一种基于动态密码声纹鉴权的机器人临时控制方法及系统与流程
- 国知局
- 2024-09-11 14:59:33
本发明属于音频特征处理领域,特别涉及一种基于动态密码声纹鉴权的机器人临时控制方法及系统。
背景技术:
1、随着智能家居和智能机器人进入家庭及相关行业应用,智能语音交互成为一种更加便利,更加快捷的交互方式。语音交互技术在给用户带来便利的同时也带来了另一个需求,那就是声纹识别。声纹识别(voiceprint recognition,vpr),也称为说话人识别(speakerrecognition),其可以实现说话人辨认(speaker identification)或说话人确认(speakerverification)的功能。说话人辨认是指判断某段语音是若干人中的哪一个所说的,是“多选一”问题;而说话人确认是指确认某段语音是否是指定的某个人所说的,是“一对一判别”问题。
2、随着信息安全和身份验证需求的增加,声纹识别作为一种非侵入性、便捷和高度可靠的生物识别技术,得到了广泛的应用和研究。在机器人控制控制领域,用声纹进行鉴权分析,每次人员要指挥机器人时,首先呼叫其编号或名称,语音识别进行全部文字化转变,发现其中相关的指令需要鉴权,就要对之前呼叫的编号或名称进行声纹分析。发现是授权用户,就直接执行对应的命令,如果不是则提示操作。对声纹鉴权的准确率有较高的要求。
3、公开号为cn116013324a的中国发明专利申请公开了一种基于声纹识别的机器人语音控制权限管理方法,包括以下步骤:用户登录,发出语音指令;机器人接收语音指令;采用声纹识别模块对语音指令中的声纹信息进行声纹识别,验证语音指令发出者的身份;声纹识别成功,通过语音识别模块识别语音指令中的语音内容并通过机器人控制模块执行语音指令。通过在机器人语音控制系统中加入声纹识别模块,该模块的作用是鉴别语音指令发出者的身份,只有当说话者的身份与当前登录用户的身份一致时,机器人才执行语音指令,否则不予执行。
4、该方案进行声纹特征提取及匹配,存在效率及准确率较低的问题,同时存在者多用户下,不同用户权限和命令时效性控制的问题,无法满足准确率精准要求较高的行业机器人控制领域的需求。
技术实现思路
1、本发明提供一种基于动态密码声纹鉴权的机器人临时控制方法及系统,旨在解决现有语音控制中声纹匹配时效率、准确率不足以及无法满足多用户权限分配的问题。
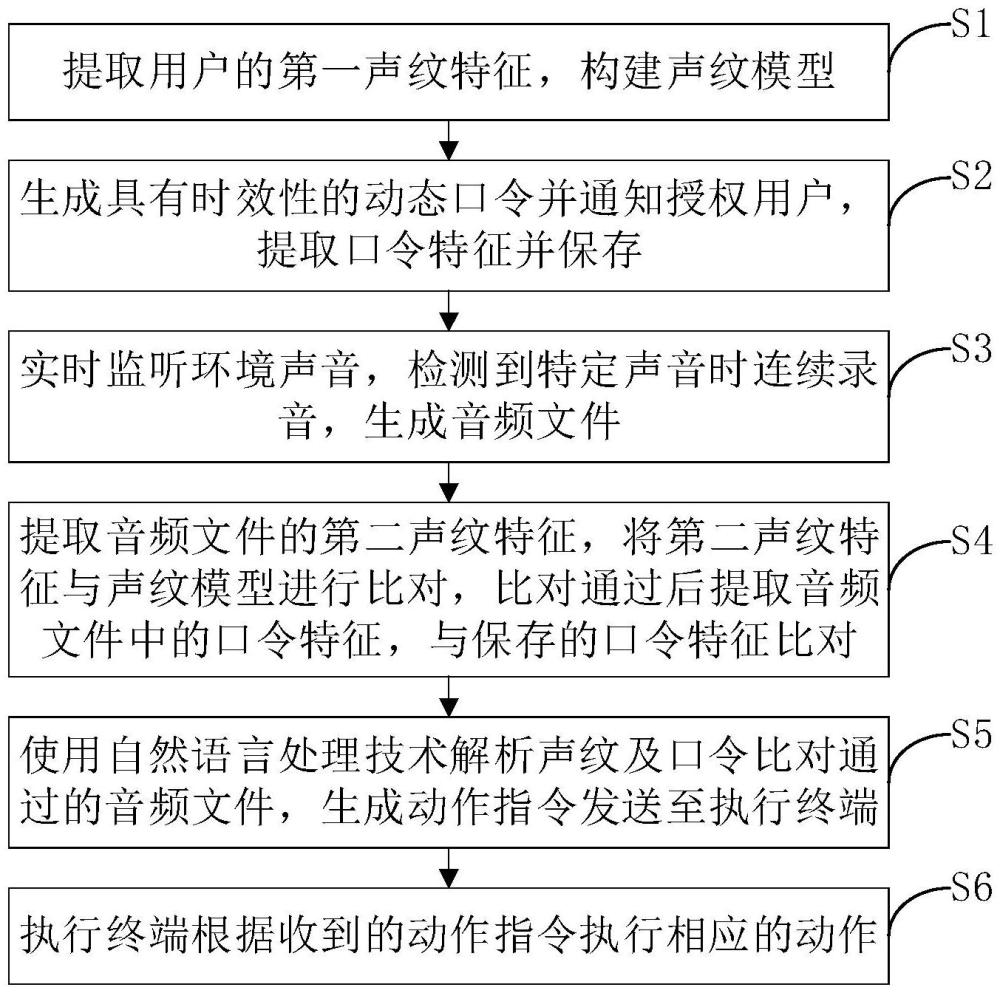
2、为解决上述技术问题,本发明的第一方面提出一种基于动态密码声纹鉴权的机器人临时控制方法,包括以下步骤:
3、s1:提取用户的第一声纹特征,构建声纹模型;
4、s2:生成具有时效性的动态口令并通知授权用户,提取口令特征并保存;
5、s3:实时监听环境声音,检测到关键词时连续录音,生成音频文件;
6、s4:提取所述音频文件的第二声纹特征,将所述第二声纹特征与声纹模型进行比对,比对通过后提取所述音频文件中的口令特征,与保存的口令特征比对;
7、s5:使用自然语言处理技术解析第二声纹特征及口令特征均比对通过的音频文件,生成动作指令发送至执行终端;
8、s6:执行终端根据收到的动作指令执行相应的动作。
9、优选地,所述步骤s4还对音频文件进行预处理,所述预处理包括去噪、降噪、语音活动检测,所述去噪使用频谱减法、自适应滤波及深度学习方法中的一种,所述降噪使用静声抑制、自适应滤波及深度学习方法中的一种,所述语音活动检测使用能量阈值、频谱特征及深度学习方法中的一种。
10、优选地,所述第一声纹特征及第二声纹特征包括频谱特征、声调特征及时长特征,将频谱特征、声调特征及时长特征组合成一个综合特征向量,作为最终的声纹特征,组合方法如下:
11、使用均值归一化或标准分数对频谱特征、声调特征及时长特征分别进行标准化处理;
12、将标准化后的频谱特征、声调特征和时长特征进行串联,形成一个高维向量作为综合特征向量。
13、优选地,所述频谱特征的提取方法如下:
14、使用音频处理库加载音频文件,获取音频数据及对应的采样率,对音频信号进行去噪、归一化操作,将音频信号分割成短时帧,并在每帧上加窗,对每一帧应用快速傅里叶变换,得到频谱;
15、将频谱转换到梅尔尺度,得到梅尔频谱图;
16、对梅尔频谱图进行对数变换,得到对数梅尔频谱图;
17、从对数梅尔频谱图中提取梅尔频率倒谱系数作为频谱特征。
18、优选地,所述声调特征的提取方法如下:
19、使用音频处理库加载音频文件,获取音频数据及对应的采样率,对音频信号进行去噪、归一化操作,将音频信号分割成短时帧,并在每帧上加窗,对每一帧应用快速傅里叶变换,得到频谱;
20、将频谱映射到12个独立的chroma向量,每个向量表示音阶的一个半音;
21、对于频率范围内的每个半音,计算该半音中所有频率的能量和,并分配到对应的chroma向量中;
22、对每个chroma向量进行归一化,使得每个chroma向量中元素之和为1,得到最终的声调特征向量。
23、优选地,所述时长特征的提取方法如下:
24、使用音频处理库加载音频文件,获取音频数据及对应的采样率;
25、计算音频文件中音频信号的总时长;
26、使用语音活动检测方法将音频信号分割成单个音素或语音段,计算每个音素或语音段的时长;
27、将总时长、每个音素或语音段的时长等特征组合起来,形成时长特征向量。
28、优选地,所述第一声纹特征及第二声纹特征还包括基音周期,将频谱特征、声调特征、时长特征及基音周期组合成一个综合特征向量,所述基音周期的提取方法如下:
29、使用音频处理库加载音频文件,获取音频数据和采样率,对音频信号进行去噪、归一化操作,将音频信号分割成短时帧,并对每一帧加窗;对每一帧信号计算自相关函数,寻找自相关函数中的峰值,确定峰值对应的延迟,基音周期对应于自相关函数的第一个明显峰值的延迟。
30、优选地,所述自相关函数定义为:
31、
32、式中,x(t)是音频信号,τ是延迟,n是帧长。
33、优选地,所述声纹模型采用动态时间规整、高斯混合模型及支持向量机中的一种方法构建。
34、优选地,所述执行终端在执行动作指令前还进行指令冲突检测,所述指令冲突检测方法如下:
35、执行终端检测待执行的动作指令,将待执行的动作指令分类为原子性指令或非原子性指令;
36、根据指令类别选择不同执行方式:对于可执行的原子性指令,执行终端根据原子性指令执行相应的动作;对于存在指令冲突或无法执行的原子性指令,执行终端拒绝执行并提供反馈,然后等待下一条原子性指令;对于非原子性指令,则检查执行终端当前的状态,若执行终端状态为空闲则执行所述非原子性指令,若执行终端正忙则提供反馈。
37、本发明的第二方面,还提出一种基于动态密码声纹鉴权的机器人临时控制系统,所述控制系统执行如第一方面所述的控制方法,包括:音频接收模块、预处理模块、声纹提取模块、模型构建模块、数据库模块及指令生成模块;
38、所述音频接收模块用于监测环境中的特定声音后记录生成音频文件;
39、所述预处理模块对音频文件进行预处理,所述预处理包括去噪、降噪、语音活动检测,所述去噪使用频谱减法、自适应滤波及深度学习方法中的一种,所述降噪使用静声抑制、自适应滤波及深度学习方法中的一种,所述语音活动检测使用能量阈值、频谱特征及深度学习方法中的一种;
40、所述声纹提取模块提取第一声纹特征及第二声纹特征,所述第一声纹特征及第二声纹特征均包括频谱特征、声调特征及时长特征,使用均值归一化或标准分数对频谱特征、声调特征及时长特征分别进行标准化处理,然后将标准化后的频谱特征、声调特征和时长特征进行串联,形成一个高维向量作为综合特征向量;所述声纹提取模块还提取动态口令的口令特征,发送至数据库模块保存;所述模型构建模块用于根据第一声纹特征采用动态时间规整、高斯混合模型及支持向量机中的一种方法构建声纹模型,还用于更新声纹模型;
41、所述数据库模块用于存储声纹模型及口令特征,并根据匹配请求进行声纹匹配及口令匹配;
42、所述指令生成模块使用自然语言处理技术解析比对成功的音频文件,生成动作指令发送至执行终端。
43、与现有技术相比,本发明具有以下技术效果:
44、1.本发明提出的机器人临时控制方法的实时声纹提取算法,能够快速准确地从短时录音中提取声纹特征;对于同时存在多用户的情况下,提供不同的用户权限。
45、2.本发明提出的机器人临时控制方法将频谱特征、声调特征、时长特征及基音周期组合生成一个综合的声纹特征,并使用该综合特征进行比对匹配,相对于单独使用一种特征进行比对匹配,可有效提高提高识别准确率,增强鲁棒性以及增加声纹特征的区分能力。
46、3.本发明提出的机器人临时控制方法使用高斯混合模型或支持向量机算法将综合特征向量构建为声纹模型,可描述语音信号中的多模态分布,从而更精确地捕捉每个说话者的声纹特征,以及可在高维特征空间中寻找最优分类超平面,能够有效处理复杂分类问题,提高识别的准确性。
47、4.本发明提出的机器人临时控制方法在使用前事先生成具有时效性的动态口令,使用时同时识别使用者的声纹特征和动态口令,同时可设置不同用户命令的时效,提高系统的安全性。
本文地址:https://www.jishuxx.com/zhuanli/20240911/292789.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。