基于自然语言处理的评论生成方法与流程
- 国知局
- 2024-08-05 12:04:55
本发明涉及汽车评论生成,尤其涉及基于自然语言处理的评论生成方法。
背景技术:
1、文本生成评论是当前一个很棘手的问题,这些都是因为语言表达的多样性,比如在使用cvae生成商品的描述时,同一种文本条件,能够生成多条含义接近的语句。生成质量不稳定:生成的评论质量可能不稳定,有时可能会产生不连贯、不准确或不相关的评论。在现有的评论生成方法中,存在以下技术问题:
2、缺乏多样性:现有方法通常缺乏多样性,往往生成相似内容;
3、数据依赖性:生成评论方法对大量高质量的训练数据依赖较大,如果训练数据不足或质量较差,可能会影响生成评论的质量;
4、缺乏情感表达:现有方法在捕捉用户情感倾向方面可能存在一定的挑战,导致生成的评论缺乏情感色彩;
5、难以处理复杂领域:对于复杂的领域,如汽车领域,现有方法可能无法准确理解和生成与该领域相关的评论。
技术实现思路
1、基于上述问题,本发明提出了基于自然语言处理的评论生成方法,解决汽车领域评论生成无法准确理解和生成与该领域相关的评论的问题,具体技术方案如下。
2、基于自然语言处理的评论生成方法,包括以下步骤:
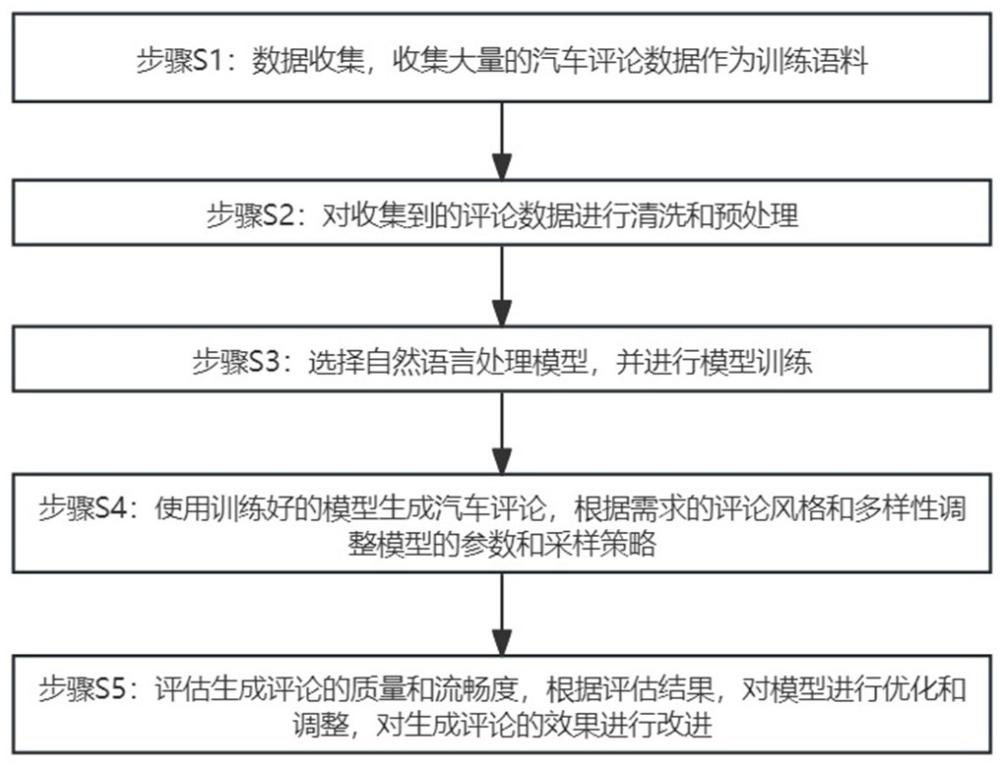
3、步骤s1:数据收集,收集大量的汽车评论数据作为训练语料;
4、步骤s2:对收集到的评论数据进行清洗和预处理;
5、步骤s3:选择自然语言处理模型,并进行模型训练;
6、步骤s4:使用训练好的模型生成汽车评论,根据需求的评论风格和多样性调整模型的参数和采样策略;
7、步骤s5:评估生成评论的质量和流畅度,根据评估结果,对模型进行优化和调整,对生成评论的效果进行改进。
8、进一步,所述步骤s2数据清洗和预处理包括:去除噪声、标记句子边界、分词和词性标注。
9、进一步,所述步骤s3模型训练包括以下步骤:
10、步骤s31:对于原始文本进行分类,使用无监督关键词提取算法yake从原始文本中提取关键词和关键短语;
11、步骤s32:将提取到的关键词和关键短语采用mixup方式,进行数据增强;
12、步骤s33:增强后的数据投影到原始文本并进行掩码处理,得到masking后的数据;
13、步骤s34:使用双向编码器和自回归解码器进行文本重建。
14、进一步,所述步骤s31关键词提取包括以下步骤:
15、步骤s311:对原始文本进行预处理,包括分句、分词和去除停用词;
16、步骤s312:使用连续n个词作为关键词的候选项,并为每个候选项计算一组特征;
17、步骤s313:yake算法使用表征和位置特征,表征基于词频、逆文档频率和位置信息计算得出,衡量候选词在文本中的重要性;位置特征用于标识候选词在文本中的位置分布;
18、步骤s314:在特征计算完成后,yake算法使用表征和位置特征作为输入,将关键词提取任务转化为一个二元分类问题;
19、步骤s315:训练一个简单的机器学习模型,模型根据候选词的特征来预测其是否是关键词,通过对所有候选词进行分类,yake算法最终确定文本中的关键词。
20、进一步,所述步骤s32数据增强包括:eda数据增强方法、backtrans数据增强方法、mlm数据增强方法、c-mlm数据增强方法、lambada数据增强方法、sta数据增强方法和geniusaug数据增强方法。
21、进一步,所述双向编码器和自回归解码器包括以下组成部分:
22、词嵌入层:输入的文本转换为词嵌入;
23、上下文嵌入层:包括多层自我注意机制和全连接层,根据词语的上下文信息,将信息融入到词嵌入中,形成上下文嵌入;
24、多头注意力层:在自我注意机制中,将输入的上下文信息嵌入分割成多个部分,并对每个部分进行attention计算;然后,将计算结果合并起来,形成一个完整的attention;
25、全连接层:提取更高级的语义信息,连接一个relu激活函数和一个dropout层防止过拟合;
26、transformer层:将多个transformer的encoder层堆叠在一起,捕捉输入文本中的深层次语义信息。
27、进一步,所述步骤s5对模型进行优化和调整利用汽车行业语料库实现,包括以下子步骤:
28、步骤s51:对汽车行业语料库进行数据清洗得到纯文本的评论,借助文本分类和情感分析技术对文本进行标准化处理,得到一个不带有冒犯性和不雅评论的数据集;
29、步骤s52:对数据集进行打标,标签包括:外观,质量和动力,得到含有内容和标签的数据格式;
30、步骤s53:根据处理后的语料库对预训练模型进行微调,得到更适合汽车行业的模型;
31、步骤s54:使用训练好的模型生成汽车评论,输入可以为汽车的描述及特征,模型根据学习到的语言模式和上下文生成相应的评论文本。
32、进一步,所述步骤s5数据评估方式包括:使用人工评估和自动评估指标来衡量生成评论与真实评论之间的相似度和质量。
33、本发明的有益效果:本发明提出了基于自然语言处理的评论生成方法,用经过预训练和微调之后的模型生成评论,现在只需要对模型输入用户需要的关键词,例如某个车型或一些描述性关键词,即可生成一句完整的评论,具有以下技术优势:
34、数据集丰富:收集更多丰富、多样化的汽车评论数据,包括不同车型、不同用户的评论,以提高模型的训练效果和生成质量。
35、情感分析:引入情感分析技术,使评论生成方法能够更准确地捕捉用户对汽车的情感倾向,从而生成更具有情感色彩的评论。
36、语义一致性:确保生成的评论在语义上与汽车领域相关,避免出现不相关或错误的描述。
37、用户个性化:考虑用户的个性化需求和偏好,通过个性化的评论生成方法,为不同用户提供符合其口味和需求的评论。
38、用户参与:鼓励用户参与评论生成过程,例如通过用户反馈、评分等方式,以提高评论生成的准确性和用户满意度。
技术特征:1.基于自然语言处理的评论生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s2数据清洗和预处理包括:去除噪声、标记句子边界、分词和词性标注。
3.根据权利要求1所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s3模型训练包括以下步骤:
4.根据权利要求3所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s31关键词提取包括以下步骤:
5.根据权利要求3所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s32数据增强包括:eda数据增强方法、backtrans数据增强方法、mlm数据增强方法、c-mlm数据增强方法、lambada数据增强方法、sta数据增强方法和geniusaug数据增强方法。
6.根据权利要求3所述的基于自然语言处理的评论生成方法,其特征在于,所述双向编码器和自回归解码器包括以下组成部分:
7.根据权利要求1所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s5对模型进行优化和调整利用汽车行业语料库实现,包括以下子步骤:
8.根据权利要求7所述的基于自然语言处理的评论生成方法,其特征在于,所述步骤s5数据评估方式包括:使用人工评估和自动评估指标来衡量生成评论与真实评论之间的相似度和质量。
技术总结本发明公开了基于自然语言处理的评论生成方法,包括以下步骤:步骤S1:数据收集,收集大量的汽车评论数据作为训练语料;步骤S2:对收集到的评论数据进行清洗和预处理;步骤S3:选择自然语言处理模型,并进行模型训练;步骤S4:使用训练好的模型生成汽车评论,根据需求的评论风格和多样性调整模型的参数和采样策略;步骤S5:评估生成评论的质量和流畅度,根据评估结果,对模型进行优化和调整,对生成评论的效果进行改进。本方案针对汽车领域,用经过训练和微调之后的模型生成评论,只需要对模型输入用户需要的关键词,例如某个车型或一些描述性关键词,即可生成一句完整的评论。技术研发人员:朱洪霖,吕丹辉,杜颖,金光勋,肖峰受保护的技术使用者:启明信息技术股份有限公司技术研发日:技术公布日:2024/8/1本文地址:https://www.jishuxx.com/zhuanli/20240802/260991.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。