LLM驱动的NL2SQL转换器解决复杂表格与实体对齐的方法及系统与流程
- 国知局
- 2024-08-05 12:19:22
本发明属于语言处理,具体涉及llm驱动的nl2sql转换器解决复杂表格与实体对齐的方法及系统。
背景技术:
1、随着自然语言处理(nlp)技术的不断进步,使得从非结构化文本中提取结构化信息成为可能,其中自然语言到结构化查询语言(nl2sql)的转换尤为引人注目。nl2sql的核心任务是将人类语言表述的查询需求转化为数据库可执行的sql查询语句,这一转换过程极大地简化了用户与数据库的交互,使得查询操作更加直观和高效。
2、近年来,大型语言模型(llm)的崛起为nl2sql的研究带来了新的契机。llm通过深度学习和大量的语料库训练,具备强大的文本生成和理解能力。在nl2sql应用中,llm能够接收自然语言描述的问题,并自动生成对应的sql查询语句,从而实现对数据库中数据的精准检索。
3、然而,在实际应用中,当处理具有大量字段的复杂数据库表格时,基于llm的nl2sql转换器面临一系列技术挑战。首先,信息过载导致的模型混淆问题使得模型难以准确理解和区分每个字段的含义、作用以及它们之间的关系,其次,查询生成的效率问题影响了用户体验和系统的整体性能,此外,实体识别和映射的不确定性也使得模型难以将自然语言中的实体准确映射到正确的数据库字段。
技术实现思路
1、本发明的目的是提供llm驱动的nl2sql转换器解决复杂表格与实体对齐的方法,能够有效地解决大型语言模型在处理多字段数据库表格时的挑战和实体对齐困难的问题,提高nl2sql转换的准确性和效率。
2、本发明采取的技术方案具体如下:
3、llm驱动的nl2sql转换器解决复杂表格与实体对齐的方法,包括:
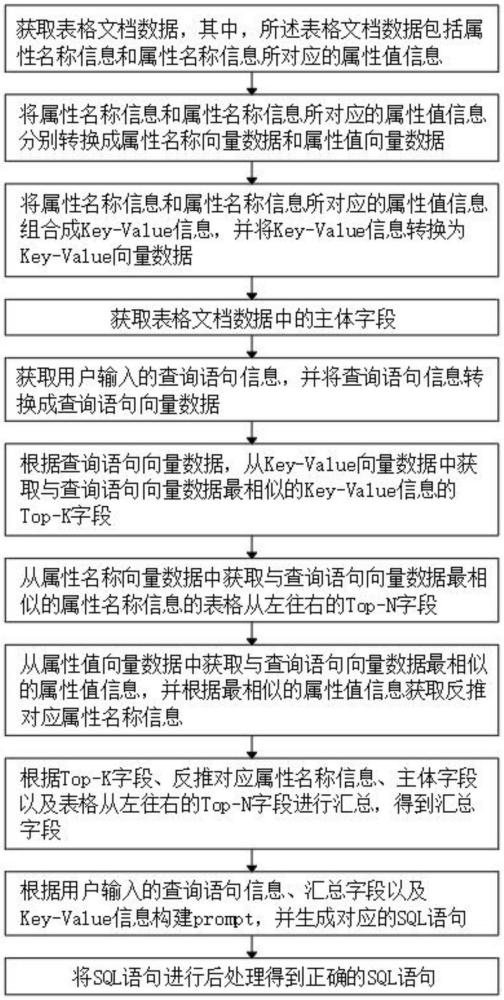
4、获取表格文档数据,其中,所述表格文档数据包括属性名称信息和属性名称信息所对应的属性值信息;
5、将属性名称信息和属性名称信息所对应的属性值信息分别转换成属性名称向量数据和属性值向量数据;
6、将属性名称信息和属性名称信息所对应的属性值信息组合成key-value信息,并将key-value信息转换为key-value向量数据;
7、获取表格文档数据中的主体字段;
8、获取用户输入的查询语句信息,并将查询语句信息转换成查询语句向量数据;
9、根据查询语句向量数据,从key-value向量数据中获取与查询语句向量数据最相似的key-value信息的top-k字段;
10、从属性名称向量数据中获取与查询语句向量数据最相似的属性名称信息的表格从左往右的top-n字段;
11、从属性值向量数据中获取与查询语句向量数据最相似的属性值信息,并根据最相似的属性值信息获取反推对应属性名称信息;
12、根据top-k字段、反推对应属性名称信息、主体字段以及表格从左往右的top-n字段进行汇总,得到汇总字段;
13、根据用户输入的查询语句信息、汇总字段以及key-value信息构建prompt,并生成对应的sql语句;
14、将sql语句进行后处理得到正确的sql语句。
15、在一种优选方案中,所述将属性名称信息和属性名称信息所对应的属性值信息组合成key-value信息,并将key-value信息转换为key-value向量数据的步骤;
16、将属性名称信息作为key信息,属性名称信息所对应的属性值信息作为value信息;
17、将key信息和key信息所对应的value信息组合成key-value信息;
18、将key-value信息转换为key-value向量数据。
19、在一种优选方案中,所述主体字段包括代表性字段和关键性字段。
20、在一种优选方案中,所述获取表格文档数据中的主体字段的步骤之后,还包括:
21、将属性名称向量数据、属性值向量数据以及key-value向量数据存入向量数据库中;
22、根据表格文档数据生成建表sql信息;
23、将建表sql信息存入mysql数据库中。
24、在一种优选方案中,所述获取用户输入的查询语句信息,并将查询语句信息转换成查询语句向量数据的步骤之后,还包括:
25、根据查询语句信息,从mysql数据库中获取建表sql信息;
26、根据建表sql信息获取对应的表字段数量;
27、判断表字段数量是否小于标准字段数量;
28、若表字段数量大于或等于标准字段数量,则判定表字段数量不符合要求,且需要进行筛选字段;
29、若表字段数量小于标准字段数量,则判定表字段数量符合要求,且标记为展示字段;
30、根据用户输入的查询语句信息、展示字段以及key-value信息构建prompt,并生成对应的sql语句。
31、在一种优选方案中,所述从属性值向量数据中获取与查询语句向量数据最相似的属性值信息,并根据最相似的属性值信息获取反推对应属性名称信息的步骤,包括:
32、将查询语句向量数据分别与多个属性值向量数据进行计算相似度,得到相似值;
33、将相似值按照从大到小的顺序进行排列,并选取相似值最大属性值向量数据所对应的属性值信息;
34、根据属性值信息获取对应的属性名称信息。
35、在一种优选方案中,所述根据用户输入的查询语句信息、汇总字段以及key-value信息构建prompt,并生成对应的sql语句的步骤,包括:
36、根据用户输入的查询语句信息、汇总字段以及key-value信息构建prompt;
37、获取大语言模型;
38、将构建prompt输入至大语言模型中,并生成对应的sql语句。
39、在一种优选方案中,所述将sql语句进行后处理得到正确的sql语句的步骤,包括:
40、从sql语句中提取属性名称信息和属性值信息;
41、判断提取的属性名称信息和属性值信息是否在表格文档数据中;
42、若提取的属性名称信息和属性值信息在表格文档数据中,则判定sql语句正确;
43、若提取的属性名称信息和属性值信息不在表格文档数据中,则判定sql语句错误,需返回至根据top-k字段、反推对应属性名称信息、主体字段以及表格从左往右的top-n字段进行汇总,得到汇总字段的步骤中,重新获取汇总字段。
44、本发明还提供了,llm驱动的nl2sql转换器解决复杂表格与实体对齐的系统,用于上述llm驱动的nl2sql转换器解决复杂表格与实体对齐的方法,包括:
45、表格模块,用于获取表格文档数据,其中,所述表格文档数据包括属性名称信息和属性名称信息所对应的属性值信息;
46、属性模块,用于将属性名称信息和属性名称信息所对应的属性值信息分别转换成属性名称向量数据和属性值向量数据;
47、组合模块,用于将属性名称信息和属性名称信息所对应的属性值信息组合成key-value信息,并将key-value信息转换为key-value向量数据;
48、字段模块,用于获取表格文档数据中的主体字段;
49、用户输入模块,用于获取用户输入的查询语句信息,并将查询语句信息转换成查询语句向量数据;
50、组合相似模块,用于根据查询语句向量数据,从key-value向量数据中获取与查询语句向量数据最相似的key-value信息的top-k字段;
51、属性相似模块,用于从属性名称向量数据中获取与查询语句向量数据最相似的属性名称信息的表格从左往右的top-n字段;
52、反推模块,用于从属性值向量数据中获取与查询语句向量数据最相似的属性值信息,并根据最相似的属性值信息获取反推对应属性名称信息;
53、汇总模块,用于根据top-k字段、反推对应属性名称信息、主体字段以及表格从左往右的top-n字段进行汇总,得到汇总字段;
54、语句模块,用于根据用户输入的查询语句信息、汇总字段以及key-value信息构建prompt,并生成对应的sql语句;
55、后处理模块,用于将sql语句进行后处理得到正确的sql语句。
56、以及,llm驱动的nl2sql转换器解决复杂表格与实体对齐的终端,包括:
57、一个或多个处理器;
58、存储装置,其上存储有一个或多个程序;
59、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现所述llm驱动的nl2sql转换器解决复杂表格与实体对齐的方法。
60、本发明取得的技术效果为:
61、本发明,通过向量化属性名称和属性值并存储在向量数据库中,降低了模型信息处理负担,提高了字段含义的识别和区分能力,避免了信息过载的混淆,llm识别并存储主体字段进一步优化了模型对关键字段的理解能力,将key-value对向量化并存储在向量数据库中,使得模型能够快速召回与用户输入最相似的对象,解决了实体对齐问题,确保了sql查询的准确性,通过召回最相似的属性名称和属性值,结合主体字段和用户问题,生成更准确、贴近用户意图的sql查询语句,降低了sql生成错误的风险,向量化大量字段并存储在向量数据库中减少了llm的推理成本,提高了sql生成效率,提升了用户体验和满意度,整体而言,提高了实体对齐准确性、sql生成准确性和效率,为用户提供了更流畅、高效的查询体验,提高了用户满意度。
本文地址:https://www.jishuxx.com/zhuanli/20240802/262154.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。