一种基于大数据的品牌数据智能识别诊断方法及系统
- 国知局
- 2024-08-08 16:54:28
本发明涉及大数据领域,尤其涉及一种基于大数据的品牌数据智能识别诊断方法及系统。
背景技术:
1、诊断技术在大数据领域的应用越来越广泛,可以帮助品牌管理者及时、高效地对企业品牌进行诊断和评估,实现企业品牌的及时性管理。目前,基于大数据的品牌数据智能识别诊断具有信息量庞大、数据种类多样、信息密度大等特点,品牌数据智能识别诊断方法存在较多的不确定因素,导致品牌数据智能识别诊断方法存在较大的不确定性。虽然已经发明了一些诊断系统的品牌数据智能识别诊断方法,但是仍不能有效解决品牌数据智能识别诊断方法的不确定问题。
技术实现思路
1、本发明的目的是要提供一种基于大数据的品牌数据智能识别诊断方法及系统。
2、为达到上述目的,本发明是按照以下技术方案实施的:
3、本发明包括以下步骤:
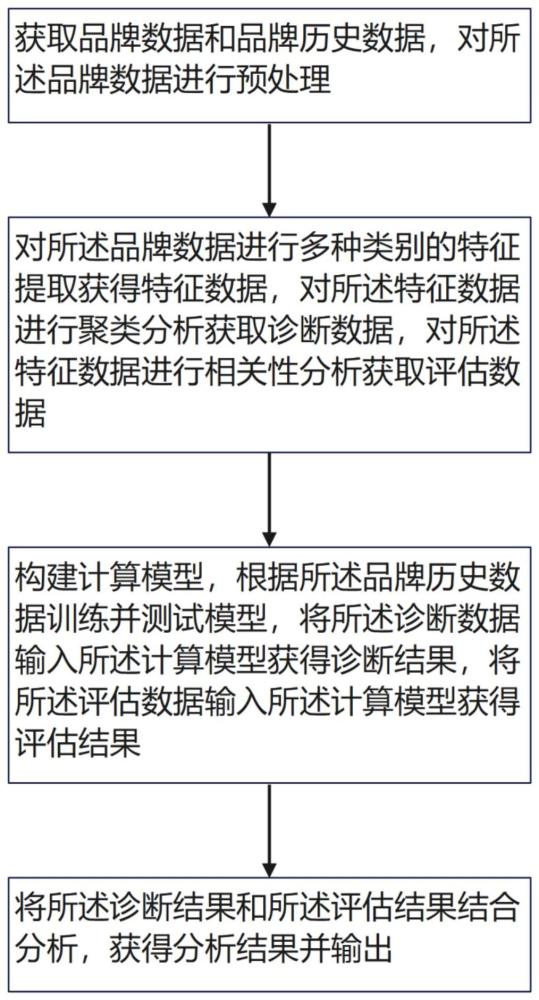
4、a获取品牌数据和品牌历史数据,对所述品牌数据进行预处理,所述品牌数据包括文本数据和数值数据;
5、b构建特征提取模型,对所述文本数据进行第一类别的特征提取,获得第一特征数据;对所述数值数据进行第二类别的特征提取,获得第二特征数据;对所述第一特征数据和所述第二特征数据进行聚类分析获取诊断数据,对所述第一特征数据和所述第二特征数据进行相关性分析获取评估数据;
6、c构建计算模型,将品牌历史数据按照n:m的比例分为训练数据和测试数据,使用训练数据训练模型,使用测试数据测试模型,将所述诊断数据输入所述品牌诊断模型获得诊断结果,将所述评估数据输入所述计算模型获得评估结果;
7、d将所述诊断结果和所述评估结果结合分析,输出分析结果。
8、进一步的,步骤a中所述预处理包括对所述文本数据进行文本清洗、去除停用词、去除标点符号、去除噪声和词形还原;对所述数值数据进行数据清洗、缺失值处理、去除异常值和去错误值。
9、进一步的,构建所述特征提取模型的方法,包括:
10、所述特征提取模型包括情感倾向特征提取模块、关键词特征提取模块、主题特征提取模块、时域特征提取模块和统计性特征提取模块;情感倾向特征提取模块基于词嵌入模型和知网情感词典,采用senta情感分析系统,提取所述文本数据的情感倾向;所述关键词特征提取模块根据tf-idf算法,提取所述文本数据的关键词;所述主题特征提取模块基于lda主题模型,采用吉布斯采样技术,提取所述文本数据的主题分布;所述时域特征提取模块根据滑动窗口算法,提取所述数值数据的时域特征;所述统计性特征提取模块根据统计分析技术,提取所述数值数据的统计性特征。
11、进一步的,对所述文本数据进行第一类别的特征提取,获得第一特征数据;对所述数值数据进行第二类别的特征提取,获得第二特征数据的方法,包括:
12、所述第一类别包括关键词特征提取、主题特征提取和情感倾向特征提取;所述第二类别包括时域特征提取和统计性特征提取;对所述文本数据进行关键词特征提取获得关键词特征,对所述文本数据进行主题特征提取获得主题特征,对所述文本数据进行情感倾向特征提取获得情感特征,所述关键词特征、所述主题特征和所述情感特征为第一特征数据;对所述数值数据进行时域特征提取获得时域特征,对所述数值数据进行统计性特征提取获得统计性特征,所述时域特征和所述统计性特征为第二特征数据。
13、进一步的,对所述第一特征数据和所述第二特征数据进行聚类分析获取诊断数据的方法,包括:
14、将所述第一特征数据和所述第二特征数据中的关键特征数据记为xi和xj,计算xi和xj之间的相似度:
15、
16、其中sij为xi和xj之间的相似度,dij为xi和xj之间的欧氏距离,k为xi和xj的维度,k=1,2,......,d,构造相似度矩阵s=(sij),将所有的相似度值升序排列,使用k-means算法将所有相似度值分类两类,将其中均值较大的一类作为类内相似度集合sin,计算截断相似度:
17、
18、其中sc为截断相似度,|sin|为类内相似度集合sin中元素的个数,计算局部密度:
19、
20、其中ρi为关键特征数据xi的局部密度,计算相对相似度:
21、
22、其中δi为关键特征数据xi的相对相似度,argmax为数学操作,表示从所有关键特征数据中选择局部密度最大的关键特征数据,ρn为第n个关键特征数据的局部密度,ρj为关键特征数据xj的局部密度,xn为所述关键特征数据中的其中一个关键特征数据,计算簇中心权值:
23、
24、其中γi为关键特征数据xi的簇中心权值,*为数学操作,表示经过归一化处理,将簇中心权值降序排列得到序列γ1>γ2,......,γk-1>γk>γk+1,......,γn,依次对每个点γk(2≤k≤n-1)的左侧和右侧进行线性回归分析,得到两个γ值预测序列:和{γk+‘1,γk+‘2,...,γn‘},计算变点γt:
25、
26、其中t为变点γt的索引,argmin为数学操作,表示提取最小的ek值,ek为γi的平方误差和,2≤k≤n-1,γi为关键特征数据xi的簇中心权值,为γi左侧的簇中心预测权值,γi‘为γi右侧的簇中心预测权值;将变点及其之前的点选出作为初始类簇中心,根据dpc算法的分配策略,将非类簇中心点分配给与其相似度最大的密度更高点所属类簇,得到初始类簇p={p1,p2,…,pcp},定义满足如下条件的关键特征数据xn为离群点:
27、
28、其中μ(·)和σ(·)分布表示数据的均值和标准差,将离群点集合记为xout,计算相似度半径:
29、
30、其中r为相似度半径,x为所述关键特征数据集合,对每一个关键特征数据,周围与其相似度大于等于r的关键特征数据被称为该关键特征数据的邻居,使用k-means算法将关键特征数据的邻居数降序排列截成两端,截断处即为临界邻居数,邻居数大于该临界邻居数的关键特征数据是核心数据,集合记为xcore;对任意两个初始类簇pi和pj,计算两个初始类簇的最大相似度,记两个初始类簇之间相似度最大的关键特征数据分别为和即:
31、
32、其中为和之间的相似度,也是两个初始类簇pi和pj的最大相似度,suv为在两个初始类簇pi和pj之间任意两个关键特征数据的相似度,xu为初始类簇pi中的其中一个关键特征数据,xv为初始类簇pj中的其中一个关键特征数据,若任意两个初始类簇pi和pj满足:
33、
34、则将这两个类簇合并,并更新聚类结果,重复上述步骤直到任意两个类簇都不满足式(1),得到最终类簇c={c1,c2,…,cnc},将类簇结果输出为诊断数据。
35、进一步的,对所述第一特征数据和所述第二特征数据进行相关性分析获取评估数据的方法,包括:
36、将所述关键特征数据中的关键特征数据记为xa和xb,根据kmedian算法将xa和xb划分为不同的数据簇,得到网格划分值为m行n列,根据得到的网格划分值计算xa和xb之间的联合概率分布和边缘概率分布,进而得到xa和xb的互信息:
37、
38、其中i(xa;xb)是xa和xb的互信息,p(xa;xb)是xa和xb的联合概率分布,p(xa)是xa的边缘概率分布,p(xb)是xb的边缘概率分布;根据互信息,计算xa和xb之间的相关性系数:
39、
40、其中mic(xa;xb)是xa和xb之间的相关性系数,m是网格化的列数,n是网格化的行数,n是所述关键特征数据的总数,i(xa;xb)是xa和xb之间的互信息,设置相关性阈值a=0.5,计算所述关键特征数据中的每两个关键特征数据之间的相关性系数,将相关性系数大于相关性阈值的关键特征数据分配到评估数据中,得到评估数据。
41、进一步的,构建计算模型,将品牌历史数据按照n:m的比例分为训练数据和测试数据,使用训练数据训练模型,使用测试数据测试模型的方法包括:
42、所述品牌历史数据包括品牌指标数据和品牌特征数据,将所述训练数据中的品牌指标数据作为因变量,品牌特征数据作为自变量,构建多元线性回归模型:
43、y=βx+ε
44、其中y为品牌指标数据,y={y1,y2,y3},x是品牌特征数据,β是回归系数,β={β0,β1,...,βn},ε是随机误差,ε={ε0,ε1,...,εn};构建残差平方和公式:
45、
46、其中为残差平方和,为预测的回归系数,τ为数学符合,表示转置,对残差平方和中的预测回归系数求导,并令其等于零,得到预测的回归系数值:
47、
48、根据计算出的预测回归系数值,得到训练后的多元线性回归模型:
49、
50、其中是预测的品牌指标数据,x是品牌特征数据,是计算出的回归系数,ε是随机误差,ε={ε0,ε1,...,εn};使用测试数据测试模型的预测效果:
51、
52、其中r2为决定系数,r2的值越接近1,预测效果越好,y是测试数据中的品牌指标数据,y={y1,y2,y3},是经过模型预测得到的预测数据,是测试数据中的品牌指标数据的均值,
53、进一步的,将所述诊断结果和所述评估结果结合分析,输出分析结果的方法,包括:
54、邀请m名专家打分,将所述诊断结果和所述评估结果中的各个数据组成集合u={u1,u2,...,un},由每位专家对集合u中的数据进行两两对比打分,则第r个专家给第ui个数据和第uj个数据打分为计算第r个专家打分与均值的偏差:
55、
56、其中为第r个专家打分与均值的偏差,为均值,i,j=1,2,...,n;r=1,2,...,m,根据偏差计算第r个专家打分的权重:
57、
58、其中λ(r)为第r个专家打分的权重,r=1,2,...,m,对打分的权重进行归一化处理:
59、
60、其中λ*(r)是进行归一化处理后的第r个专家打分的权重,r=1,2,...,m,根据修正后的权重计算集合u中每两个数据之间的得分,得到比较判断矩阵:
61、a=[aij]n×n
62、其中a为比较判断矩阵,aij为集合u中每两个数据之间的得分,根据比较判断矩阵,计算比较判断矩阵的最大特征根λmax:
63、
64、其中mi为比较判断矩阵每一行元素的乘积,mj为比较判断矩阵每一列元素的乘积,n为行数和列数,根据最大特征根λmax求其对应的特征向量:
65、aw′=λmaxw′
66、其中w′为最大特征根λmax对应的特征向量,将所述特征向量经过对数处理得到权重向量w,其中w=logw′;所述权重向量即所述诊断结果和所述评估结果中各数据对品牌分数的重要程度权重分配,计算品牌分数:
67、
68、其中c为品牌分数,ui为集合u={u1,u2,...,un}中的第i个数据,wi为权重向量w中ui对应的权重分配,n为集合u中数据总数。根据所述诊断结果绘制雷达图,根据所述评估结果绘制折线图,将所述品牌分数、雷达图和折线图作为分析结果输出。
69、本发明的有益效果是:
70、本发明是一种基于大数据的品牌数据智能识别诊断方法及系统,与现有技术相比,本发明具有以下技术效果:
71、本发明通过预处理、提取特征、聚类分析、相关性分析和构建计算模型步骤,可以提高品牌数据诊断的准确性,从而提高品牌数据诊断的精度,将品牌数据诊断智能化,可以大大节省资源和人力成本,提高工作效率,可以实现对品牌数据的自动识别和诊断,实时对品牌数据进行特征提取和计算,对品牌数据诊断具有重要意义,可以适应不同产品的品牌数据智能诊断系统,具有一定的普适性。
本文地址:https://www.jishuxx.com/zhuanli/20240808/271121.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。