双耳听力系统的自适配方法与流程
- 国知局
- 2024-08-02 12:43:21
本发明涉及双耳听力系统的自适配方法。
背景技术:
1、提供听力损失补偿和言语增强的非处方听力设备(例如,不用处方的(otc)助听器或消费者耳塞)的可用性和传播预计将在未来几年大幅增长(参见leslie,m.的“new usrules promise to unlock hearing aid availability”(engineering,2022年,第14卷,第7期,第7-9页)。由于没有听力保健专业人员参与这些设备的适配,一个突出的挑战是确保以相关和令人满意的方式为用户提供设备声音处理能力的调谐。这个流程被称为“自适配”。已知多种自适配原理。
2、根据一个示例,提供纯音听力测试并相应地计算增益和压缩曲线;这在appleairpods pro、jabra enhance plus和nuheara iqbuds2 max等商用设备中均可使用。
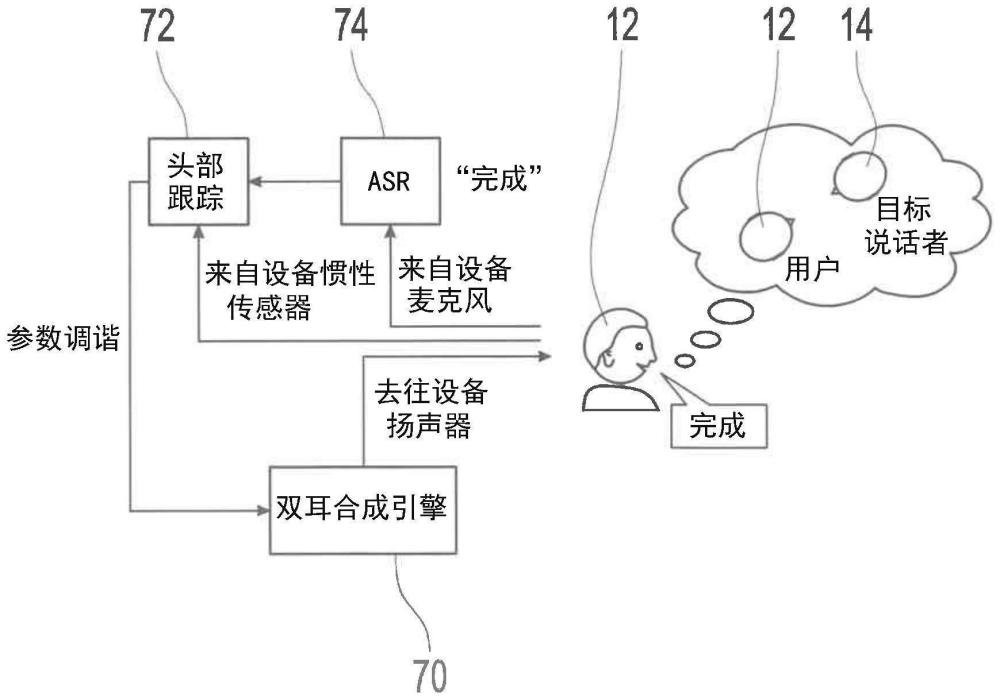
3、根据wo2020/214482a1,向助听器的用户提供问卷,从问卷中导出分数并将该分数映射到纯音平均值和言语识别表现。
4、根据us2019/0166440a1,将通过不同声音处理修改的两个刺激呈现给助听器的用户,并且请求用户指示偏好;这个流程是迭代进行的,直到它收敛到一个最优和个人适配条件为止。
5、根据us2022/191625a1,在没有声音的显示器上向助听器的用户显示多种环境情况,使得用户能够对相关性进行评级并报告在每个场景中遇到的听力困难;听力损失等级与每种情况相关联,这会操控助听器的适配。
6、根据us2017/0070833a1,将来自适配声景的音频信号以大声级和轻声级呈现给助听器的用户,并且基于用户对助听器的输出的感知评估在原位执行适配。
7、根据us2021/243535a1,合成并更改言语样本以测试或优化听力设备参数。
8、wo2005/018275a2涉及听力设备的适配,其中,将包括语义的言语音频样本呈现给用户以供用户识别,然后用户复述所识别的句子/单词/音节;系统可以测试用户自己的言语生成。在wo2010/117712a2中描述了一种类似的适配方法,其中,可以将例如包括vcv无意义单词的刺激发送给用户并且测量用户的反应。
9、根据wo2008/025858a2,听力保健专业人员根据用户对经由听力系统再现的来自现实生活声源的音频序列的空间感知的反馈来调整听力系统的参数设置;另外,可以与音频序列同步地向用户提供所述音频序列所属场景的可视化。
10、ep3930350a1描述了虚拟环境的声学表示,该虚拟环境可以包括多个源,例如,多人说话,这些源都可以被表示为使得他们的位置能够被真实地感知。
11、us2014/241537a描述了听力设备用户检测例如不同音素之间的转变以指示听力表现。
12、us2018/0227690a1涉及一种为与手持便携式电子设备耦合的耳机生成空间音频信号的方法,其中,确定手持便携式电子设备相对于用户的位置坐标并将该位置保存为语音定位点。在电话呼叫期间,另一个人的声音被卷积,因此该语音在声音定位点处作为双耳声音从外部定位到这个人。
技术实现思路
1、本发明的目的是提供一种双耳听力系统的自适配方法,该方法允许基本上保持用户的空间声音识别能力。另外的目的是提供对应的自适配装置。
2、根据本发明,这些目的通过权利要求1中定义的方法和权利要求15中定义的装置来实现。
3、本发明的有益之处在于,通过使用双耳听力系统的运动传感器在适配过程中监测用户的空间声音识别能力,能够容易地识别某些适配配置对用户的空间声音识别能力的负面影响,使得能够例如通过排除这种有害的适配配置来保持用户的空间声音识别能力。
4、根据一个示例,可以针对不同的适配配置迭代进行所述方法,以便通过使预期的头部移动与所测量的头部移动之间的偏差最小化来优化关于所述用户的空间声音识别能力的适配配置。
5、根据一个示例,所述虚拟听觉场景可以包括被布置在相对于所述用户的第二角度位置处的第二音频源,其中,指导所述用户将所述头部转向所述第二音频源,其中,所述用户的所述相应头部移动是经由所述至少一个运动传感器测量的,并且其中,所述用户在所述听力系统的所述当前适配配置下的空间声音识别能力是根据所测量的头部移动来估计的。例如,所述第一音频源可以是目标说话者,并且所述第二音频源可以是竞争说话者。另外,所述虚拟听觉场景可以包括扩散噪声。
6、根据一个示例,所述虚拟听觉场景的参数可以被改变以执行不同的头部移动测量,所述参数特别是所述第一音频源和/或所述第二音频源的水平、距离和/或偏航角和/或扩散噪声的水平。
7、根据一个示例,可以经由由所述双耳听力系统再现的指令音频信号指导所述用户。
8、根据一个示例,所述用户可以提供对所述指令音频信号的语音反馈,所述语音反馈是经由自动言语识别来识别的。例如,自动言语识别可以从限于不超过200个单词的数据库中识别单词。另外,所述听力设备中的每个听力设备可以包括用于捕捉所述用户的语音反馈的麦克风装置。例如,捕捉所述用户的语音反馈可以利用声学波束形成和/或基于用户语音的先前记录的言语特征提取。所述双耳听力系统可以将表示所述用户的语音反馈的音频信号传输到执行所述自动言语识别的附件设备。所述指令音频信号可以包括由所述第一音频源呈现的关键词,其中,可以指导所述用户重复所述关键词,并且其中,所述语音反馈可以包括所述用户对所述关键词的所述重复。
9、根据一个示例,在开始测量头部移动之前,所述用户可以经历校准过程以提供针对所述头部移动的绝对参考。
10、根据一个示例,所述至少一个运动传感器可以包括所述第一听力设备中的第一惯性传感器和所述第二听力设备中的第二惯性传感器。例如,所述第一惯性传感器和所述第二惯性传感器可以包括加速度计和/或陀螺仪。另外,每个听力设备可以包括用于辅助所述惯性传感器的磁力计。
11、根据一个示例,可以通过使用默认的一组头部相关的传递函数(hrtf)来生成空间化双耳音频信号。根据另一示例,可以通过使用从多个预先设置中选择的一组通用hrtf而使得所述一组通用hrtf与所述用户的感知最佳匹配来生成空间化双耳音频信号。根据另外的示例,可以通过使用利用附件设备和由所述用户佩戴的所述双耳听力系统测量的一组hrtf来生成空间化双耳音频信号。
12、根据一个示例,所述适配配置的适配参数可以包括宽动态范围压缩量,所述宽动态范围压缩量是通过压缩拐点、波束形成器模式、噪声降低量和/或混响降低量来确定的。
13、根据一个示例,以下操作可以是在与双耳听力系统通信性耦合的附件设备上执行的:生成表示所述虚拟听觉场景的所述空间化双耳音频信号;根据所测量的头部移动来估计所述用户在所述听力系统的所述当前适配配置下的空间声音识别能力;和/或基于所估计的用户在所述当前适配配置下的空间声音识别能力来评估所述当前适配配置。例如,所述附件设备可以是智能手机。
14、在从属权利要求中定义了本发明的优选实施例。
本文地址:https://www.jishuxx.com/zhuanli/20240802/237526.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
手持式电子设备的制作方法
下一篇
返回列表