一种语音驱动的全身动作生成方法
- 国知局
- 2024-09-05 14:51:46
本发明属于三维人体动作生成,具体涉及一种语音驱动的全身动作生成方法。
背景技术:
1、当前,随着元宇宙产业的高速发展,其技术体系逐渐成熟,应用场景也日益丰富。其中,以数字人为中心的应用尤为热门,被广泛运用于老年助手、视频教学、儿童情绪调节、电子商务、机器人以及虚拟治疗等领域。在元宇宙中,用户与互联网的交互方式已从简单的二维界面演变为更加身临其境的三维体验,沉浸式交流成为其重要特征。然而,实现沉浸式交流方式之一的语音驱动全身动作生成技术,仍然面临着挑战和局限性。
2、其一,目前的研究主要集中在语音生成全身的部分运动,而非涵盖脸部、上半身、下半身在一起的整体运动,fan等人(fan y,lin z,saito j,et al.faceformer:speech-driven 3dfacial animatio n with transformers[c].proceedings of the ieee/cvfconference o n computer vision and pattern recognition(cvpr),2022)利用四维人脸扫描数据集,训练改进的transformer结构,以输出每帧对应的人脸顶点位置信息,从而实现语音对应的脸部动作生成。habibie等人(habibie i,elgharib m,sarkar k,et al.amotion matchin g-based framework for controllable gesture synthesis fromspeech[c].acmsiggraph 2022conference proceedings(siggraph),2022)考虑了音频和手势的相似性,基于音频输入,利用k-最近邻算法从数据库中搜索出最可信的上半身运动序列。li等人(li j,kang d,pei w,et al.audio2gestures:generating diversegestures from s peech audio with conditional variational autoencoders[c].proceeding s of the ieee/cvf international conference on computer vision(iccv),2021)将运动表示分解为音频运动共享和运动特定特征来反映音频和身体运动之间的映射关系,从而更好地回归训练数据并生成不同的身体动作。然而,在日常交谈中,人们会产生各种脸部表情变化和手部动作,甚至在情绪激烈时可能会有较大幅度的身体动作,如踱步、弯腰或下蹲等。因此,语音驱动的动作生成需要综合考虑到脸部、上半身和下半身的协调统一。
3、其二,在大多数语音驱动的动作生成方法中,动作的表示形式通常可分为基于关键点和基于旋转两类,chen等人(chen j,liu y,wang j,et al.diffsheg:a diffusion-based approach for real-time s peech-driven holistic 3d expression andgesture generation[c].proce edings of the ieee/cvf conference on computervision and patter n recognition(cvpr),2024)采用骨架关节在世界坐标系中的三维坐标位置作为运动序列的表示,尽管该表示能提供局部细节,但却不能限制全局形状,这可能导致后期可视化时骨架与虚拟人物网格的拟合结果过于僵硬,缺乏真实感。liu等人(liuh,zhu z,becher ini g,et al.emage:towards unified holistic co-speech gesturegeneration via masked audio gesture modeling[c].proceedings of the ieee/cvfconference on computer vision and pattern recogni tion(cvpr),2024)在训练时采用了6d表示,这种表示方式在轴-角空间中定义了参数,然而引入了运动学树可能会增加复杂性,导致出现滑步和不连续的现象。
4、其三,在早期方法中,常采用确定性模型,然而这类模型往往导致结果平均化,缺乏多样性,即一段音频只能生成固定的身体动作序列,这与传统认知不符。为了解决音频和动作之间的一对多关系,y i等人(yi h,liang h,liu y,et al.generating holistic 3dh uman motion from speech[c].proceedings of the ieee/cvf confer ence oncomputer vision and pattern recognition(cvpr),2023)提出了使用两个组合的向量量化变分自动编码器(vq-vae)和交叉条件自回归模型以增加生成结果的多样性,alexanderson等人(alexan derson s,henter g e,kucherenko t,et al.style-controllable speech-driven gesture synthesis using normalising flows[c].computer graphics forum(cgf),2020)提出了基于自回归归一化流的方法,给定一段语音,模型可以从概率分布中重复采样,从而生成不同动作。但它们的多样性仍然有限。
5、为了解决上述问题,本发明提出了一种语音驱动的全身动作生成方法。
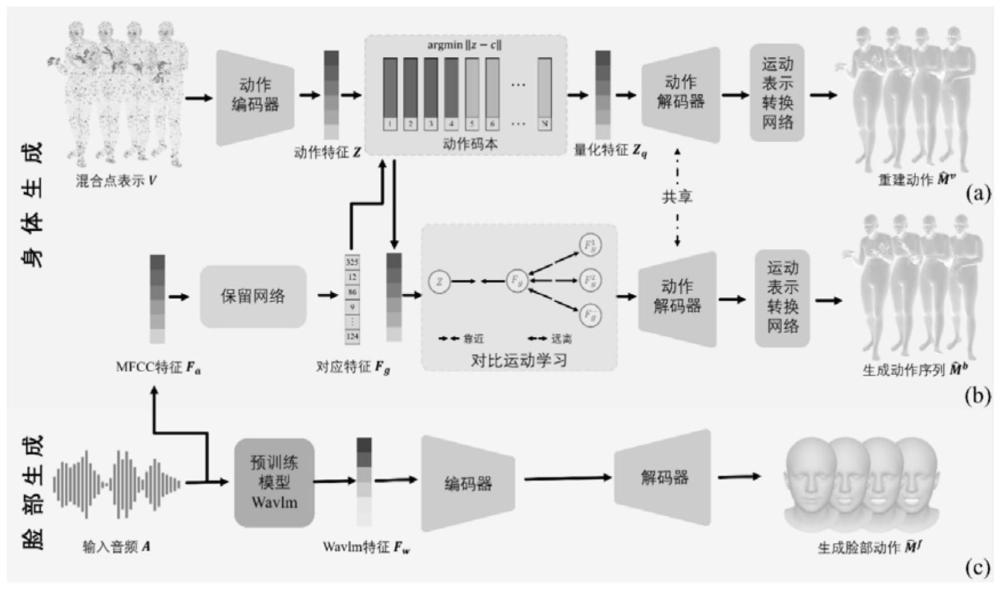
6、本发明针对以上问题,提出了一种在语音输入条件下进行三维人体全身动作生成的模型,为了产生更真实、连续的结果,设计了一种新的混合点表示法作为运动序列的表示形式,该表示在欧几里得空间中定义,易于网络学习,并且既包含了表面点的全局约束又保留了关节点的局部细节;为了增加生成结果的多样性,引入了一种新的对比运动学习法;为了高效地提供通用的smpl-x轴角表示,构建了运动表示转换网络。
技术实现思路
1、(一)本发明要解决的技术问题:
2、本发明的目的在于提出一种语音驱动的全身动作生成方法以解决现有方法在生成动作时缺乏连续性、真实性和多样性的问题;该方法在生成脸部动作方面,基于编-解码器,融合了音频的wavlm特征和说话人的独热编码特征,实现了自然的脸部序列生成;在生成身体动作方面,采用了基于向量量化变分自动编码器(vq-vae)和保留网络(retnet)的两阶段架构,在第一阶段中,引入了混合点表示法,将包含全局约束信息的表面点和包含局部细节的关节点结合起来,大幅提高了动作重建的准确性;在第二阶段,采用了对比运动学习法,将早期其他音频对应生成的运动序列的量化特征作为负样本,训练动作真值的量化特征作为正样本进行对比训练,增加了动作生成的多样性;为了高效地提供通用的输出表示,提供了一个运动表示转换网络,可将混合点表示转换为对应的smpl-x轴角表示。在语音驱动的全身动作生成的各个方法中,本发明各项指标均比现有最好的方法有所提升。
3、(二)为了实现上述目的,本发明采用了如下技术方案:
4、一种语音驱动的全身动作生成方法,包括如下步骤:
5、s1、对公共数据集进行数据预处理,使用smpl-x模型对动作序列进行建模,提取对应的关节点以及下采样表面点的三维位置;对原始音频进行特征提取,包括低层次特征(mfcc特征)和高层次特征(wavlm特征);将语音特征和对应的运动序列表示以成对的形式进行存储;
6、s2、对于语音驱动的脸部动作生成任务,采用编-解码器架构,融合音频的wavlm特征以及说话人的独热编码信息作为输入,编码器将融合特征编码成潜在空间表示,之后解码器将该表示解码为对应的脸部运动序列,从而保证了生成的脸部动作与语音内容和说话人特征保持一致性,使得生成的脸部动作更加自然和可信;
7、s3、对于语音驱动的身体动作生成任务,将代表身体自由度全局约束的下采样表面点和代表身体细粒度细节的关节点组合起来作为运动序列的表示形式;利用向量量化变分自动编码器来实现对运动序列的重建,首先将混合点表示的运动序列通过编码器映射到离散的低维潜在空间中,实现了对运动序列的编码;然后利用量化器将编码后的潜在特征映射到最近的码本向量;最后通过解码器将量化后的特征解码回原始的运动序列;为了实现更加准确的动作重建,这里使用了三个向量量化变分自动编码器,分别对全身、左手和右手进行重建;
8、s4、将原始运动序列在s3中的低维空间编码的码本索引进行随机掩码处理后与音频的mfcc特征以及说话人的标识编码信息进行融合,输入到保留网络中,自回归地生成运动序列的索引;将索引再输入到s3中的量化器中得到量化特征,通过解码器解码,获得混合点表示的运动序列;同时基于索引对应的量化特征,引入了对比运动学习法以提高生成结果的多样性;
9、s5、为了高效地提供通用的输出表示,设计了一个运动表示转换网络,将运动序列的混合点表示输入,输出对应的smpl-x轴角表示。
10、优选的,s1中所述的数据集预处理主要包括以下步骤:
11、s101、根据smplx内置函数,计算出对应姿态下人体网格内部的前55个关节点以及表面的10475个点的三维位置;对表面点进行下采样以保留重要特征并减少冗余的点,将其数量减少到431个;
12、s102、使用pytorch的torchaudio库提取音频的mfcc特征,包括音调、声音强度和频谱特征,作为低层次特征;利用语音预训练模型wavlm提取音频的语言学特征,包括语音内容、韵律特征,作为高层次特征。
13、优选的,s2中所述的语音驱动的脸部动作生成主要包括以下步骤:
14、s201、将音频的wavlm特征与说话人的独热编码特征信息卷积融合,然后通过由三个残差块和一个自注意力块构成的编码器进行特征的细化和自适应聚合,加入自注意力机制使编码器在特征的聚合过程中更加灵活地选择和调整重要的信息,提高了特征表示的自适应性和有效性;
15、s202、将经过编码器提取的中间表示作为输入,通过与编码器相同架构的解码器进行解码,以生成相应的人脸运动序列;在训练过程中,采用l1距离的重建损失来衡量编-解码器生成序列与真实序列之间的差异。
16、优选的,s3中所述的量化的运动重建任务主要包括以下步骤:
17、s301、给定一组随时间动态变化的混合点表示运动序列利用向量量化变分自动编码器学习低维潜在运动空间,首先利用编码器从输入的运动序列中得到运动特征其中量化特征的通道数为nz,时间窗口大小为wm,该编码器包含多个层级,在每个层级中都使用了残差块和注意力机制,能够有效地提取动作序列中的特征,同时通过下采样操作逐步降低了动作数据的分辨率,提高了对数据的抽象能力;
18、s302、将学习到的运动码本表示为其中n为码本的长度;对于每个特征zt∈z,量化器计算其与码本中各个向量的距离,并选择距离最近的码本向量作为量化后的特征表示:
19、ct=argmin||zt-ci||2
20、量化特征表示为这种硬编码的方式具有节省存储空间、计算速度快、稳定性高的优势;
21、s303、解码器接收量化后的特征表示,通过一系列中间层和上采样操作,逐步将低维的特征表示扩展为与原始运动序列相匹配的维度,以生成重建的运动序列
22、训练过程中,利用重建损失和向量量化损失来优化向量量化变分自动编码器;重建损失用于准确恢复运动序列的位置、速度和加速度:
23、
24、其中,v'和v”分别为运动序列v的一阶和二阶偏导数,α1和α2分别为对应项的权重。
25、向量量化损失用于对齐码本的向量空间和编码器的输出,包括码本损失和承诺损失两部分;码本损失旨在使码本的量化特征接近于编码器的输出,而承诺损失则旨在使编码器的输出接近码本中的向量:
26、lvq=||sg[z]-zq||2+β||z-sg[zq]||2
27、其中,sg[·]是停止梯度函数,第一项是码本损失,第二项是权重为β的承诺损失。
28、优选的,s4中所述的语音驱动的身体动作生成具体实现过程如下:
29、s401、为了提高模型的性能和泛化能力,首先对原始运动序列对应的s302中的码本索引进行了随机掩码,然后将码本索引与音频的mfcc特征以及编码后的说话人信息一起,通过堆叠的mlp网络进行特征信息融合,将融合特征输入到保留网络中,该网络使用了多尺度保留(msr)模块和前馈网络(ffn)模块用于捕捉序列中的长距离依赖关系,最后以自回归的方式生成动作的码本索引;在训练过程中,使用交叉熵损失衡量模型输出与真实索引之间的差异;
30、s402、使用码本索引在s302的码本中查找对应的量化特征,然后将这些量化特征输入到s303的解码器中,最终得到混合点表示的运动序列;
31、s403、引入对比运动学习法,将当前训练轮次中音频对应生成的运动序列在s402中的量化特征表示为p,l个早期其他音频对应生成运动序列的量化特征作为负样本训练动作真值的量化特征作为正样本p+,对比损失可表述为:
32、
33、通过使生成的特征尽可能与负样本区分开来,同时与正样本相似,以增强动作生成的多样性。
34、优选的,s5中所述的运动表示转换网络实现过程包括以下步骤:
35、运动表示转换网络的结构与s202中的解码器的结构相似,将s402中得到的运动序列的混合点表示输入到运动表示转换网络中,生成相应的smpl-x模型的3d轴角表示参数,这一转换为后续的应用提供了更通用的表示形式;在训练过程中,使用l1距离的重建损失来衡量运动表示转换网络生成序列与真实序列之间的差异。
36、(三)本发明的有益效果包括以下几点:
37、(1)本发明提出了一种语音驱动的全身动作生成方法,输入一段语音,采用上述方法可以生成更加真实、连续且多样的运动序列;本发明提出基于编-解码器架构的脸部生成框架,基于向量量化变分自动编码器(vq-vae)和保留网络(retnet)的两阶段身体动作生成框架;本发明提出了混合点表示法,将包含全局约束信息的表面点和包含局部细节的关节点结合起来;本发明引入对比运动学习法,提高了动作生成的多样性;本发明提出了一个运动表示转换网络,可高效地提供通用的smpl-x表示。
38、(2)本发明提出了一种语音驱动的全身动作生成方法,解决了现有技术中生成运动序列不真实、不连续、缺乏多样性且泛化能力弱的问题。
39、(3)本发明提出了混合点表示法,解决了现有方法生成动作不合理、不连续的问题,将代表身体自由度全局约束的下采样表面点与代表身体细粒度细节的关节点组合起来作为运动表示,从而提高了向量量化变分自动编码器在动作重建阶段的准确性;同时提供了一个运动表示转换网络,能够将混合点表示转换为对应的smpl-x轴角表示,以便后续应用。
40、(4)本发明引入了一种新的对比运动学习法,以早期其他音频对应生成运动序列的量化特征作为负样本,以真值运动序列的量化特征作为正样本进行对比训练,增加了动作生成的多样性。
41、(5)本发明中提出的一种语音驱动的全身动作生成方法,在公开数据集beat2上取得了最优的结果。
本文地址:https://www.jishuxx.com/zhuanli/20240905/288543.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表