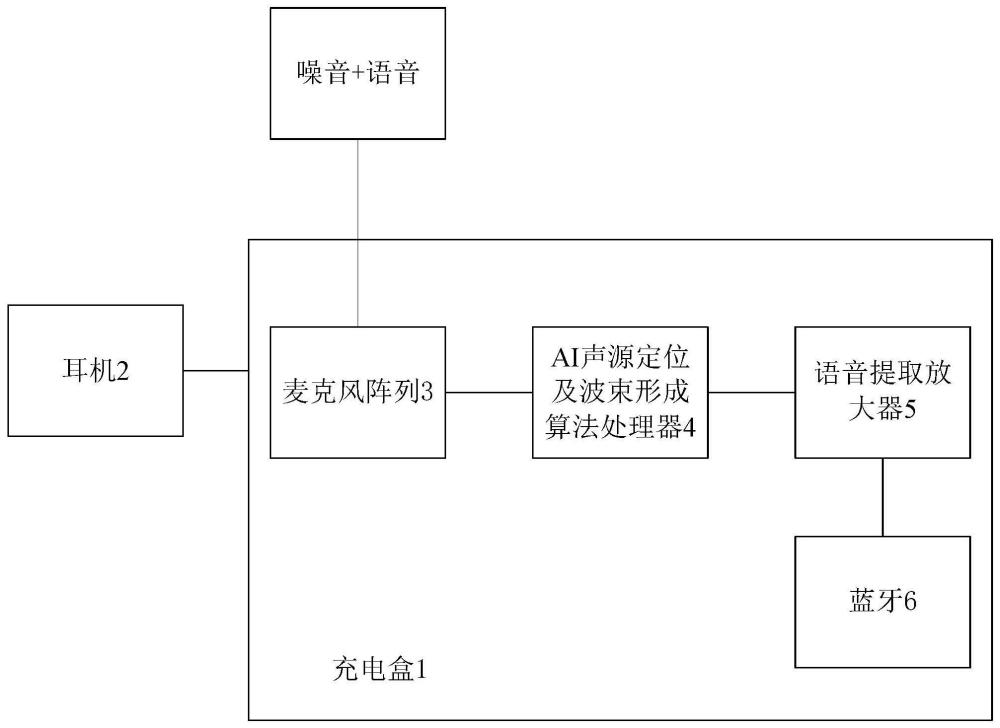
18、
19、通过设置目标响应矩阵f,决定固定波束形成结构对哪些方向的语音信号进行保留,又对哪些方向的语音信号进行抑制。
20、优选地,所述的一种基于ai模型语音增强的方法:在目标响应矩阵f,决定固定波束形成结构针对人生声源的语音信号进行保留。
21、优选地,所述一种基于ai模型语音增强的方法,在目标响应矩阵f,决定固定波束形成结构针对噪声声源的语音信号进行抑制。
22、一种基于ai模型语音增强的装置,其特征在于,麦克风阵列,用于收集噪音和语音;
23、ai声源定位及波束形成算法处理器,用于处理由麦克风阵列收集到噪音和/或语音后得到人生声源的语音信号,波束形成算法处理器执行如权利要求1-3任意一项所述的方法。
24、优选地,所述的一种基于ai模型语音增强的装置,麦克风阵列包括若干麦克风,若干麦克风组成立体排列的柱状结构,且每个麦克风与相邻麦克风之间等距间隔设置。
25、优选地,所述的一种基于ai模型语音增强的装置,所述麦克风设有8个。
26、一种辅听设备,包括充电盒以及与充电盒相配对的耳机,其特征在于:所述充电盒上设有接收语音和/或噪音的麦克风阵列、ai声源定位及波束形成算法处理器、语音提取放大器,所述麦克风阵列的输出端与ai声源定位及波束形成算法处理器的输入端相连,所述ai声源定位及波束形成算法处理器的输出端与语音提取放大器的输入端相连,所述语音提取放大器的输出端通过蓝牙与耳机通信,波束形成算法处理器执行如权利要求1-3任意一项所述的方法。
27、优选地,所述的一种辅听设备,其特征在于:所述麦克风阵列包括若干麦克风,若干麦克风组成立体排列的柱状结构,且每个麦克风与相邻麦克风之间等距间隔设置。
28、优选地,所述的一种辅听设备,所述麦克风设有8个。
29、优选地,所述的一种辅听设备,所述耳机上麦克风的声源信号传输至ai声源定位及波束形成算法处理器内。
30、借由上述方案,本发明至少具有以下优点:
31、1、本发明能让开放式tws声学系统声音还原能力得到大幅度提升。实现高保真音质还原,有效提高音质。
32、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
技术特征:1.一种基于ai模型语音增强的方法,其特征在于,
2.根据权利要求1所述的一种基于ai模型语音增强的方法,其特征在于:在目标响应矩阵f,决定固定波束形成结构针对人生声源的语音信号进行保留。
3.根据权利要求1所述一种基于ai模型语音增强的方法,其特征在于:在目标响应矩阵f,决定固定波束形成结构针对噪声声源的语音信号进行抑制。
4.一种基于ai模型语音增强的装置,其特征在于,麦克风阵列(3),用于收集噪音和语音;
5.根据权利要求4所述的一种基于ai模型语音增强的装置,其特征在于:麦克风阵列(3)包括若干麦克风,若干麦克风组成立体排列的柱状结构,且每个麦克风与相邻麦克风之间等距间隔设置。
6.根据权利要求5所述的一种基于ai模型语音增强的装置,其特征在于:所述麦克风设有8个。
7.一种辅听设备,包括充电盒(1)以及与充电盒相配对的耳机(2),其特征在于:所述充电盒(1)上设有接收语音和/或噪音的麦克风阵列(3)、ai声源定位及波束形成算法处理器(4)、语音提取放大器(5),所述麦克风阵列(3)的输出端与ai声源定位及波束形成算法处理器(4)的输入端相连,所述ai声源定位及波束形成算法处理器(4)的输出端与语音提取放大器(5)的输入端相连,所述语音提取放大器(5)的输出端通过蓝牙(6)与耳机通信,波束形成算法处理器(4)执行如权利要求1-3任意一项所述的方法。
8.根据权利要求7所述的一种辅听设备,其特征在于:所述麦克风阵列(3)包括若干麦克风,若干麦克风组成立体排列的柱状结构,且每个麦克风与相邻麦克风之间等距间隔设置。
9.根据权利要求7所述的一种辅听设备,其特征在于:所述麦克风设有8个。
10.根据权利要求7所述的一种辅听设备,其特征在于:所述耳机(2)上麦克风的声源信号传输至ai声源定位及波束形成算法处理器(4)内。
技术总结本发明涉及一种基于AI模型语音增强的方法及其装置和辅听设备,包括充电盒以及与充电盒相配对的耳机,所述充电盒上设有接收语音和/或噪音的麦克风阵列、AI声源定位及波束形成算法处理器、语音提取放大器,所述麦克风阵列的输出端与AI声源定位及波束形成算法处理器的输入端相连,所述AI声源定位及波束形成算法处理器的输出端与语音提取放大器的输入端相连,所述语音提取放大器的输出端通过蓝牙与耳机通信。本发明能提高音质,提高使用者的清晰度。技术研发人员:耿汉诚,陈道,张迎升受保护的技术使用者:苏州智为欣声学科技有限公司技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240801/244000.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表