基于改进Transformer网络的场景文本识别方法
- 国知局
- 2024-09-05 14:29:12
本发明涉及场景文本识别的,尤其是指一种基于改进transformer网络的场景文本识别方法。
背景技术:
1、场景文本识别旨在同时检测和识别自然场景中的文本,由于其在自动驾驶、智能交通、文档分析和信息提取等场景的应用而备受关注。然而,由于以下原因,使得这项工作仍具有挑战性:1)自然场景下的文本实例在颜色、形状、方向、语言和布局方面表现出多种多样的形式;2)复杂的背景信息。一些文本可能会因为与背景具有相似的纹理信息而与背景融合,并且还可能会被不相关的物体遮挡,导致文本识别困难,甚至无法识别;3)较多的外部干扰因素。例如光照、拍摄角度和文本实例的位置等,都会增加场景文本识别的难度。
2、传统的场景文本识别方法分为两个不同的子任务:文本检测和文本识别。首先检测出文本实例的位置,然后将文本实例区域从原图像中裁剪出来,最后识别出裁剪区域的文本内容。虽然这些方法思路简单,实现容易,但存在以下局限性:1)误差积累。不准确的检测结果会严重降低文本识别的准确性;2)推理速度慢。两个子任务需要按照先检测后识别的顺序执行,会严重影响推理速度;3)两个子任务单独优化可能无法最大程度地提升文本识别的性能。
技术实现思路
1、本发明的目的在于克服现有技术的缺点与不足,提出了一种基于改进transformer网络的场景文本识别方法,能够从跨模态角度将视觉信息和语义信息的进行融合,加强了模态间的信息交互,提高了场景文本识别准确率,同时可进行端到端的场景文本识别。
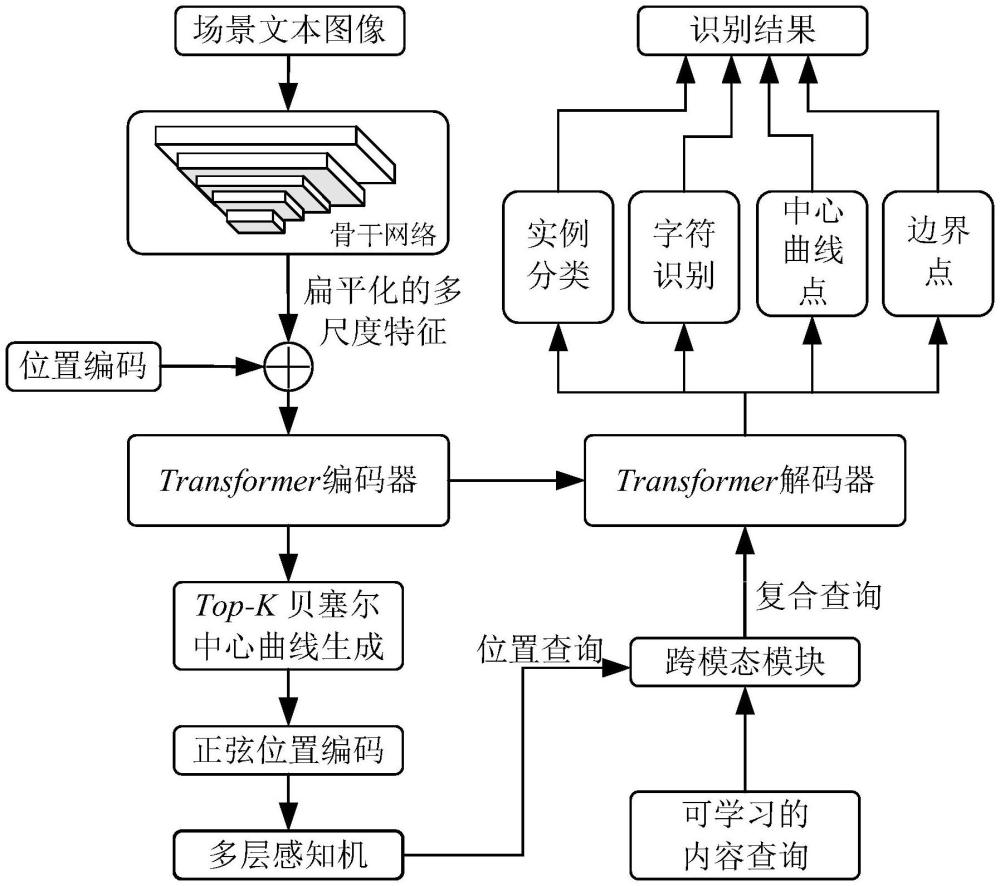
2、为实现上述目的,本发明所提供的技术方案为:基于改进transformer网络的场景文本识别方法,该改进transformer网络是对原来transformer网络的transformer编码器、transformer解码器、编码器与解码器之间的连接和预测模块都进行改进,其中,对编码器的改进是:使用多尺度可变形注意力替换原有的多头注意力,以提取更多的特征信息;对解码器的改进是:使用循环分解自注意力模块替换掩码多头注意力中原有的多头注意力,使得网络对文本轮廓特征具有更强的提取能力,从而增强网络的文本检测性能;对编码器与解码器之间的连接的改进是:加入top-k贝塞尔中心曲线生成、正弦位置编码、多层感知机和跨模态模块,以增强文本检测和识别的交互和协同,从而提高场景文本识别准确率;对预测模块的改进是:设计四个并行的预测头分别进行实例分类、字符识别、中心曲线点预测和边界点预测,以实现更高的文本识别准确率;
3、所述场景文本识别方法的具体实施包括以下步骤:
4、1)获取公开的场景文本数据集,将对应标签转换为coco数据集格式,并且将多个公开的场景文本数据集中的训练集整合成混合训练集,测试集不变;
5、2)把训练集中的数据送入改进transformer网络进行训练,通过改进transformer网络的骨干网络提取场景文本图像的特征信息,得到扁平化的多尺度特征;将扁平化的多尺度特征与位置编码相加,并输入到使用多尺度可变形注意力的transformer编码器,生成贝塞尔中心曲线及其分数;选取分数最高的前k条贝塞尔中心曲线,并在选取出的每条曲线上均匀采样n个点;依次使用正弦位置编码和多层感知机将采样点的坐标编码成位置查询,并将其与可学习的内容查询同时输入到设计的跨模态模块,得到复合查询;将transformer编码器的输出和复合查询同时输入到使用循环分解自注意力模块的transformer解码器,得到每张图像的解码信息;最后利用四个预测头对解码信息进行并行预测,得到最终的识别结果;其中,在反向传播中先使用匈牙利算法进行配对匹配,使得预测值和真实值一一对应,然后使用实例分类损失、字符识别损失、中心曲线点坐标预测损失和边界点预测损失的加权和作为总损失,经过多次迭代至损失值最小,最终得到最优网络;
6、3)将测试集中的数据输入到训练得到的最优网络中得到预测信息,接着将预测的检测框绘制在原始图片上,在检测框的左上角区域标出检测框内的字符识别信息,从而完成场景文本的识别。
7、进一步,所述步骤1)包括以下步骤:
8、1.1)获取公开的场景文本数据集;
9、1.2)将数据集中的标签格式全部转换为coco数据集格式;
10、1.3)将多个公开的场景文本数据集中的训练集整合成混合训练集,测试集不用整合。
11、进一步,在步骤2),所述骨干网络为resnet、swin transformer和vitae中的一种。
12、进一步,在步骤2),所述多尺度可变形注意力的具体情况如下:
13、给定一组l层的多尺度特征图每一层特征图为其中cl、hl和wl分别表示第l层特征图的通道数、高度和宽度,表示实数;并且为每个查询q的参考点的归一化坐标,则多尺度可变形注意力的表示如下:
14、
15、式中,h表示注意力头的总数;h、l和m分别表示注意力头、输入特征图层数和采样点的键值;m表示采样点的总数;ahlqm表示查询q的注意力权重;φl表示将归一化坐标映射到第l层特征图的比例;δphlqm表示为查询q生成适当的采样偏移量;wh和w′h分别为可训练权重矩阵。
16、进一步,在步骤2),所述跨模态模块的具体情况如下:
17、得到位置查询和内容查询其中,k和n分别表示选取出的贝塞尔中心曲线的个数和每条曲线上采样点的个数,表示实数;
18、首先,将位置查询p输入到多层感知机,然后与内容查询c相加,得到语义特征
19、s′=p+w2*softmax(w1c)
20、式中,和是可训练的权重,其中o表示字符类别的数量;
21、然后,将语义特征s′和位置查询p输入到多头缩放点积注意力中,得每个注意力权重其中n表示注意力头数,表示如下:
22、
23、式中,pe表示detr中的可学习的输出位置编码;d表示位置查询p的特征维度数;m′表示屏蔽注意力,能防止查询过度关注自身,表示如下:
24、
25、式中,r和s均表示中的第r个和第s个位置;
26、最后,将n个注意力权重进行拼接,并与语义特征s′相加,之后再依次输入到归一化层和全连接层,得到复合查询
27、q=fc(bn(concat(a1,a2,…,an)))
28、式中,concat表示拼接操作;bn表示批归一化层;fc表示全连接层。
29、进一步,在步骤2),所述循环分解自注意力模块的具体情况如下:
30、首先,将复合查询q输入到组内自注意力saintra分支,得到组内查询qintra:
31、qintra=saintra(q)
32、然后,将复合查询q输入到循环卷积circonv分支,得到循环卷积查询qcir:
33、qcir=relu(bn(circonv(q)))
34、式中,bn表示批归一化层;
35、最后,将组内查询qintra和循环卷积查询qcir相加,并依次输入到层归一化层ln和组间自注意力sainter,则循环分解自注意力模块cfsa的表示如下:
36、cfsa=sainter(ln(qintra+qcir))。
37、进一步,在步骤2),所述四个预测头的具体情况如下:
38、实例分类:使用全连接层进行文本或背景分类,在推理过程中,将n′个分数的平均值作为每个实例的置信度分数;
39、字符识别:由于是在每个文本的中心曲线上均匀采样得到的点,因此每个点查询代表一个特定的字符类别包括背景,采用线性层进行字符识别;
40、中心曲线点预测:使用3层的多层感知机预测参考点到中心曲线上真实点的坐标偏移;
41、边界点预测:使用3层的多层感知机预测上、下曲线与真实点的偏移。
42、进一步,在步骤2),所述反向传播的具体情况如下:
43、首先,使用匈牙利算法进行配对匹配,并最小化预测值与真实值匹配成本cmatch,表示如下:
44、cmatch=λclsccls+λcoordccoord
45、式中,λcls和λccoord分别表示实例分类和中心曲线点坐标的成本权重;ccls和ccoord分别表示实例分类和中心曲线点坐标的成本;
46、经过匈牙利算法匹配后,预测值和真实值能够一一对应;总训练损失ltotal计算如下:
47、ldec=αclslcls+αreclrec+αcoordlcoord+αbblbb
48、lenc=αclslcls+αcoordlcoord
49、ltotal=lenc+ldec
50、式中,ldec和lenc分别表示解码器损失和编码器损失;αcls、αrec、αcoord和αbb分别表示实例分类、字符识别、中心曲线点坐标和边界框的损失权重;实例分类lcls是focal损失;字符识别lrec是交叉熵损失;中心曲线点坐标损失lcoord是l1损失;边界框损失lbb由l1损失和giou损失组成。
51、本发明与现有技术相比,具有如下优点与有益效果:
52、1、本发明可实现端到端的自然场景文本识别,减少误差积累。
53、2、本发明的跨模态模块通过缩放注意力点积操作,将位置查询和内容查询从视觉和语义的跨模态角度进行融合,使得内容查询融合了位置查询中的文本位置和形状信息,位置查询融合了内容查询中的文本语义信息,从而增强文本检测和识别的交互和协同,提高自然场景文本识别准确率;
54、3、本发明的循环分解自注意力模块使得网络对文本轮廓特征具有更强的提取能力,从而增强网络的文本检测性能。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286701.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。