基于多模态大模型的数据处理方法及装置与流程
- 国知局
- 2024-09-11 14:33:24
本申请涉及数据处理,尤其涉及一种基于多模态大模型的数据处理方法及装置。
背景技术:
1、多模态大模型是人工智能领域的重要研究方向,旨在将文本、图像、音频和视频等多种模态的信息整合到一个统一的模型框架中,从而实现更强大的理解和生成能力,在跨模态任务中展现出了巨大的潜力。然而,由于多模态数据在表示上的不一致性,多模态大模型在处理不同模态的数据时面临着诸多挑战。例如,图像数据和文本数据在结构和语义表达上存在显著差异:图像数据通常包含丰富的视觉信息,如颜色、形状、纹理,而文本数据则侧重于语义表达,如概念、关系、事件。目前,常用的多模态大模型的数据处理方法中,往往对不同模态的数据采取了不平衡的对待方式,极大地限制了模型在跨模态任务中的潜力和效能。
2、因此,迫切需要一种能够有效地解决多模态数据的不一致性问题的方法。
技术实现思路
1、本发明提供一种基于多模态大模型的数据处理方法及装置,用于解决多模态数据在图像数据和文本数据上表示不一致的问题。
2、第一方面,提供一种基于多模态大模型的数据处理方法。该方法包括:
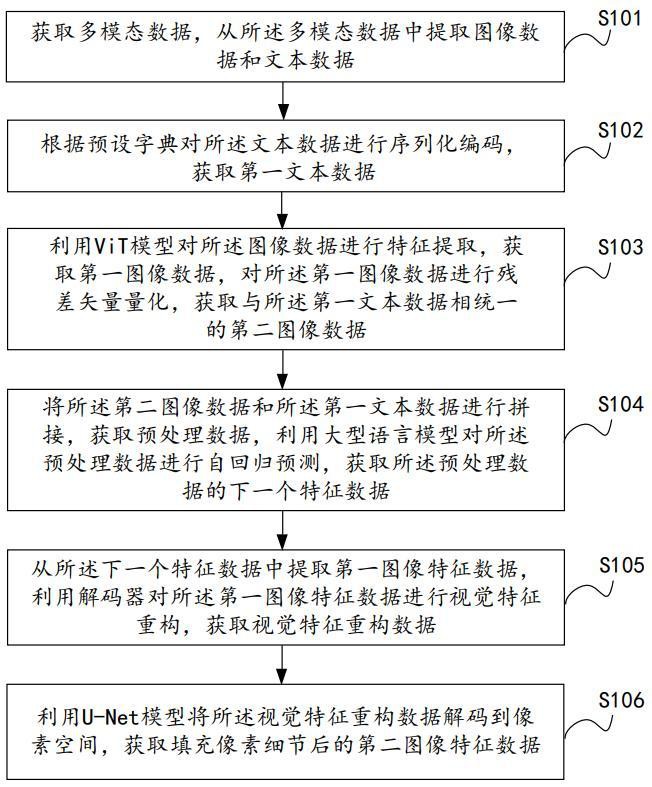
3、获取多模态数据,从多模态数据中提取图像数据和文本数据;
4、根据预设字典对文本数据进行序列化编码,获取第一文本数据;
5、利用vit模型对图像数据进行特征提取,获取第一图像数据,对第一图像数据进行残差矢量量化,获取与第一文本数据相统一的第二图像数据;
6、将第二图像数据和第一文本数据进行拼接,获取预处理数据,利用大型语言模型对预处理数据进行自回归预测,获取预处理数据的下一个特征数据;
7、从下一个特征数据中提取第一图像特征数据,利用解码器对第一图像特征数据进行视觉特征重构,获取视觉特征重构数据;
8、利用u-net模型将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据。
9、一种可能的设计方案中,对第一图像数据进行残差矢量量化,获取第二图像数据,包括,
10、根据预设代码本对第一图像数据进行最近邻搜索,获取初始量化数据,预设代码本中包括编码序号和嵌入表示;
11、根据预设量化深度和初始量化数据进行循环迭代的残差矢量计算,获取第一图像数据在量化深度为1到时的量化结果序列;
12、对量化结果序列进行求和计算,获取第二图像数据。
13、可选地,根据预设量化深度和初始量化数据进行循环迭代的残差矢量计算的公式如下:
14、,
15、其中,为量化数据在量化深度为d时的量化结果,为最近邻搜索,为量化深度为d-1时的残差,为预设代码本;
16、,
17、其中,为量化深度为d时的残差,为在代码本中的嵌入表示,当残差深度为0时,为初始量化数据。
18、可选地,当在最近邻搜索过程中出现不可导问题时,使用停止梯度传播方法,停止更新最近邻搜索过程中的梯度更新。
19、一种可能的设计方案中,解码器的训练目标定义如下:
20、,
21、其中为第一图像特征数据中的第i个特征数据,为多模态数据中的真实视觉嵌入中的第i个特征数据,为余弦相似度计算函数。
22、一种可能的设计方案中,利用u-net模型将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据,包括,
23、在u-net模型的训练过程中添加高斯噪声,对视觉特征重构数据进行条件去躁,获取填充像素细节后的第二图像特征数据。
24、可选地,u-net模型在训练时的优化函数如下:
25、,
26、其中,为期望函数,为高斯噪声,为视觉特征重构数据在解码扩散过程中的潜在状态,为时间,为视觉特征重构数据。
27、一种可能的设计方案中,利用vit模型对图像数据进行特征提取,获取第一图像数据,包括,
28、根据图像数据大小和预设图像块大小将图像数据切分成无重叠的图像块,利用vit模型对无重叠的图像块进行序列化特征提取,获取包含不同图像块特征的第一图像数据。
29、一种可能的设计方案中,将第二图像数据和第一文本数据进行拼接,获取预处理数据,包括,
30、在第二图像数据的开头插入一个[img]作为图像数据的开始标记,结尾插入一个[/img]作为图像数据的结束标记;
31、第二图像数据和第一文本数据的拼接形式包含[图像,文本]和[文本,图像]两种形式。
32、第二方面,提供一种基于多模态大模型的数据处理装置。该装置包括:
33、获取模块,用于获取多模态数据,从多模态数据中提取图像数据和文本数据;
34、文本预处理模块,用于根据预设字典对文本数据进行序列化编码,获取第一文本数据;
35、图像预处理模块,用于利用vit模型对图像数据进行特征提取,获取第一图像数据,对第一图像数据进行残差矢量量化,获取与第一文本数据相统一的第二图像数据;
36、预测模块,用于将第二图像数据和第一文本数据进行拼接,获取预处理数据,利用大型语言模型对预处理数据进行自回归预测,获取预处理数据的下一个特征数据;
37、视觉特征重构模块,用于从下一个特征数据中提取第一图像特征数据,利用解码器对第一图像特征数据进行视觉特征重构,获取视觉特征重构数据;
38、解码模块,用于利用u-net模型将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据。
39、本发明提供的基于多模态大模型的数据处理方法及装置,该方法包括:获取多模态数据,从多模态数据中提取图像数据和文本数据,利用vit模型对图像数据进行特征提取以及残差矢量量化,获取与经过序列化编码后的第一文本数据相统一的第二图像数据,再将第二图像数据和第一文本数据进行拼接,利用大型语言模型进行自回归预测,获取下一个特征数据,然后,从下一个特征数据中提取第一图像特征数据,对第一图像特征数据进行视觉特征重构,再将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据。也就是说,通过对图像数据进行特征提取以及残差矢量量化,使得第二图像数据与第一文本数据的维度相统一,解决了多模态数据在表示上的不一致问题,然后,利用大型语言模型进行自回归预测,获取下一个特征数据,从下一个特征数据中提取第一图像特征数据,对第一图像特征数据进行视觉特征重构,再将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据,解决了图像数据与文本数据相统一后的图像数据缺失问题,保证了最终预测的图像数据的完整性。
40、应当理解,技术实现要素:部分中所描述的内容并非旨在限定本发明的实施例的关键或重要特征,亦非用于限制本发明的范围。本发明的其它特征将通过以下的描述变得容易理解。
技术特征:1.一种基于多模态大模型的数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于多模态大模型的数据处理方法,其特征在于,所述对所述第一图像数据进行残差矢量量化,获取第二图像数据,包括,
3.根据权利要求2所述的基于多模态大模型的数据处理方法,其特征在于,所述根据预设量化深度和所述初始量化数据进行循环迭代的残差矢量计算的公式如下:
4.根据权利要求2所述的基于多模态大模型的数据处理方法,其特征在于,
5.根据权利要求1所述的基于多模态大模型的数据处理方法,其特征在于,所述解码器的训练目标定义如下:
6.根据权利要求1所述的基于多模态大模型的数据处理方法,其特征在于,所述利用u-net模型将所述视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据,包括,
7.根据权利要求6所述的基于多模态大模型的数据处理方法,其特征在于,所述u-net模型在训练时的优化函数如下:
8.根据权利要求1所述的基于多模态大模型的数据处理方法,其特征在于,所述利用vit模型对所述图像数据进行特征提取,获取第一图像数据,包括,
9.根据权利要求1所述的基于多模态大模型的数据处理方法,其特征在于,
10.一种基于多模态大模型的数据处理装置,其特征在于,所述装置包括:
技术总结本申请提供一种基于多模态大模型的数据处理方法及装置,涉及数据处理,包括:获取多模态数据,从多模态数据中提取图像数据和文本数据,利用ViT模型对图像数据进行特征提取以及残差矢量量化,获取与经过序列化编码后的第一文本数据相统一的第二图像数据,再将第二图像数据和第一文本数据进行拼接,利用大型语言模型进行自回归预测,获取下一个特征数据,然后,从下一个特征数据中提取第一图像特征数据,对第一图像特征数据进行视觉特征重构,再将视觉特征重构数据解码到像素空间,获取填充像素细节后的第二图像特征数据,在解决了多模态数据在图像数据和文本数据上表示不一致的问题的同时,确保了最终预测的第二图像特征数据的完整性。技术研发人员:白琳,杨良志,赵兴玉,唐丽萍,卢业波,邹盼湘,李自然,梁仕受保护的技术使用者:彩讯科技股份有限公司技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/291384.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。