基于深度神经网络的协调排程算法的制作方法
- 国知局
- 2024-09-11 14:59:43
本发明涉及机器学习,具体为基于深度神经网络的协调排程算法。
背景技术:
1、随着现代工业和信息化的发展,排程问题在众多领域中变得越来越重要,如生产制造、物流运输、服务调度等。排程算法的目标是在满足各种约束条件的前提下,对任务进行合理分配和调度,以达到优化资源利用、提高效率的目的。
2、传统的排程算法通常基于规则或数学模型进行优化,然而这些方法在处理复杂、动态的排程问题时存在一定的局限性。例如,规则方法可能无法适应多变的任务需求和环境变化,而数学模型方法则可能面临计算复杂度高、求解时间长等问题。为此,我们提出基于深度神经网络的协调排程算法。
技术实现思路
1、本发明的目的在于提供基于深度神经网络的协调排程算法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:基于深度神经网络的协调排程算法,所述算法的具体步骤包括:
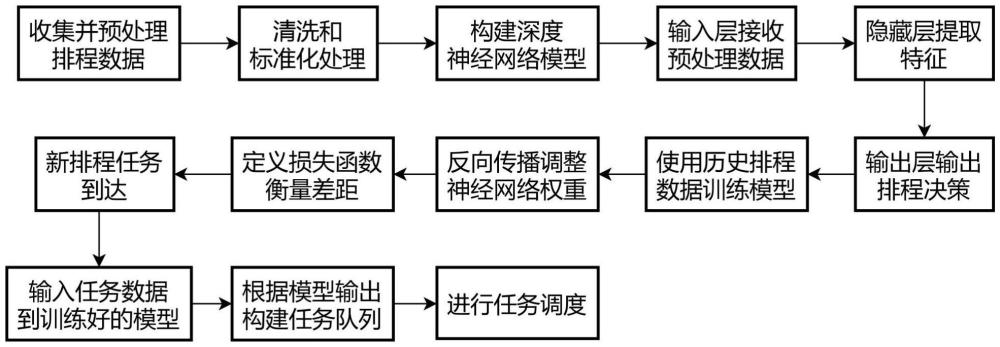
3、步骤ⅰ、收集并预处理排程数据,对所述数据进行清洗和标准化处理;
4、步骤ⅱ、构建深度神经网络模型,该模型包括输入层、多个隐藏层和输出层,其中输入层用于接收预处理后的排程数据,隐藏层通过非线性激活函数对输入数据进行逐层变换以提取特征,输出层用于输出排程决策;
5、步骤ⅲ、使用历史排程数据作为训练集,通过反向传播算法调整神经网络权重,并定义损失函数以衡量模型预测与实际排程结果之间的差距;
6、步骤ⅳ、当新的排程任务到达时,将任务数据输入到训练好的神经网络模型中,根据模型的输出构建任务队列,进行任务调度;
7、步骤ⅴ、定期对神经网络模型进行重新训练,并根据实际需要对模型结构、激活函数和训练策略进行调整。
8、优选的,设神经网络模型的权重为 ,偏置为 ,输入数据为 ,输出数据为 ,隐藏层的输出为 ,非线性激活函数为 ,则隐藏层的输出公式为:
9、
10、在模型训练过程中,使用反向传播算法调整神经网络权重,设学习率为 ,损失函数为 ,则权重的更新公式为:
11、
12、
13、其中,损失函数 用于平衡模型预测 与实际排程结果 之间的差距,采用均方误差mse作为损失函数进行计算;当新的排程任务到达时,将任务数据 输入到训练好的神经网络模型中,根据模型的输出 构建任务队列,进行任务调度。
14、优选的,在步骤ⅱ中,构建深度神经网络模型的具体步骤包括;
15、s1:数据收集,收集排程相关的数据,对收集的数据进行预处理,包括数据清洗和标准化,以消除异常值和量纲差异对模型训练的影响,形成规整的数据集;将处理后的数据集划分为训练集、验证集和测试集,其中训练集用于模型的训练,验证集用于模型效果的验证和优化,测试集用于在未知数据集上验证模型的泛化能力;
16、s2:构建深度神经网络模型,该模型由输入层、多个隐藏层和输出层构成,其中输入层设计为接收预处理后的排程数据,隐藏层通过非线性激活函数对数据进行特征提取,输出层负责产生排程决策;
17、s3:利用历史排程数据构成训练集,通过反向传播算法对神经网络进行权重调整,同时定义损失函数,用以量化模型预测结果与实际排程结果之间的差异;对神经网络模型进行训练,通过迭代优化过程,不断调整模型参数,直至模型预测结果与实际结果的差异达到最小化;
18、s4:定期对训练好的神经网络模型进行重新训练,以适应新的数据和环境变化,并根据需要对模型的结构、激活函数及训练策略进行相应的调整。
19、优选的,在完成模型训练后,使用独立的验证数据集对模型进行验证,验证数据集用于评估模型在未见过的数据上的性能,通过比较模型在验证集上的预测结果与实际排程结果,评估模型的泛化能力和预测准确性。
20、优选的,在模型训练过程中,对神经网络的超参数进行调优,所述超参数包括学习率、批次大小和迭代次数,通过尝试不同的超参数组合,找到使模型性能最佳的设置。
21、优选的,对收集的数据进行数据清洗的方式包括:
22、s1.1:缺失值处理,检查数据集中是否存在缺失值,对于存在缺失值的数据项,根据数据的业务逻辑,采用填充、插值或删除包含缺失值的数据记录方法进行处理;
23、s1.2:异常值检测与处理,利用业务规则,识别数据集中的异常值,对于检测到的异常值,根据其产生原因和对后续分析的影响,采取修正、替换或删除处理措施;
24、s1.3:重复值处理,检查数据集中是否存在重复的记录或数据项,对于重复的数据,根据数据的重要性和业务需求,选择保留首条记录、合并重复记录或删除重复数据方法进行处理;
25、s1.4:数据格式统一与转换,对于数据集中不同格式或单位的数据项,进行统一的格式转换和单位换算;
26、s1.5:无关数据剔除,根据排程问题的实际需求和数据分析目标,剔除与排程决策无关的数据项或特征。
27、优选的,对清洗后的数据进行标准化处理,具体实现方式为:针对每个特征维度,计算其均值和标准差;使用每个特征维度的均值和标准差,对该维度的数据进行标准化变换,将每个数据值减去均值,然后除以标准差,获得标准化后的数据。
28、优选的,协调排程算法中,评估深度神经网络的性能指标包括准确率和召回率,其中准确率用于衡量模型正确预测排程决策的比例,反映模型的整体预测能力;召回率用于评估模型对于重要排程事件的敏感度,针对某一特定排程决策,衡量模型正确预测出该决策的比例。
29、与现有技术相比,本发明的有益效果是:
30、1,提高排程决策的智能化水平:通过引入深度神经网络,本算法能够自动学习和识别排程数据中的复杂模式和关联,从而做出更智能、更精准的排程决策。这大大降低了对人工经验和规则的依赖,提高了排程的自动化和智能化程度。
31、2,优化资源利用与效率:本算法通过神经网络的强大学习能力,能够在满足各种约束条件的前提下,对任务进行合理分配和调度,实现资源的最优利用。这不仅可以减少资源浪费,还能显著提高工作效率和生产效益。
32、3,适应复杂多变的排程需求:传统的排程方法在面对复杂、动态的任务需求时往往显得力不从心。而本算法通过神经网络的非线性映射能力,能够更好地适应多变的任务需求和环境变化,提供灵活且高效的排程解决方案。
技术特征:1.基于深度神经网络的协调排程算法,其特征在于,所述算法的具体步骤包括:
2.根据权利要求1所述的基于深度神经网络的协调排程算法,其特征在于,设神经网络模型的权重为 ,偏置为 ,输入数据为 ,输出数据为 ,隐藏层的输出为 ,非线性激活函数为 ,则隐藏层的输出公式为:
3.根据权利要求2所述的基于深度神经网络的协调排程算法,其特征在于,在步骤ⅱ中,构建深度神经网络模型的具体步骤包括;
4.根据权利要求3所述的基于深度神经网络的协调排程算法,其特征在于:在完成模型训练后,使用独立的验证数据集对模型进行验证,验证数据集用于评估模型在未见过的数据上的性能,通过比较模型在验证集上的预测结果与实际排程结果,评估模型的泛化能力和预测准确性。
5.根据权利要求4所述的基于深度神经网络的协调排程算法,其特征在于:在模型训练过程中,对神经网络的超参数进行调优,所述超参数包括学习率、批次大小和迭代次数,通过尝试不同的超参数组合,找到使模型性能最佳的设置。
6.根据权利要求5所述的基于深度神经网络的协调排程算法,其特征在于,对收集的数据进行数据清洗的方式包括:
7.根据权利要求6所述的基于深度神经网络的协调排程算法,其特征在于,对清洗后的数据进行标准化处理,具体实现方式为:针对每个特征维度,计算其均值和标准差;使用每个特征维度的均值和标准差,对该维度的数据进行标准化变换,将每个数据值减去均值,然后除以标准差,获得标准化后的数据。
8.根据权利要求7所述的基于深度神经网络的协调排程算法,其特征在于:在协调排程算法中,评估深度神经网络的性能指标包括准确率和召回率,其中准确率用于衡量模型正确预测排程决策的比例,反映模型的整体预测能力;召回率用于评估模型对于重要排程事件的敏感度,针对某一特定排程决策,衡量模型正确预测出该决策的比例。
技术总结本发明涉及机器学习技术领域,公开了基于深度神经网络的协调排程算法,该算法通过收集并预处理排程数据,构建深度神经网络模型,利用历史排程数据进行训练,优化神经网络权重。当新任务到达时,算法将任务数据输入训练好的模型中,根据输出构建任务队列进行调度。此外,算法还具备定期重新训练和调整模型结构、激活函数及训练策略的能力,以适应不断变化的任务需求和环境,本发明能有效提高排程决策的智能化水平,优化资源利用,提升工作效率,同时降低计算复杂度和求解时间,特别适用于生产制造、物流运输、服务调度等领域中的动态、复杂排程场景。技术研发人员:包正伟,林国军受保护的技术使用者:宁波极望信息科技有限公司技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/292800.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。