语音识别方法、装置、电子设备、存储介质及程序产品与流程
- 国知局
- 2024-09-11 14:17:12
所属的技术人员能够理解,本技术的各个方面可以实现为系统、方法或程序产品。因此,本技术的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。示例性电子设备在介绍了本技术示例性实施方式的针对数据仓库取数接口的开发方法、介质和装置之后,接下来,参考图13对本技术示例性实施方式的电子设备进行说明。图13显示的电子设备1300仅仅是一个示例,不应对本技术实施例的功能和适用范围带来任何限制。如图13所示,电子设备1300以通用电子设备的形式表现。电子设备1300的组件可以包括但不限于:至少一个处理单元1310、至少一个存储单元1320、连接不同系统组件(包括存储单元1320和处理单元1310)的总线1330。其中,存储单元存储有程序代码,程序代码可以被处理单元1310执行,使得处理单元1310执行本技术上述“示例性方法”部分中描述的根据本技术各种示例性实施方式的步骤。在一些实施例中,处理单元1310可以执行上述实施例。存储单元1320可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(ram)1321和/或高速缓存存储单元1322,还可以进一步包括只读存储单元(rom)1323。存储单元1320还可以包括具有一组(至少一个)程序模块1325的程序/实用工具1324,这样的程序模块1325包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。总线1330可以包括数据总线、地址总线和控制总线。电子设备1300也可以与一个或多个外部设备1340(例如键盘、指向设备、蓝牙设备等)通信,这种通信可以通过输入/输出(i/o)接口1350进行。并且,电子设备1300还可以通过网络适配器1360与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图13所示,网络适配器1360通过总线1330与电子设备1300的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备1300使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本技术实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中或网络上,包括若干指令以使得一台电子设备(可以是个人计算机、服务器、终端装置、或者网络设备等)执行根据本技术实施例的方法。应当注意,尽管在上文详细描述中提及了针对数据仓库取数接口的开发装置的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本技术实施例,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。此外,尽管在附图中以特定顺序描述了本技术方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。虽然已经参考若干具体实施方式描述了本技术的精神和原理,但是应该理解,本技术并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本技术旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。本技术实施例还提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当计算机可读代码在电子设备的处理器中运行时,电子设备中的处理器上述任意实施方式的方法。
背景技术:
1、本部分旨在为权利要求书中陈述的本技术的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
2、在语音识别场景中,服务端通常在接收到客户端发送的语音数据时,实时将接收的语音数据进行语音识别,获得语音识别结果。但是,采用这种方式进行语音识别时,图形处理器(graphics processing unit,gpu)的利用率以及语音识别速率较低。
技术实现思路
1、相关技术在语音识别时gpu利用率以及语音识别速率较低。为此,在本上下文中,本技术的实施方式期望提供一种语音识别方法、装置、电子设备、存储介质及程序产品。
2、一方面,本技术实施例中提供了一种语音识别方法,包括:
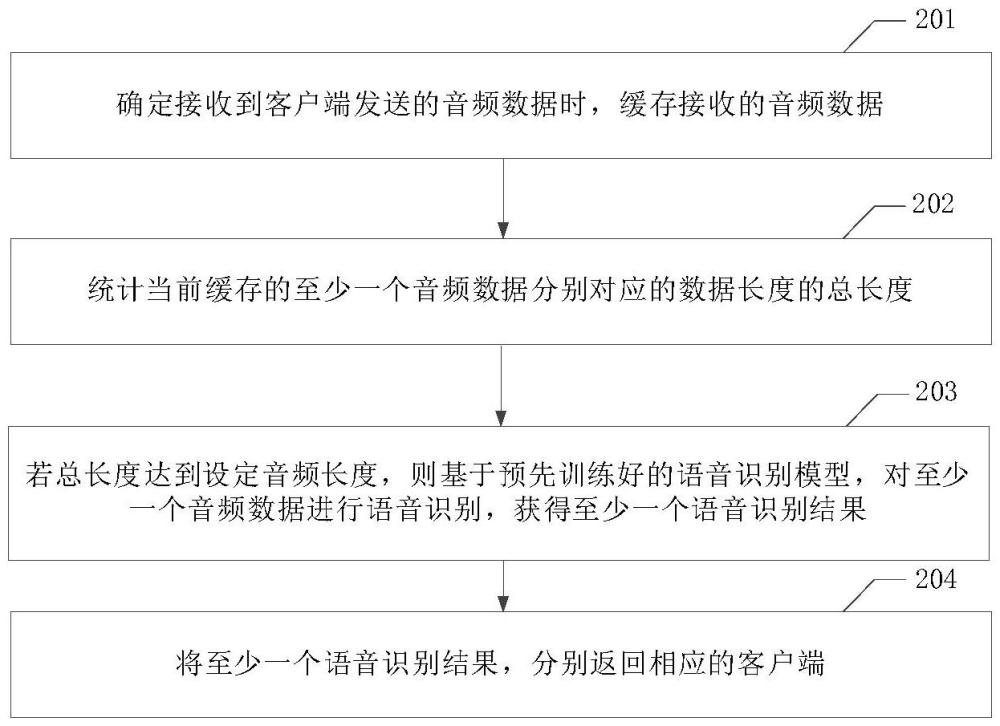
3、确定接收到客户端发送的音频数据时,缓存接收的音频数据;
4、统计当前缓存的至少一个音频数据分别对应的数据长度的总长度;
5、若总长度达到设定音频长度,则基于预先训练好的语音识别模型,对至少一个音频数据进行语音识别,获得至少一个语音识别结果;
6、将至少一个语音识别结果,分别返回相应的客户端。
7、一种实施方式中,确定接收到客户端发送的音频数据时,缓存接收的音频数据,包括:
8、通过第一线程,执行以下步骤:
9、确定监听到客户端发送的音频数据时,对音频数据进行脉冲编码调制编码,获得编码后的音频数据;
10、将编码后的音频数据,缓存至输入队列。
11、一种实施方式中,统计当前缓存的至少一个音频数据分别对应的数据长度的总长度,包括:
12、通过第二线程,执行以下步骤:
13、对输入队列进行监听;
14、确定监听到输入队列中添加新的音频数据时,统计输入队列中的至少一个音频数据分别对应的数据长度的总长度。
15、一种实施方式中,若总长度达到设定音频长度,则基于预先训练好的语音识别模型,对至少一个音频数据进行语音识别,获得至少一个语音识别结果,包括:
16、通过第二线程,执行以下步骤:
17、若总长度达到设定音频长度,则从输入队列中取出缓存的音频数据;
18、从至少一个音频数据中,筛选出包含语音片段的音频数据;
19、采用批处理的方式,对筛选出的至少一个音频数据分别进行预处理,分别获得每一音频数据对应的语音填充数据以及掩码矩阵;
20、将至少一个语音填充数据及其对应的掩码矩阵输入语音识别模型,获得至少一个语音识别结果。
21、一种实施方式中,对筛选出的至少一个音频数据分别进行预处理,分别获得每一音频数据对应的语音填充数据以及掩码矩阵,包括:
22、分别针对每一音频数据,执行以下步骤:
23、对音频数据进行特征提取,获得语音提取特征;
24、将语音提取特征,进行数据填充,获得音频数据对应的语音填充数据;
25、根据语音填充数据中分别包含的填充数据,生成音频数据对应的掩码矩阵。
26、一种实施方式中,从至少一个音频数据中,筛选出包含语音片段的音频数据,包括:
27、对至少一个音频数据分别进行语音活性检测;语音活性检测用于识别音频数据是否为包含语音片段;
28、从至少一个音频数据中,筛选出语音活性检测结果为包含语音片段的音频数据。
29、一种实施方式中,在将至少一个语音识别结果,分别返回相应的客户端之前,方法还包括:
30、根据语音活性检测结果,将未包含语音片段的音频数据对应的语音识别结果,设置为指定识别结果。
31、一种实施方式中,语音识别模型包括声学引擎、解码器以及标点模型;
32、将至少一个语音填充数据及其对应的掩码矩阵输入语音识别模型,获得至少一个语音识别结果,包括:
33、将至少一个语音填充数据及其分别对应的掩码矩阵,输入声学引擎,分别获得每一音频数据对应的注意力分布结果;注意力分布结果用于表示音频数据对应的字符概率分布;
34、根据解码器,对至少一个注意力分布结果分别进行解码,分别获得每一注意力分布结果对应的初始识别文本;
35、将至少一个初始识别文本,输入标点模型,分别获得每一初始识别文本对应的语音识别结果;语音识别结果用于表示相应音频数据对应的包含标点符号的文本。
36、一种实施方式中,将至少一个语音填充数据及其分别对应的掩码矩阵,输入声学引擎,分别获得每一音频数据对应的注意力分布结果,包括:
37、对至少一个语音填充数据进行下采样,分别获得每一语音填充数据的下采样数据;
38、根据至少一个下采样数据及其分别对应的掩码矩阵,进行拼接处理,获得二维输入特征矩阵;
39、根据至少一个下采样数据及其分别对应的掩码矩阵,分别确定每一音频数据对应的语音长度;
40、根据至少一个语音长度,生成长度矩阵;
41、采用分类函数,根据二维输入特征矩阵以及长度矩阵,进行注意力分布计算,获得至少一个注意力分布结果。
42、一种实施方式中,采用分类函数,根据二维输入特征矩阵以及长度矩阵,进行注意力分布计算,获得至少一个注意力分布结果,包括:
43、根据长度矩阵,将二维输入特征矩阵中的各元素进行划分,获得至少一个音频数据分别对应的向量集合;
44、分别针对每一音频数据的向量集合,执行以下步骤:
45、确定向量集合中各元素的最大元素值;
46、采用分类函数,根据向量集合中各元素的元素值,以及最大元素值,分别确定每一元素对应的字符分布值;
47、根据确定出的至少一个字符分布值,组成音频数据对应的注意力分布结果。
48、一种实施方式中,根据解码器,对至少一个注意力分布结果分别进行解码,分别获得每一注意力分布结果对应的初始识别文本,包括:
49、对至少一个音频数据的注意力分布结果进行填充,分别获得每一音频数据对应的注意力分布填充数据;
50、对至少一个注意力分布填充数据进行解码处理,分别获得每一音频数据对应的解码数据;
51、根据至少一个音频数据对应的掩码矩阵,分别对每一解码数据进行反填充处理,获得至少一个初始识别文本。
52、一种实施方式中,将至少一个初始识别文本,输入标点模型,分别获得每一初始识别文本对应的语音识别结果,包括:
53、采用分类函数,对至少一个初始识别文本进行注意力分布计算,获得语义分布结果;
54、根据至少一个初始识别文本分别对应的语义分布结果,对至少一个初始识别文本分别添加标点符号,获得至少一个语音识别结果。
55、一种实施方式中,将至少一个语音识别结果,分别返回相应的客户端,包括:
56、通过第二线程,执行以下步骤:
57、确定获得至少一个音频数据分别对应的语音识别结果时,将至少一个语音识别结果发送至输出队列;
58、监听到输出队列中存在语音识别结果时,将输出队列中的语音识别结果,分别发送至相应的客户端。
59、一方面,本技术实施例中提供了一种语音识别装置,包括:
60、缓存单元,用于确定接收到客户端发送的音频数据时,缓存接收的音频数据;
61、统计单元,用于统计当前缓存的至少一个音频数据分别对应的数据长度的总长度;
62、识别单元,用于若总长度达到设定音频长度,则基于预先训练好的语音识别模型,对至少一个音频数据进行语音识别,获得至少一个语音识别结果;
63、返回单元,用于将至少一个语音识别结果,分别返回相应的客户端。
64、一种实施方式中,缓存单元用于:
65、通过第一线程,执行以下步骤:
66、确定监听到客户端发送的音频数据时,对音频数据进行脉冲编码调制编码,获得编码后的音频数据;
67、将编码后的音频数据,缓存至输入队列。
68、一种实施方式中,统计单元用于:
69、通过第二线程,执行以下步骤:
70、对输入队列进行监听;
71、确定监听到输入队列中添加新的音频数据时,统计输入队列中的至少一个音频数据分别对应的数据长度的总长度。
72、一种实施方式中,识别单元用于:
73、通过第二线程,执行以下步骤:
74、若总长度达到设定音频长度,则从输入队列中取出缓存的音频数据;
75、从至少一个音频数据中,筛选出包含语音片段的音频数据;
76、采用批处理的方式,对筛选出的至少一个音频数据分别进行预处理,分别获得每一音频数据对应的语音填充数据以及掩码矩阵;
77、将至少一个语音填充数据及其对应的掩码矩阵输入语音识别模型,获得至少一个语音识别结果。
78、一种实施方式中,识别单元用于:
79、分别针对每一音频数据,执行以下步骤:
80、对音频数据进行特征提取,获得语音提取特征;
81、将语音提取特征,进行数据填充,获得音频数据对应的语音填充数据;
82、根据语音填充数据中分别包含的填充数据,生成音频数据对应的掩码矩阵。
83、一种实施方式中,识别单元用于:
84、对至少一个音频数据分别进行语音活性检测;语音活性检测用于识别音频数据是否为包含语音片段;
85、从至少一个音频数据中,筛选出语音活性检测结果为包含语音片段的音频数据。
86、一种实施方式中,返回单元还用于:
87、根据语音活性检测结果,将未包含语音片段的音频数据对应的语音识别结果,设置为指定识别结果。
88、一种实施方式中,语音识别模型包括声学引擎、解码器以及标点模型;
89、一种实施方式中,语音识别模型包括声学引擎、解码器以及标点模型;
90、识别单元用于:
91、将至少一个语音填充数据及其分别对应的掩码矩阵,输入声学引擎,分别获得每一音频数据对应的注意力分布结果;注意力分布结果用于表示音频数据对应的字符概率分布;
92、根据解码器,对至少一个注意力分布结果分别进行解码,分别获得每一注意力分布结果对应的初始识别文本;
93、将至少一个初始识别文本,输入标点模型,分别获得每一初始识别文本对应的语音识别结果;语音识别结果用于表示相应音频数据对应的包含标点符号的文本。
94、一种实施方式中,识别单元用于:
95、对至少一个语音填充数据进行下采样,分别获得每一语音填充数据的下采样数据;
96、根据至少一个下采样数据及其分别对应的掩码矩阵,进行拼接处理,获得二维输入特征矩阵;
97、根据至少一个下采样数据及其分别对应的掩码矩阵,分别确定每一音频数据对应的语音长度;
98、根据至少一个语音长度,生成长度矩阵;
99、采用分类函数,根据二维输入特征矩阵以及长度矩阵,进行注意力分布计算,获得至少一个注意力分布结果。
100、一种实施方式中,识别单元用于:
101、根据长度矩阵,将二维输入特征矩阵中的各元素进行划分,获得至少一个音频数据分别对应的向量集合;
102、分别针对每一音频数据的向量集合,执行以下步骤:
103、确定向量集合中各元素的最大元素值;
104、采用分类函数,根据向量集合中各元素的元素值,以及最大元素值,分别确定每一元素对应的字符分布值;
105、根据确定出的至少一个字符分布值,组成音频数据对应的注意力分布结果。
106、一种实施方式中,识别单元用于:
107、对至少一个音频数据的注意力分布结果进行填充,分别获得每一音频数据对应的注意力分布填充数据;
108、对至少一个注意力分布填充数据进行解码处理,分别获得每一音频数据对应的解码数据;
109、根据至少一个音频数据对应的掩码矩阵,分别对每一解码数据进行反填充处理,获得至少一个初始识别文本。
110、一种实施方式中,识别单元用于:
111、采用分类函数,对至少一个初始识别文本进行注意力分布计算,获得语义分布结果;
112、根据至少一个初始识别文本分别对应的语义分布结果,对至少一个初始识别文本分别添加标点符号,获得至少一个语音识别结果。
113、一种实施方式中,返回单元用于:
114、通过第二线程,执行以下步骤:
115、确定获得至少一个音频数据分别对应的语音识别结果时,将至少一个语音识别结果发送至输出队列;
116、监听到输出队列中存在语音识别结果时,将输出队列中的语音识别结果,分别发送至相应的客户端。
117、一方面,本技术实施例中提供了一种电子设备,包括:
118、处理器;以及
119、存储器,存储有计算机指令,计算机指令用于使处理器执行如上述任一种语音识别的各种可选实现方式中提供的方法的步骤。
120、一方面,本技术实施例中提供了一种计算机可读存储介质,存储有计算机指令,计算机指令用于使计算机执行如上述任一种语音识别的各种可选实现方式中提供的方法的步骤。
121、一方面,本技术实施例中提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当计算机可读代码在电子设备的处理器中运行时,电子设备中的处理器执行如上述任一种语音识别的各种可选实现方式中提供的方法的步骤。
122、根据本技术实施例的方案,确定接收到客户端发送的音频数据时,缓存接收的音频数据;统计当前缓存的至少一个音频数据分别对应的数据长度的总长度;若总长度达到设定音频长度,则基于预先训练好的语音识别模型,对至少一个音频数据进行语音识别,获得至少一个语音识别结果;将至少一个语音识别结果,分别返回相应的客户端。这样,将按照设定音频长度,对客户端的各音频数据进行批处理并行运算,提高了gpu的利用率以及语音识别速率。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290017.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。