基于交流重复率的多读写器标签盘点方法、装置及设备
- 国知局
- 2024-08-05 12:17:15
本发明涉及rfid(radio frequency identification,射频识别)标签盘点,具体涉及一种基于交流重复率的多读写器标签盘点方法、装置及设备。
背景技术:
1、随着射频识别技术(rfid,radio frequency identification)日渐趋于成熟,越来越多地应用在身份识别、仓库管理、物流管理等众多领域中,用于实现物品的位置确定和状态识别。一个简单的rfid系统基本包含一个服务器、一个读写器、大量标签三部分,读写器通过无线射频的方式与标签进行数据通信,并将标签响应的结果实时发送给服务器。随后,服务器对读写器的待识别标签列表进行更新,直至所有标签被识别。rfid技术在安全性、效率、使用寿命以及成本等方面都具有显著优势。
2、但是随着时代的发展、消费力的提升,仓库管理和物流管理中物品的数目大幅上升,使用单个读写器可能不足以覆盖整个区域,并且单读写器随着标签数目的增加其盘点所消耗的时间也同步增加,因此通常需要部署若干个读写器来覆盖整个识别区域,且读写器间可进行交流推断来提高盘点效率。在交流过程中,可能存在这样一种情况:某一读写器识别的存在标签在被交流给其他非相邻读写器作为丢失标签时,在之前轮次的盘点中此标签已经被识别为丢失了,导致无效的交流,影响识别效率,我们称这种现象为交流重复。
技术实现思路
1、针对现有技术中存在的缺陷,本发明的目的在于提供一种基于交流重复率的多读写器标签盘点方法、装置及设备,能够解决现有技术中某一读写器识别的存在标签在被交流给其他非相邻读写器作为丢失标签时,在之前轮次的盘点中此标签已经被识别为丢失了,导致无效的交流,影响识别效率的问题。
2、为达到以上目的,本发明采取的技术方案是:
3、一方面,本发明提供一种基于交流重复率的多读写器标签盘点方法,包括以下步骤:
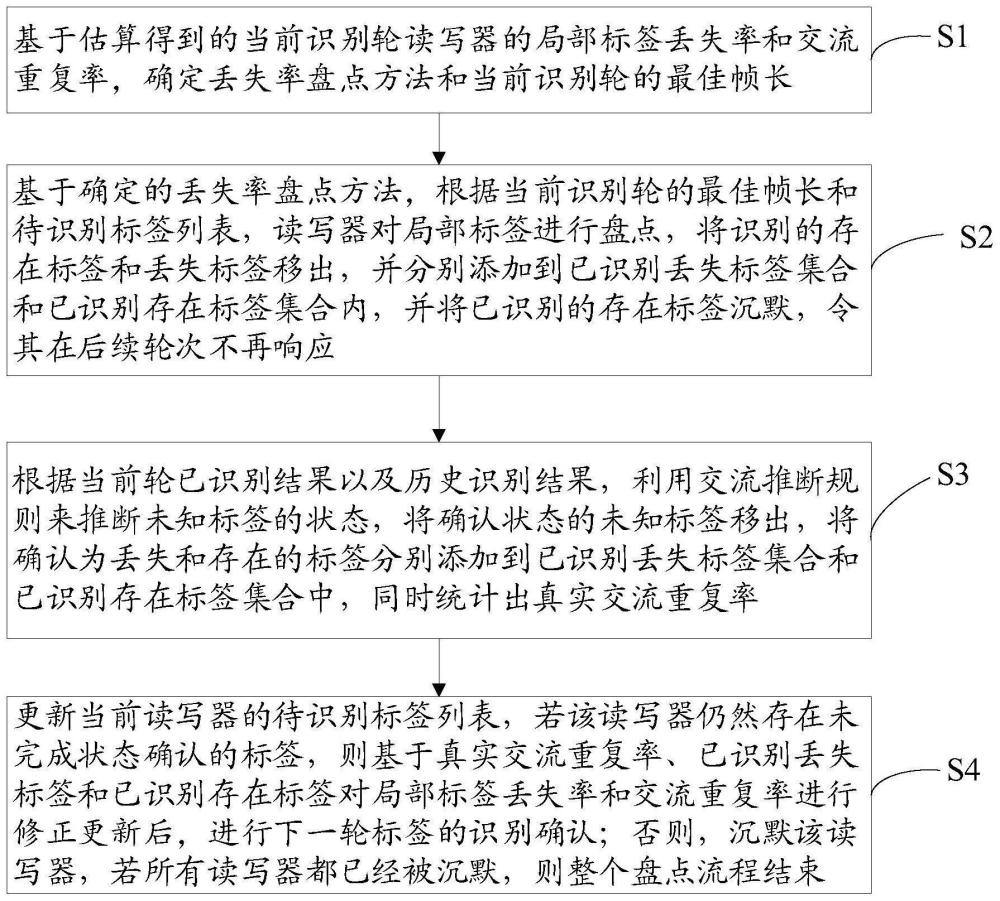
4、基于估算得到的当前识别轮读写器的局部标签丢失率和交流重复率,确定丢失率盘点方法和当前识别轮的最佳帧长;
5、基于确定的丢失率盘点方法,根据当前识别轮的最佳帧长和待识别标签列表,读写器对局部标签进行盘点,将识别的存在标签和丢失标签移出,并分别添加到已识别丢失标签集合和已识别存在标签集合内,并将已识别的存在标签沉默,令其在后续轮次不再响应;
6、根据当前轮已识别结果以及历史识别结果,利用交流推断规则来推断未知标签的状态,将确认状态的未知标签移出,将确认为丢失和存在的标签分别添加到已识别丢失标签集合和已识别存在标签集合中,同时统计出真实交流重复率;
7、更新当前读写器的待识别标签列表,若该读写器仍然存在未完成状态确认的标签,则基于真实交流重复率、已识别丢失标签和已识别存在标签对局部标签丢失率和交流重复率进行修正更新后,进行下一轮标签的识别确认;否则,沉默该读写器,若所有读写器都已经被沉默,则整个盘点流程结束。
8、在一些可选的方案中,所述的基于估算得到的当前识别轮读写器的局部标签丢失率和交流重复率,确定丢失率盘点方法和当前识别轮的最佳帧长,包括:
9、基于估算得到的当前识别轮读写器的局部标签丢失率和交流重复率,分别获取低局部丢失率盘点方法和高局部丢失率盘点方法对应的盘点效率;
10、选择低局部丢失率盘点方法和高局部丢失率盘点方法对应盘点效率最大值的较大者作为丢失率盘点方法,同时推导计算对应的最佳帧长。
11、在一些可选的方案中,根据公式获取高局部丢失率盘点方法对应的盘点效率
12、根据公式获取低局部丢失率盘点方法对应的盘点效率
13、通过对上式中的ρ求导得到和取得最大值时对应的负载因子ρopt值,同时获得该轮识别的最佳帧长fopt=|cti,d|/ρopt;
14、其中,ρ为中间量,ρ=|cti,d|/f,d为当前识别轮次序号,i为读写器序号,pi,d为第i个读写器在第d轮识别的估算局部标签丢失率,εi,d为第i个读写器在第d轮识别的估算交流重复率,cti,d为第d轮识别开始前读写器i的待识别标签列表大小,f为待求最佳帧长,e为自然常数,l为当前活跃的读写器总数,ttag为标签将其id响应给读写器的时间消耗,tshort为标签响应读写器,读写器可根据此响应判断此时隙是否存在标签所需的时间消耗。
15、在一些可选的方案中,若采用高局部丢失率盘点方法,对局部标签进行盘点,包括:
16、服务器生成第一随机数种子,根据最佳帧长以及读写器i在第d轮识别前的待识别标签列表,基于标签中的哈希函数以及标签的id计算各个标签在帧中回复的时隙,统计各个时隙内预期回复的标签数目,对空时隙、单标签时隙以及两个及以上标签回复的时隙标记后得到期望向量;
17、读写器将第一随机数种子、最佳帧长和期望向量广播给其覆盖范围内的标签,标签接收到这些参数后,通过各个标签自身id以哈希函数计算映射到期望向量中的索引值,计算此索引前非空时隙的个数z,并在第z+1个时隙内进行响应;
18、读写器接收其覆盖范围内所有标签的响应信息,与期望向量比对,若单标签时隙内存在回复,则此标签存在;否则,此标签丢失;若多标签时隙内存在回复,无法确定标签的状态,在后续轮次继续识别;否则,此时隙内所有的标签均丢失,完成识别后,读写器将识别的存在标签和丢失标签移出待识别标签列表,分别添加到已识别丢失标签集合和已识别存在标签集合内,并将识别的存在标签沉默,令其在后续轮次不再响应。
19、在一些可选的方案中,若采用低局部丢失率盘点方法,对局部标签进行盘点,在基于高局部丢失率盘点方法的基础上,还包括:
20、在统计各个时隙内预期回复的标签数后,对于两个及以上标签回复的时隙,生成第二随机数种子,令时隙内所有标签通过哈希函数、标签id以及第二随机数种子对时隙内的标签数目进行取模,对该标签进行二次哈希函数计算,若各个标签所得余数各不相同,则此时隙为二次哈希单标签时隙,对空时隙、单标签时隙、二次哈希单标签时隙、其余两个及以上标签回复的时隙标记后得到期望向量;
21、读写器将第一随机数种子、第二随机数种子、最佳帧长和期望向量广播给其覆盖范围内的标签,当标签接收到这些参数后,通过标签自身id以哈希函数计算映射到期望向量中的索引,若映射到单标签时隙中,计算此索引前单标签时隙或二次哈希单标签时隙的个数z,并在第z+1个时隙内进行响应,若映射到二次哈希单标签时隙,进一步计算二次哈希余数,值为0时与单标签时隙一样进行回复,如果值不为0标签会在所有单标签时隙和二次哈希单标签时隙后依次响应;
22、读写器判断标签状态时,二次哈希单标签时隙与单标签时隙处理相同,完成识别后,将识别的标签移出待识别标签列表,分别添加到已识别丢失标签集合和已识别存在标签集合中,并将识别的存在标签沉默,令其在后续轮次不再响应。
23、在一些可选的方案中,利用交流推断规则来推断未知标签的状态时,遵循以下规则:
24、对于与当前读写器i之外的读写器j识别的存在标签,读写器i将这类标签识别为丢失标签,移出待识别标签列表,并加入已识别丢失标签集合;
25、对于读写器i历史识别结果中预期的冲突时隙且真实存在标签响应的时隙,通过交流发现预期的x个标签中有x-1个已在已识别丢失标签集合中,确认剩下的那个标签存在,将其移出待识别标签列表,并加入已识别存在标签集合。
26、在一些可选的方案中,所述的基于真实的交流重复率、已识别丢失标签和已识别存在标签对局部标签丢失率和交流重复率进行修正更新,包括:
27、根据公式计算下一轮交流重复率修正比例β;
28、根据公式估算更新后第d+1轮的读写器i的交流重复率εi,d+1;
29、根据公式pi,d+1=(|cti,d|×pi,d-|vmi,d|)/(|cti,d|-|vpi,d|-|vmi,d|),估算更新后第d+1轮的读写器i的局部标签丢失率pi,d+1;
30、其中,εi,d为第d轮的读写器i的估算交流重复率,为第d轮的读写器i的真实交流重复率,l为当前活跃的读写器总数,|vmj,d|为读写器i第d轮识别的丢失标签数,|cti,d|为读写器i开始第d轮识别前,待识别标签列表的大小,|vpi,d|为读写器i第d轮识别的存在标签数,j为当前活跃的读写器的编号。
31、在一些可选的方案中,首轮识别中读写器的局部标签丢失率和交流率根据以下步骤获取:
32、运行一轮aloha方法后获得存在标签个数np和丢失标签个数nm;
33、根据公式pi,1=nm/(np+nm),确定首轮识别中读写器i的局部标签丢失率pi,1;
34、根据公式确定首轮识别中读写器i的交流重复率εi,1;
35、其中,j为当前活跃的读写器的编号,l为当前活跃的读写器总数,n为读写器i待识别标签列表的初始大小。
36、第二方面,本发明还提供一种基于交流重复率的多读写器标签盘点装置,包括:
37、方法选择模块,其用于基于当前识别轮读写器的局部标签丢失率和交流重复率,确定丢失率盘点方法和当前识别轮的最佳帧长;
38、盘点模块,其用于基于确定的丢失率盘点方法,根据当前识别轮的最佳帧长和待识别标签列表,读写器对局部标签进行盘点,将识别的存在标签和丢失标签移出,并分别添加到已识别丢失标签集合和已识别存在标签集合内,并将已识别的存在标签沉默,令其在后续轮次不再响应;
39、交流推断模块,其用于根据当前轮已识别结果以及历史识别结果,利用交流推断规则来推断未知标签的状态,将确认状态的未知标签移出,将确认为丢失和存在的标签分别添加到已识别丢失标签集合和已识别存在标签集合中,同时统计出真实交流重复率;
40、更新模块,其用于更新当前读写器的待识别标签列表,若该读写器仍然存在未完成状态确认的标签,则基于真实交流重复率、已识别丢失标签和已识别存在标签对局部标签丢失率和交流重复率进行修正更新后,进行下一轮标签的识别确认;否则,沉默该读写器,若所有读写器都已经被沉默,则整个盘点流程结束。
41、第三方面,本发明还提供一种基于交流重复率的多读写器标签盘点设备,所述基于交流重复率的多读写器标签盘点设备包括处理器、存储器、以及存储在所述存储器上并可被所述处理器执行的基于交流重复率的多读写器标签盘点程序,其中所述基于交流重复率的多读写器标签盘点程序被所述处理器执行时,实现上述任一项所述的基于交流重复率的多读写器标签盘点方法的步骤与现有技术相比,本发明的优点在于:本发明针对多读写器环境,同时考虑局部标签丢失率和交流重复率,使用基于交流重复率的标签盘点方法,通过读写器间的交流推断,无需使用时隙即可推断出一些标签的状态,从而提高识别效率;同时,基于交流重复率,对交流过程进行优化,增强交流效果。
本文地址:https://www.jishuxx.com/zhuanli/20240802/261967.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。