一种光学全连接神经网络装置及其工作方法
- 国知局
- 2024-08-05 12:11:41
本发明属于人工智能领域,具体涉及一种用于进行深度卷积神经网络机器学习的光学全连接神经网络装置及其工作方法。
背景技术:
1、深度学习是机器学习和人工智能研究的最新趋势之一。它也是当今最流行的科学研究趋势之一。深度学习方法为计算机视觉和机器学习带来了革命性的进步。新的深度学习技术正在不断诞生,超越最先进的机器学习甚至是现有的深度学习技术。近年来,全世界在这一领域取得了许多重大突破。深度学习是从机器学习和人工神经网络的中衍生出来的一个主要方法,而人工神经网络是深度学习最常用的形式。卷积神经网络是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。一个卷积神经网络主要由以下5层组成:数据输入层、卷积计算层、激励层、池化层和全连接层。其中全连接层是卷积神经网络最后的一步,经过卷积计算后得到的所有特征在全连接层与所有输出建立神经网络连接。
2、基于中央计算器(cpu)的全连接神经网络运算,每次只能进行一条指令,因此神经网络参数载入、依次做乘法、存储后再加法求和,整个计算过程需要大量的重复指令,消耗计算能源和时间。因此为了提高速度,可以在硬件上采用基于图形处理器(gpu)的并行计算方法,利用其大存储容量和多核提高速度。
3、虽然gpu计算可以大幅提高卷积计算速度,但是仍然需要将大量待计算的数据通过cpu进行整理并传输到gpu,同样计算结果还需传输回cpu进行下一轮计算准备。因此现有的计算依然是基于cpu+gpu方式,需要大吞吐量计算通道,计算速度受限,能耗巨大。
技术实现思路
1、技术问题:鉴于现有技术中的上述缺陷或不足,本发明旨在提供一种用于进行深度卷积神经网络机器学习的光学全连接神经网络装置及其工作方法,利用光学原理进行全连接神经网络计算,提高计算速度的同时降低计算所需功耗。
2、技术方案: 为实现上述功能,本发明的一种光学全连接神经网络装置如下:
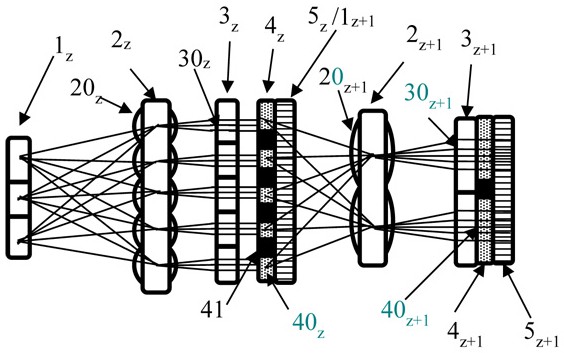
3、该装置具体包括顺序排列的显示模块、全连接模块、权重模块、积分模块;所述显示模块为单色显示模块,显示容量为r×c,r为单色显示模块的行,c为单色显示模块的列;全连接模块包括m×n个复眼透镜阵列的光学平板或多块平板组合;权重模块为光学掩膜板,包括若干个m×n图案阵列,每个图案包括r×c个子像素;积分模块由均光板阵列构成,均光板对应图案的相邻单元有光隔离装置。
4、采用多个光学全连接神经网络装置并行组合,每个装置的显示模块分别显示待处理信号的不同通道,并行处理光学神经网络连接。
5、所述显示模块为液晶显示器、微发光二极管显示器、有机发光二极管显示器、数字微镜显示器、硅基液晶显示器或投影显示器。
6、所述全连接模块、权重模块和积分模块的材料为玻璃、石英无机材料,或聚甲基丙烯酸甲酯、聚碳酸酯、 聚对苯二甲酸乙二醇脂、 聚丙烯、聚苯乙烯、 聚氯乙烯、丙烯腈/丁二烯/苯乙烯共聚物、热塑性聚氨酯弹性体橡胶、聚酰亚胺、聚苯乙烯、 聚砜、聚二酸二胺有机材料,或以上述两种有机材料的复合材料,复合的形式为单层或多层层合。
7、显示模块为前序光学系统的输出。
8、该装置基于2层全连接神经网络,包括输入层、隐藏层构成的第一层和隐藏层、输出层构成的第二层,其中输入层包括输入量x(x1,x2,…xj)、隐藏层包括h个的神经元,输出层包括由k个神经元组成的输出量o(o1,o2,…ok),隐藏层的每个神经元都与输入量x和输出量o中的神经元相连,建立了2层全连接神经网络,通过每个神经元的权重和偏置建立输入、输出之间的内在联系;为了方便光学处理,将输入量、隐藏层和输出量转成二维矩阵形式,其尺寸分别为r×c≥j、m×n≥h、p×q≥k;其中,r为输入层的行,c为输入层的列,j为输入量的个数,m 为隐藏层的行,n为隐藏层的列,h 为隐藏层神经元数,p 为输出层的行,q为输出层的列,k为输出量的个数。
9、采用多个光学全连接神经网络装置串行组合,每个光学全连接神经网络装置的第z个积分模块经过第z个非线性处理模块处理后同时作为后续装置的第z个显示模块串行多次处理光学全连接神经网络。
10、本发明的一种光学全连接神经网络装置的工作方法具体如下:
11、步骤一:显示模块显示待处理信号的r×c图像;
12、步骤二:根据复眼透镜的焦距,通过调整显示模块、全连接模块和权重模块之间的距离,使显示模块显示的r×c图像通过全连接模块复制m×n个r×c实像至权重模块对应的m×n个r×c权重图案的位置上,复制移像的尺寸与位置与每一个权重图案对应重合;
13、步骤三:复制移像后的图像块经过权重图案后,投射到积分模块表面进行光学积分并显示光学全连接神经网络积分结果。
14、本发明的一种光学全连接神经网络装置及其工作方法法具体如下,取z大于等于1:
15、步骤一:第z个显示模块显示待处理信号的r×c图像;
16、步骤二:根据第z个复眼透镜的焦距,通过调整第z个显示模块、第z个全连接模块和第z个权重模块之间的距离,使第z个显示模块显示的r×c图像通过第z个全连接模块复制m×n个r×c实像至第z个权重模块对应的m×n个r×c第z个权重图案的位置上,复制移像的尺寸与位置与每一个第z个权重图案对应重合;
17、步骤三:复制移像后的图像块经过第z个权重图案后,投射到第z个积分模块表面进行光学积分并显示第z个积分结果;
18、步骤四:根据第z个复眼透镜的焦距,通过调整第z个非线性处理模块、第z+1个全连接模块和第z+1个权重模块之间的距离,使第z个积分结果经过第z个非线性处理模块后,显示的m×n图像通过第z+1个全连接模块复制p×q个m×n实像至第z+1个权重模块对应的p×q个m×n第z+1个权重图案的位置上,复制移像的尺寸与位置与每一个第z+1个权重图案对应重合;
19、步骤五:复制移像后的图像块经过第z+1个权重图案后,投射到第z+1个积分模块表面进行光学积分并显示第z+1个积分结果;
20、步骤六:第z+1个积分结果经过第z+1个非线性处理模块后显示第z+1层全连接神经网络结果。
21、有益效果: 相对于现有技术,本发明的优点如下:
22、1、复眼透镜阵列替代传统卷积计算中的窗口滑动,利用制作了卷积核阵列的光学掩模版和均光板实现光学卷积,大幅提高计算速度。
23、2、卷积计算过程没有数据的高速传输,更加节能。
技术特征:1.一种光学全连接神经网络装置,其特征在于该装置具体包括顺序排列的显示模块(1)、全连接模块(2)、权重模块(3)、积分模块(4);所述显示模块(1)为单色显示模块,显示容量为r×c,r为单色显示模块的行,c为单色显示模块的列;全连接模块(2)包括m×n个复眼透镜(20)阵列的光学平板或多块平板组合;权重模块(3)为光学掩膜板,包括若干个m×n图案(30)阵列,每个图案(30)包括r×c个子像素(300);积分模块(4)由均光板(40)阵列构成,均光板(40)对应图案(30)的相邻单元有光隔离装置(41)。
2.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于采用多个所述光学全连接神经网络装置并行组合,每个装置的显示模块(1)分别显示待处理信号的不同通道,并行处理光学神经网络连接。
3.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于所述显示模块(1)为液晶显示器、微发光二极管显示器、有机发光二极管显示器、数字微镜显示器、硅基液晶显示器或投影显示器。
4.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于所述全连接模块(2)、权重模块(3)和积分模块(4)的材料为玻璃无机材料,或聚甲基丙烯酸甲酯、聚碳酸酯、聚对苯二甲酸乙二醇脂、 聚丙烯、聚苯乙烯、 聚氯乙烯、丙烯腈/丁二烯/苯乙烯共聚物、热塑性聚氨酯弹性体橡胶、聚酰亚胺、聚苯乙烯、 聚砜、聚二酸二胺有机材料,或以上述两种有机材料的复合材料,复合的形式为单层或多层层合。
5.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于所述显示模块(1)为前序光学系统的输出。
6.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于该装置基于2层全连接神经网络,包括输入层、隐藏层构成的第一层,隐藏层、输出层构成的第二层,其中输入层包括输入量x(x1,x2,…xj)、隐藏层包括h个的神经元,输出层包括由k个神经元组成的输出量o(o1,o2,…ok),隐藏层的每个神经元都与输入量x和输出量o中的神经元相连,建立了2层全连接神经网络,通过每个神经元的权重和偏置建立输入、输出之间的内在联系;将输入量、隐藏层和输出量转成二维矩阵形式,其尺寸分别为r×c≥j、m×n≥h、p×q≥k;其中,r为输入层的行,c为输入层的列,j为输入量的个数,m 为隐藏层的行,n为隐藏层的列,h 为隐藏层神经元数,p 为输出层的行,q为输出层的列,k为输出量的个数。
7.根据权利要求1所述的一种光学全连接神经网络装置,其特征在于采用多个光学全连接神经网络装置串行组合,每个光学全连接神经网络装置的第z个积分模块4z经过第z个非线性处理模块5 z处理后同时作为后续装置的第z+1个显示模块1z+1串行多次处理光学全连接神经网络。
8.一种如权利要求1、2、3或4所述的一种光学全连接神经网络装置的工作方法,其特征在于该工作方法具体如下:
9.一种如权利要求5、6或7所述的一种光学全连接神经网络装置的工作方法,其特征在于该工作方法具体如下,取z大于等于1:
技术总结本发明公开了一种光学全连接神经网络装置及其工作方法,所述装置包括光学输入模块、光学全连接移像模块、光学滤波模块和光学积分模块。通过光学全连接移像模块将输入模块的光学图像复制并平移至光学滤波模块前,经过包括特定图案阵列的光学滤波模块进行神经元的权重,投射到积分模块表面进行光学积分。通过光学全连接神经网络装置对深度学习神经网络进行光学信号处理,可以大幅提高处理速度,降低功耗。技术研发人员:仲雪飞,张雄,樊兆雯,苏志成受保护的技术使用者:东南大学技术研发日:技术公布日:2024/8/1本文地址:https://www.jishuxx.com/zhuanli/20240802/261463.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表