基于特征差异平衡的快速对抗训练方法
- 国知局
- 2024-08-08 16:57:15
本发明涉及一种基于特征差异平衡的快速对抗训练技术,属于计算机视觉与图像处理。
背景技术:
1、深度学习凭借深度神经网已经在计算机视觉领域、自然语言处理领域等都取得了显著的进展。然而,深度学习在复杂的自然环境或人为的对抗环境中表现出鲁棒性严重不足的问题。研究发现,在正常数据集上表现良好的深度学习模型,会被一些特定的情况欺骗,导致模型精度严重下降。这类能够完成欺骗模型的样本一般被称为对抗样本(adversarial examples)。
2、有相关研究表明,以图像分类任务为例,恶意攻击者可以向图片中添加微小、肉眼几乎不可见的扰动,使原本表现较好的深度学习模型以较高的概率将对抗样本错分为其他类别,导致模型宜高置信度错误预测。因为模型鲁棒安全性问题的存在,加之目前深度学习的不可解释性,虽然深度学习在各个领域不断发展和创新,但在一些较为敏感的领域,如军事、医学、金融等,深度学习的可靠性有限,进而造成应用受限,阻碍了人工智能进一步的发展。
3、对抗训练是抵御对抗攻击危害的有效方式。对抗训练是利用对抗样本进行模型的训练,其中wong等人提出的以快速梯度符号算法(fast gradient sign method,fgsm)为核心的单步快速对抗训练[wong e,rice l,kolter j z.fast is better than free:revisiting adversarial training[c].international conference on learningrepresentations,2019.],可以在显著节约时间资源的前提下提升模型的鲁棒性。然而,目前大部分主流的对抗训练算法都是对全部数据采取统一的训练策略,忽略了样本之间的特征属性,没有综合考虑其联系与差异。
4、综上所述,研究深度学习模型的鲁棒性对深度学习的发展和在各个领域的应用可靠性具有十分重要的现实意义。一方面,当前研究缺乏探究对抗训练中不同样本之间在特征层面的差异与联系。另一方面,如何利用相关现象,在不额外增加训练成本的前提下,更有针对性的提升深度学习模型的鲁棒性也是研究的重要挑战。因此,本发明基于特征差异平衡的快速对抗训练算法,进一步提升深度学习模型的鲁棒性。
技术实现思路
1、为解决上述问题,本发明公开了基于特征差异平衡的快速对抗训练方法,通过探究样本在特征层面的差异与联系,从而提升训练的稳定性和模型的鲁棒性。所设计的算法包含两种具体实施方案,即基于样本类别引导和基于样本特征引导,该方法可以根据数据集样本的特征信息,动态的调整训练策略;所设计的基于样本类别引导的方案需要尽可能做到训练过程中样本在类别范围内的平衡。基于样本特征引导的方案则是从特征这一维度出发,通过将具有相同特征的样本进行统一处理,在训练过程中动态的调整训练的策略,降低不同特征的样本在训练过程中相互作用带来的负面影响。本发明提出的方法不会增加模型自身的参数,也不会为模型训练的所需要的计算资源和计算时间增加额外负担。
2、为了实现上述目的,本发明采用以下技术方案:
3、第一方面,基于特征差异的快速对抗训练方法,样本类别引导方案如下:
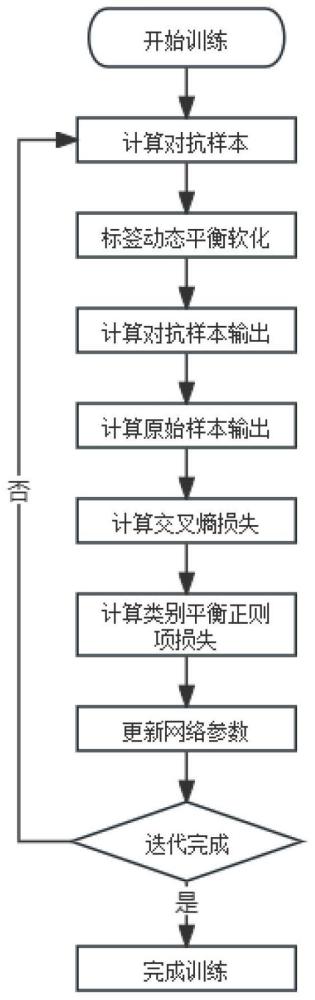
4、步骤s1:由于本发明可以当作插件与现有的主流快速对抗训练方法相结合,因此,需要根据插件目标对象的方法初始化扰动信息δ0。一般的,对扰动信息δ0的初始化操作都需要首先从[-∈,∈]中均匀采样,为了满足扰动信息肉眼不可见的特性,需要扰动信息满足‖δ‖∞<∈,其中∈代表数值边界,在对抗训练中一般设为
5、步骤s2:对抗训练的目标是利用生成高质量的对抗样本来对模型进行训练,从而提升模型的鲁棒性。在生成对抗样本的过程中,首先将初始化生成的扰动信息δ0添加到干净样本x中得到初始化对抗样本xinit=x+δ0。
6、步骤s3:将初始化对抗样本xinit作为目标模型的输入,根据fgsm算法的定义,更新扰动信息并将扰动信息重新添加到干净样本中得到本轮训练的对抗样本xadv,计算公式如下:
7、
8、其中,fθ为模型,θ为模型的参数,y为样本的标签,l(·,·)为损失函数,一般使用交叉熵函数。
9、步骤s4:在得到更新过后的对抗样本xadv后,将对抗样本作为模型的输入进行对抗训练。此外,需要结合本发明提出的动态标签平衡平滑,以进一步减弱在训练过程中因样本的不平衡所带来的负面影响,其公式定义为:
10、
11、其中定义为:
12、
13、第i类样本在第k轮训练过程中的干净精度,y代表one-hot形式的标签,为了限制标签平滑后的合理性,需要对其进行约束,因此kmin的范围定义为标签均衡平滑基于训练状态和类特征动态调整标签,有效缓解内外优化失衡问题。需要指出,该方法在没有增加额外超参数的前提下将样本标签进行平衡平滑,不会为训练增加额外负担,最终得到分类损失lce。
14、步骤s5:在更新模型参数阶段使用的损失函数为交叉熵损失函数结合正则项函数。交叉熵函数是为了满足分类任务的基本要求,而正则项的意义则是尽可能做到样本在类别范围内的平衡。因此,分别对于每一类样本,以类别为界限,该方法在损失函数中添加正则项损失以平衡模型对原始样本和对抗样本的输出值,损失函数定义如下:
15、loa=lce+lcwr,
16、loa代表整体损失,lce代表标准交叉熵损失函数,lcwr代表本方法提出的特征差异平衡正则项损失(样本类别引导方案),定义为:
17、
18、xi代表属于第i类的样本,λ为超参数,用于控制正则项的权重,平衡模型对对抗性样本与原始图像输出之间的权重,m代表数据集共有多少分类类别,θ代表模型的参数,fθ代表模型整体接收输入的运算过程。
19、第二方面,基于特征差异的快速对抗训练方法,样本特征引导方案如下:
20、步骤s1:由于本发明可以当作插件与现有的主流快速对抗训练方法相结合,因此,需要根据插件目标对象的方法初始化扰动信息δ0。一般的,对扰动信息δ0的初始化操作都需要首先从[-∈,∈]中均匀采样,为了满足扰动信息肉眼不可见的特性,需要扰动信息满足‖δ‖∞<∈,其中∈代表数值边界,在对抗训练中一般设为
21、步骤s2:对抗训练的目标是利用生成高质量的对抗样本来对模型进行训练,从而提升模型的鲁棒性。在生成对抗样本的过程中,首先将初始化生成的扰动信息δ0添加到干净样本x中得到初始化对抗样本xinit=x+δ0。
22、步骤s3:将初始化对抗样本xinit作为目标模型的输入,根据fgsm算法的定义,更新扰动信息并将扰动信息重新添加到干净样本中得到本轮训练的对抗样本xadv,计算公式如下:
23、
24、其中,fθ为模型,θ为模型的参数,y为样本的标签,l(·,·)为损失函数,一般使用交叉熵函数。
25、步骤s4:在得到更新过后的对抗样本xadv后,将对抗样本作为模型的输入进行对抗训练。此外,需要结合本发明提出的动态标签平衡平滑,以进一步减弱在训练过程中因样本的不平衡所带来的负面影响,其公式定义为:
26、
27、其中定义为:
28、
29、第i类样本在第k轮训练过程中的干净精度,y代表one-hot形式的标签,为了限制标签平滑后的合理性,需要对其进行约束,因此kmin的范围定义为标签均衡平滑基于训练状态和类特征动态调整标签,有效缓解内外优化失衡问题。需要指出,该方法在没有增加额外超参数的前提下将样本标签进行平衡平滑,不会为训练增加额外负担。基于特征差异的快速对抗训练方法,样本特征引导方案需要用到前一轮的训练信息,使用交叉熵函数作为损失函数计算相关指标并记录,记录要求包括每个类别样本的干净精度ci、每个类别样本的鲁棒精度ri、数据集平均干净精度c以及数据集平均鲁棒精度r。
30、步骤s5:从每二轮训练该步骤生效,需要利用上一轮训练的指标,使用如下公式计算特征相关系数
31、
32、根据相关系数,可以将数据集中的所有样本在特征层面分为四大类,分别为良好干净和鲁棒(good clean good robust,gcgr)特征类,其相关系数应满足指标即无论是干净精度还是鲁棒精度均超过数据集平均水平;定义良好干净和较差鲁棒(good clean bad robust,gcbr)特征类,其相关系数应满足指标具有该特征的样本,较好的干净精度较好却没有呈现较好的鲁棒精度;定义较差干净和良好鲁棒(bad clean good robust,bcgr)特征类,其相关系数应满足指标具有该特征的样本与gcbr特征类表现相反,其鲁棒精度表现较好,但干净精度表现差强人意;以及定义较差干净和鲁棒(bad clean bad robust,bcbr)特征类,其相关系数应满足指标具有该特征的样本,干净精度和鲁棒精度都远低于平均水平。
33、步骤s6:根据特征相关系数将原本数据集的所有样本聚类为四种特征类,对每一种特征类,在损失函数中设置对应的正则项损失,基于特征差异的快速对抗训练方法,样本特征引导方案的损失函数定义如下:
34、loa=lce+lfwr,
35、loa代表整体损失,lce代表标准交叉熵损失函数,lfwr代表本方法提出的特征差异平衡正则项损失(样本特征引导方案),定义为:
36、
37、其中,j代表基于样本特征引导的四大特征类,本方案会将数据集中所有的样本分为4大特征类;xi代表属于第i类特征样本,λ为超参数,用于控制正则项的权重,θ代表模型的参数,fθ代表模型整体接收输入的运算过程。这种正则化方法可以无缝扩展到任何现有的快速对抗训练方法,随着类别数量的增加,在不引入额外训练时间消耗的情况下提高性能,提高训练稳定性,增加模型的鲁棒性。
38、本发明提供的基于特征差异平衡的快速对抗训练算法及其两种方案能够提升训练的稳定性,增强人工智能模型面对对抗攻击的鲁棒性。本发明可以用于图像处理、信息安全、自动驾驶、智能机器人。目前,大多数主流的对抗训练方法都是对数据集中所有的样本采用统一策略,忽略了样本存在的固有特征差异,本发明发现,不同类别的样本在特征方面存在明显差异,但类别也会出现一致趋势,表明存在潜在的更深层次的模式从样本数据的特征。本发明基于特征的视角,从宏观和动态的角度分析训练过程中示例特征的变化,可以有效提高深度学习的鲁棒性,缓解由于深度学习中算法脆弱性给人工智能带来的内生安全问题。
本文地址:https://www.jishuxx.com/zhuanli/20240808/271414.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表