基于自适应样本生成的水稻复杂稻作模式识别方法及系统
- 国知局
- 2024-08-22 14:27:29
本发明属于农业遥感,具体涉及一种基于自适应样本生成的水稻复杂稻作模式识别方法及系统。
背景技术:
1、水稻是世界上最重要的粮食作物之一,在全球粮食生产和粮食安全中起着重要的作用。部分地区水稻多熟种植制度及丰富的水稻稻作模式较好地促进了粮食增产。常见的水稻稻作模式有油-稻(麦-稻)轮作、双季稻连作、单季稻单作以及新型稻虾共作模式等。
2、近年来,部分地区水稻种植结构和生产力布局发生了很大的改变,而已有数据和研究仅能大概了解各类稻作模式的增减趋势,无法全面地剖析对水稻种植的时空格局变化特征。由于稻作样本需多时期高分辨率影像确认,在历史遥感源受限的情况下,目视解译难以获取足够的样本。由于缺乏高质量的历史稻作样本,导致历史长时序稻作模式制图受限,进而无法全面了解稻作模式历史演变特征和驱动机制。
3、因此,需要一种新的水稻稻作模式识别方法,实现长时序稻作模式空间分布信息精细化提取。
技术实现思路
1、鉴于此,本发明提出了一种基于自适应样本生成的水稻复杂稻作模式识别方法及系统,用于解决现有的水稻稻作模式分类不够精细的问题。
2、本发明第一方面,公开了一种基于自适应样本生成的水稻复杂稻作模式识别方法,所述方法包括:
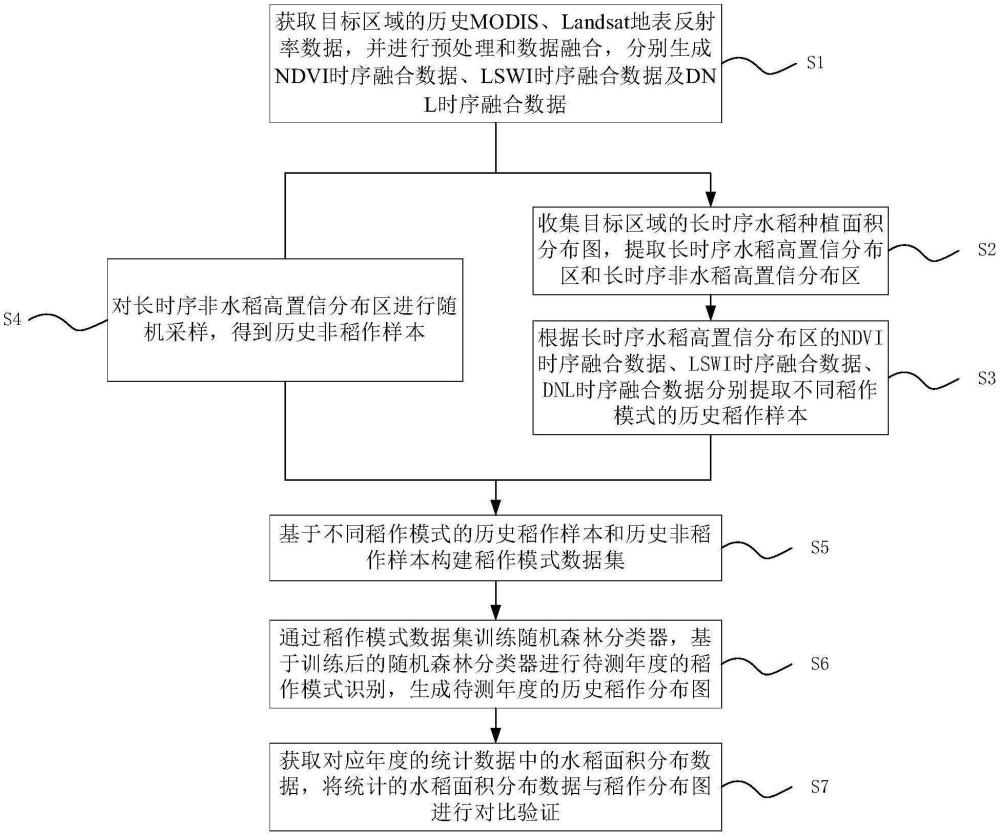
3、获取目标区域的历史modis、landsat地表反射率数据,并进行预处理和数据融合,分别生成ndvi时序融合数据、lswi时序融合数据及dnl时序融合数据;
4、收集目标区域的长时序水稻种植面积分布图,提取长时序水稻高置信分布区和长时序非水稻高置信分布区;
5、根据长时序水稻高置信分布区的ndvi时序融合数据、lswi时序融合数据、dnl时序融合数据分别提取不同稻作模式的历史稻作样本;
6、对长时序非水稻高置信分布区的进行随机采样,得到历史非稻作样本;
7、基于不同稻作模式的历史稻作样本和历史非稻作样本构建稻作模式数据集;
8、通过稻作模式数据集训练随机森林分类器,基于训练后的随机森林分类器进行待测年度的稻作模式识别,生成待测年度的历史稻作分布图。
9、在以上技术方案的基础上,优选的,所述进行预处理和数据融合的具体过程为:
10、对目标区域的modis、landsat地表反射率数据进行去云处理,分别生成modis数据的ndvi、lswi原始时序数据和landsat数据的ndvi、lswi原始时序数据;
11、分别对modis数据的ndvi、lswi原始时序数据进行缺失值填充、滤波和重采样处理,得到modis数据预处理后的ndvi时序数据、lswi时序数据;
12、采用modis数据预处理后的ndvi时序数据曲线来填补landsat数据的ndvi原始时序数据的缺失值;对landsat数据填补后的ndvi时序数据进行校正处理和滤波,得到ndvi时序融合数据;
13、采用modis数据预处理后的lswi时序数据曲线来填补landsat数据的lswi原始时序数据的缺失值;对landsat数据填补后的lswi时序数据进行校正处理和滤波,得到lswi时序融合数据;
14、计算ndvi时序融合数据与lswi时序融合数据的差值,得到dnl时序融合数据。
15、在以上技术方案的基础上,优选的,根据长时序水稻高置信分布区的ndvi时序融合数据、lswi时序融合数据、dnl时序融合数据分别提取不同稻作模式的历史稻作样本具体包括:
16、将长时序水稻高置信分布区划分为一熟水稻高置信分布区和二熟水稻高置信分布区,并分别提取一熟水稻高置信分布区、二熟水稻高置信分布区的物候参数;
17、获取目标区域不同稻作模式的实地稻作样本,分别对不同稻作模式的实地稻作样本进行时序重要性分析和光谱特征重要性分析,确定不同稻作模式的关键物候期和对应的关键光谱指数;
18、基于不同稻作模式的关键物候期和对应的关键光谱指数,以及一熟水稻高置信分布区、二熟水稻高置信分布区的物候参数,在一熟水稻高置信分布区提取水稻单作和水稻共作的历史稻作样本,在二熟水稻高置信分布区提取水稻轮作和水稻连作的历史稻作样本。
19、在以上技术方案的基础上,优选的,所述将长时序水稻高置信分布区划分为一熟水稻高置信分布区和二熟水稻高置信分布区,并分别提取一熟水稻高置信分布区、二熟水稻高置信分布区的物候参数具体包括:
20、对ndvi时序融合数据的曲线进行峰值检测,通过有效峰值数量确定耕地种植强度,根据耕地种植强度将长时序水稻高置信分布区分为一熟水稻高置信分布区和二熟水稻高置信分布区;
21、根据ndvi时序融合数据分别提取一熟水稻高置信分布区和二熟水稻高置信分布区的物候参数,所述物候参数包括生长起点、生长峰值点及生长止点。
22、在以上技术方案的基础上,优选的,所述获取目标区域不同稻作模式的实地稻作样本,分别对不同稻作模式的实地稻作样本进行时序重要性分析和光谱特征重要性分析,确定不同稻作模式的关键物候期和对应的关键光谱指数具体包括:
23、获取目标区域当前时间下的实地水稻单作样本、实地水稻共作样本、实地水稻轮作样本和实地水稻连作样本作为实地稻作样本;
24、分别对一熟耕地种植区的实地稻作样本进行水稻单作、水稻共作的时序重要性分析及光谱重要性分析,分别得到水稻单作的关键物候期、水稻共作的关键物候期及对应的关键光谱指数;
25、分别对二熟耕地种植区的实地稻作样本进行水稻轮作、水稻连作的时序重要性分析及光谱重要性分析,分别得到水稻轮作的关键物候期、水稻连作的关键物候期及对应的关键光谱指数。
26、在以上技术方案的基础上,优选的,水稻单作的关键物候期为sos-eos,对应的关键光谱指数为ndvi数据、lswi数据;
27、水稻共作的关键物候期为0-sos,对应的关键光谱指数为ndl数据;
28、水稻轮作的关键物候期为peak1-peak2,对应的关键光谱指数为ndvi数据、lswi数据;
29、水稻连作的关键物候期为sos1-eos2,对应的关键光谱指数为ndvi数据;
30、其中,sos、eos分别为一熟耕地种植区的生长起点、生长止点;sos1、eos2分别为二熟耕地种植区的第一个生长起点、第二个生长止点;peak1、peak2分别为二熟耕地种植区的第一个生长峰值点、第二个生长峰值点。
31、在以上技术方案的基础上,优选的,所述在一熟水稻高置信分布区提取水稻单作和水稻共作的历史稻作样本具体包括:
32、在一熟水稻高置信分布区,根据水稻单作的关键物候期设置第一物候窗口pw1,在第一物候窗口pw1内,采用pwdtw算法分别计算实地水稻单作样本的ndvi数据与一熟水稻高置信分布区的ndvi时序融合数据的第一时序相似度、实地水稻单作样本的lswi数据与一熟水稻高置信分布区的lswi时序融合数据的第二时序相似度;
33、筛选第一时序相似度和第二时序相似度均小于第一预设阈值的数据作为候选样本;
34、在候选样本中,根据水稻共作的关键物候期设置第二物候窗口pw2,在第二物候窗口pw2内,采用pwdtw算法计算实地水稻共作样本的ndl数据与候选样本的ndl时序融合数据的第三时序相似度,筛选第三时序相似度小于第二预设阈值的数据作为历史水稻共作样本,其余的均作为历史水稻单作样本。
35、在以上技术方案的基础上,优选的,所述在二熟水稻高置信分布区提取水稻轮作和水稻连作的历史稻作样本具体包括:
36、在二熟水稻高置信分布区,根据水稻轮作的关键物候期设置第三物候窗口pw3,在第三物候窗口pw3内,采用pwdtw算法计算实地水稻轮作样本的ndvi数据与二熟水稻高置信分布区ndvi时序融合数据的第四时序相似度、实地水稻轮作样本的lswi数据与二熟水稻高置信分布区lswi时序融合数据的第五时序相似度;
37、筛选第四时序相似度和第五时序相似度均小于第三预设阈值的数据作为历史水稻轮作样本,其余的作为剩余二熟稻作样本;
38、在剩余二熟稻作样本中,根据水稻连作的关键物候期设置第四物候窗口pw4,在第四物候窗口pw4内,采用pwdtw算法计算实地水稻连作样本的ndvi数据与剩余二熟稻作样本的ndvi时序融合数据的第六时序相似度;
39、筛选第六时序相似度均小于第四预设阈值的数据作为历史水稻连作样本。
40、本发明第二方面,公开了一种基于自适应样本生成的水稻复杂稻作模式识别系统,所述系统包括:
41、数据获取模块:用于获取目标区域的历史modis、landsat地表反射率数据,并进行预处理和数据融合,分别生成ndvi时序融合数据、lswi时序融合数据及dnl时序融合数据;
42、区域划分模块:用于收集目标区域的长时序水稻种植面积分布图,提取长时序水稻高置信分布区和长时序非水稻高置信分布区;
43、样本生成模块:用于根据长时序水稻高置信分布区的ndvi时序融合数据、lswi时序融合数据、dnl时序融合数据分别提取不同稻作模式的历史稻作样本;对长时序非水稻高置信分布区进行随机采样,得到历史非稻作样本;基于不同稻作模式的历史稻作样本和历史非稻作样本构建稻作模式数据集;
44、稻作识别模块:用于通过稻作模式数据集训练随机森林分类器,基于训练后的随机森林分类器进行待测年度的稻作模式识别,生成待测年度的历史稻作分布图。
45、本发明第三方面,公开一种电子设备,包括:至少一个处理器、至少一个存储器、通信接口和总线;
46、其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;
47、所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令,以实现如本发明第一方面所述的方法。
48、本发明相对于现有技术具有以下有益效果:
49、1)本发明充分挖掘长时序多源光学数据(modis、landsat)时间和空间信息,基于两者的数据融合生成时序融合植被指数数据,在历史高置信水稻分布区,自适应生成不同稻作模式的历史稻作样本,结合历史非稻作样本形成稻作数据集,利用机器学习进行不同稻作模式识别,可以实现不同水稻稻作模式的精细分类,填补了现有研究中长时序水稻种植模式精细化分布的空白,为水稻种植结构的优化提供了详实数据支撑。
50、2)本发明将长时序水稻高置信分布区划分为一熟水稻高置信分布区和二熟水稻高置信分布区,并分别提取一熟水稻高置信分布区、二熟水稻高置信分布区的物候参数,在一熟水稻高置信分布区提取水稻单作和水稻共作的历史稻作样本,二熟水稻高置信分布区提取水稻连作和水稻轮作的历史稻作样本,实现了基于历史时序数据的水稻单作、共作、连作和轮作四类历史稻作样本的自动生成,丰富了稻作样本的精细程度,有效扩充了样本数量,解决了当前缺乏高质量的历史稻作样本、导致历史长时序稻作模式制图受限的难题。
51、3)本发明获取目标区域不同稻作模式的实地稻作样本,基于不同稻作模式的实地稻作样本的关键物候期和对应的光谱指数,将对应的历史ndvi时序融合数据、lswi时序融合数据及dnl时序融合数据分别与实地稻作样本的时序数据进行比对,从历史数据中提取与对应稻作模式实地稻作样本的时序形状特征相似的数据作为历史稻作样本,可以保障对应稻作模式的样本质量,提升历史稻作样本自适应生成的准确度。
52、4)本发明基于不同稻作模式的实地稻作样本的关键物候期分别为不同稻作模式设定了对应物候窗口,在对应的物候窗口内进行历史时序数据与实地时序数据的相似度计算,可以防止时序数据曲线的扭曲变形或漂移,使时序形状特征相似度的计算更准确,提升自适应生成的稻作样本集的质量。
53、5)本发明基于自适应生成的稻作样本集,利用机器学习进行历史长时序稻作模式提取,获取长时序稻作空间分布信息,为水稻种植结构、土地等相关资源配置及农业政策调整和优化调整和优化提供了详实数据支撑。
本文地址:https://www.jishuxx.com/zhuanli/20240822/278758.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表