一种同时去除多类型噪声的方法及系统
- 国知局
- 2024-09-05 14:24:32
本发明涉及噪声处理领域,更具体地说,涉及一种同时去除多类型噪声的方法及系统。
背景技术:
1、在当今社会,人们在自然环境中经常会受到多种类型噪声的干扰,如交通噪声、工业噪声、风声等。并且这些不同类型的噪声往往是以复杂的方式相互叠加、混合出现在人们的生活中,比如交通噪声也时常伴随着风声、动物的叫声等,不同种类噪声的叠加使得噪声的复杂度大幅提高,而且同一种类型的噪声之间的差别也很大,比如交通噪声中往往包含着汽车、摩托车、公交车等车辆,他们产生的噪声会有所不同,而一种车辆的引擎声、喇叭声、轮胎与路面摩擦的噪音之间也具有差异,且这些噪声是叠加在一起,同时出现。不同类型噪声的相互叠加往往给人们的生活和健康带来了严重影响,但是如何能够同时去除多种类型的噪声是一个十分困难的问题。
2、目前去除噪声的方式主要是针对特定的噪声根据其时域、频域、时频域特征来去除噪声,通过电子设备和算法来实时监测、分析和反馈噪声信号,现有噪声去除系统,如小波变换、自适应滤波、基于深度学习领域的去噪方法等,这些对单一或者非常相似的噪声有效,但是在实际应用场景下,尤其是复杂多变的噪声环境下,需要同时去除多种类型噪声时,这些方法表现不佳。小波变换是一种常见的噪声处理方式,通过使用一组基函数(小波函数)对信号进行分解和重构。这些基函数具有不同的频率和时间局限性,可以在时间和频率上提供局部信息。小波变换采用多尺度分析的思想,将信号分解成多个不同频率范围的子信号,从而可以更好地捕捉信号的细节和变化。但不同类型的噪声可能需要不同类型的小波基函数,面对多种类型噪声叠加的情况时,选择适当的小波基函数也会变得困难,且去噪效果差,稳定性低。自适应滤波是一种能够根据输入信号的特性和环境条件自动调整滤波器参数的信号处理技术,通过不断调整滤波器的权值或参数,使得滤波器的输出信号与期望信号之间的误差最小化,当多种类型的噪声同时存在时,它们的统计特性可能会随时间或环境的变化而变化,自适应滤波器通常需要基于当前信号和噪声的统计特性来进行参数调整,计算复杂度高,实时性低。随着深度学习技术在各个领域的成功,在去噪领域也有了广泛的应用,其优势在于对复杂信号和噪声之间的非线性关系具有良好的建模能力,并且能够从大量数据中学习到有效的特征表示。一般来说,用于噪声去除的深度学习技术可以分为两类:时频域(t-f)方法和端到端时域方法。基于时频域的去噪方法通常涉及将信号或数据转换到时域和频域表示,并利用频域的特性进行去噪处理,但这种去噪结果在存在相位上的偏差,最终得到声音质量也不稳定。端到端时域方法利用编解码器框架直接建模混合波形的时域方法,u-net通过对时域波形进行连续的卷积编码的下采样操作,然后进行连续的反卷积解码的上采样操作还原波形,期间利用跳跃连接拼接相近尺寸的上下采样信息,这类方法对于单一类型噪声的去除可以取得显著的效果,但是对于多种类型噪声叠加的情况,这类方法去除噪声的效果并不稳定。
3、总体而言,现有的针对同时去除多种类型噪声的方法,存在计算成本高、稳定性差、实时性低等缺点,如何设计一种能够同时去除多种类型噪声混合的方法,并且具有高稳定性、高实时性等特点,则成为一件亟需解决的问题。
4、上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现思路
1、本发明的目的在于,提供一种同时去除多类型噪声的方法及系统,能快速地同时去除多种类型的噪声信号,避免信息的丢失或模糊化。
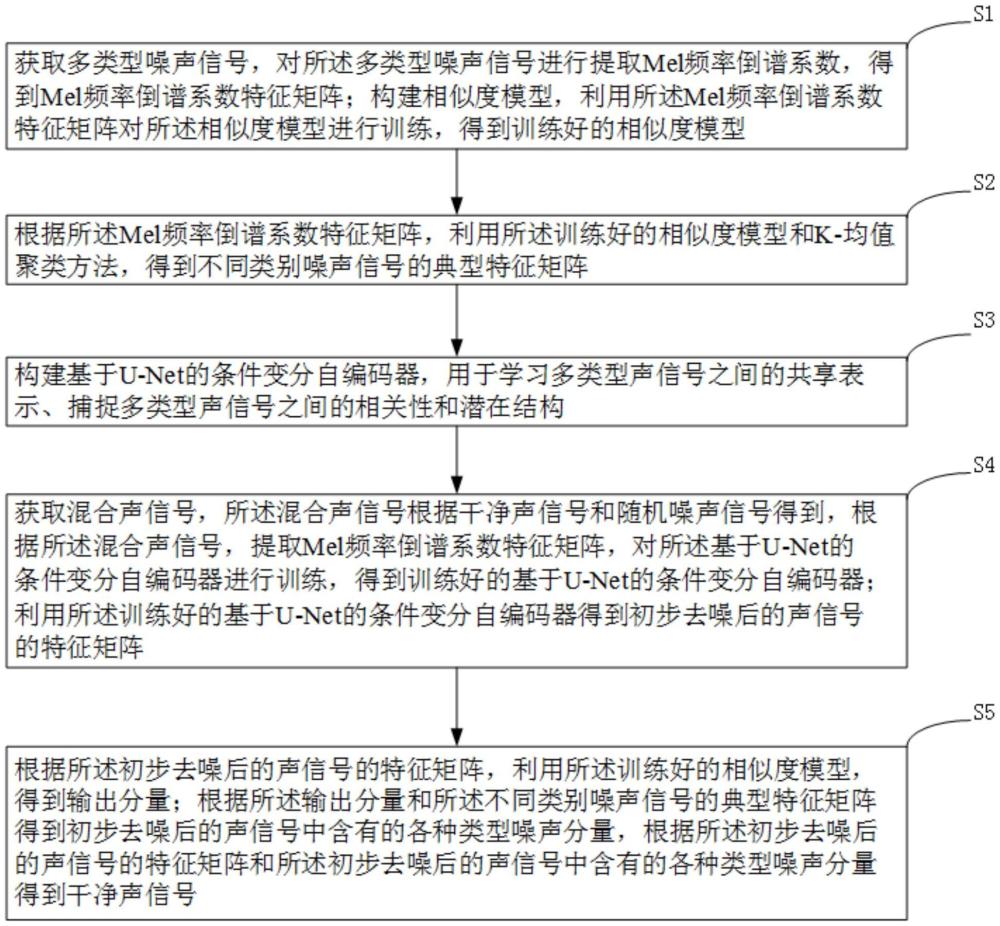
2、本发明提供的同时去除多类型噪声的方法,包括以下步骤:s1:获取多类型噪声信号,对多类型噪声信号进行提取mel频率倒谱系数,得到mel频率倒谱系数特征矩阵;构建相似度模型,利用mel频率倒谱系数特征矩阵对相似度模型进行训练,得到训练好的相似度模型;s2:根据mel频率倒谱系数特征矩阵,利用训练好的相似度模型和k-均值聚类方法,得到不同类别噪声信号的典型特征矩阵;s3:构建基于u-net的条件变分自编码器,用于学习多类型声信号之间的共享表示、捕捉多类型声信号之间的相关性和潜在结构;s4:获取混合声信号,混合声信号根据干净声信号和随机噪声信号得到,根据混合声信号,提取mel频率倒谱系数特征矩阵,对基于u-net的条件变分自编码器进行训练,得到训练好的基于u-net的条件变分自编码器;利用训练好的基于u-net的条件变分自编码器得到初步去噪后的声信号的特征矩阵;s5:根据初步去噪后的声信号的特征矩阵,利用训练好的相似度模型,得到输出分量;根据输出分量和不同类别噪声信号的典型特征矩阵得到初步去噪后的声信号中含有的各种类型噪声分量,根据初步去噪后的声信号的特征矩阵和初步去噪后的声信号中含有的各种类型噪声分量得到干净声信号。
3、进一步地,上述的同时去除多类型噪声的方法的步骤s1包括:s11:构建相似度模型,相似度模型包含至少5层卷积神经网络,其中每一层卷积神经网络经过一个卷积操作之后通过批标准化和relu激活函数,再加入最大池化层,最后进行dropout操作;卷积神经网络包括通道注意力机制模块,通道注意力机制模块包括自适应平均池化层、压缩卷积层、relu激活函数、还原卷积层、sigmoid激活函数;自适应平均池化层为自适应全局池化层,用于每帧特征求平均;压缩卷积层、relu激活函数、还原卷积层和sigmoid激活函数,用于每帧求注意力权重并与原始每帧特征相乘、输出帧间注意力加权后的特征矩阵;s12:获取多类型噪声信号,对多类型噪声信号进行提取mel频率倒谱系数,得到mel频率倒谱系数特征矩阵;根据mel频率倒谱系数特征矩阵,得到训练数据集,将训练数据集按预设比例进行划分,得到训练集和测试集;s13:利用训练集对相似度模型进行训练,当训练次数达到预设数值后,利用adam算法对训练后的相似度模型进行优化,得到优化的相似度模型;利用测试集对优化的相似度模型进行预测,得到预测正确率;当预测正确率不大于预设正确率时,继续对相似度模型进行训练和优化;当预测正确率大于预设正确率时,得到训练好的相似度模型。
4、进一步地,上述的同时去除多类型噪声的方法的步骤s3包括:s31:获取u-net网络模型;在u-net网络模型的编码器和解码器之间加入双向长短时记忆网络,在u-net网络模型的编码器之后连接两个双向长短时记忆网络层、一个全连接层和leakyrelu激活函数,双向长短时记忆网络层包括两个长短时记忆网络层,构建基于u-net的条件变分自编码器的隐藏层,得到基于u-net的条件变分自编码器;隐藏层,用于将输入数据通过编码器和双向长短时记忆网络得到的输出向量沿着第一个维度一分为二,分别作为均值向量和对数方差向量,然后计算潜在变量,如公式:
5、
6、其中,z为潜在变量,mu为均值向量,epsilon为从标准正态分布中采样得到的随机噪声,logvar为对数方差向量;s32:构造损失函数,损失函数用于训练基于u-net的条件变分自编码器,如公式:
7、dkl=0.5*(mu2+elogvar-logvar-1)
8、
9、其中,dkl为kl散度损失,mu为均值向量,e为自然底数,logvar为对数方差向量,nll为负对数似然损失,x为输入数据;kl散度损失和负对数似然损失相加得到总损失。
10、进一步地,上述的同时去除多类型噪声的方法的步骤s4包括:s41:获取干净语音信号和随机噪声信号,根据干净语音信号和随机噪声信号得到混合声信号;根据混合声信号,得到混合多类型声信号的mel频率倒谱系数特征矩阵,根据混合多类型声信号的mel频率倒谱系数特征矩阵,得到混合训练集和混合测试集;s42:根据干净语音信号,得到监督信息;利用混合训练集、混合测试集和监督信息对基于u-net的条件变分自编码器进行训练和测试,得到训练好的基于u-net的条件变分自编码器;s43:根据混合多类型声信号的mel频率倒谱系数特征矩阵,利用训练好的基于u-net的条件变分自编码器,得到初步去噪后的声信号的特征矩阵。
11、进一步地,上述的同时去除多类型噪声的方法的步骤s5包括:s51:将初步去噪后的声信号的特征矩阵输入到训练好的相似度模型,得到输出分量;s52:根据输出分量和不同类别噪声信号的典型特征矩阵,得到余弦相似度、欧氏距离、最大欧氏距离和最小欧氏距离;根据干净语音信号和不同类别噪声信号的典型特征矩阵,得到第二余弦相似度、第二欧氏距离、第二最大欧氏距离和第二最小欧氏距离;s53:根据余弦相似度、欧氏距离、最大欧氏距离、最小欧氏距离、第二余弦相似度、第二欧氏距离、第二最大欧氏距离和第二最小欧氏距离,得到每一类噪声相似度,根据输出分量、混合声信号和不同类别噪声信号的典型特征矩阵,得到去噪后的声信号中的噪声分量,根据初步去噪后的声信号和去噪后的声信号中的噪声分量,得到干净声信号,如公式:
12、
13、其中,αi为每一类噪声相似度,cos(θi)为余弦相似度,di为和欧氏距离,dmax为每一类噪声信号的最大欧氏距离,dmin为每一类噪声信号的最小欧氏距离,cos(θi)为第二余弦相似度,di为第二欧氏距离,dmax为每一类噪声信号的第二最大欧氏距离,dmin为每一类噪声信号的第二最小欧氏距离。
14、本发明还提供一种系统,包括以下模块:噪声及相似度模块,配置为:获取多类型噪声信号,对多类型噪声信号进行提取mel频率倒谱系数,得到mel频率倒谱系数特征矩阵;构建相似度模型,利用mel频率倒谱系数特征矩阵对相似度模型进行训练,得到训练好的相似度模型;噪声特征模块,配置为:根据mel频率倒谱系数特征矩阵,利用训练好的相似度模型和k-均值聚类方法,得到不同类别噪声信号的典型特征矩阵;基于u-net的条件变分自编码器构建模块,配置为:构建基于u-net的条件变分自编码器,用于学习多类型声信号之间的共享表示、捕捉多类型声信号之间的相关性和潜在结构;混合声模块,配置为:获取混合声信号,混合声信号根据干净声信号和随机噪声信号得到,根据混合声信号,提取mel频率倒谱系数特征矩阵,对基于u-net的条件变分自编码器进行训练,得到训练好的基于u-net的条件变分自编码器;利用训练好的基于u-net的条件变分自编码器得到初步去噪后的声信号的特征矩阵;去噪模块,配置为:根据初步去噪后的声信号的特征矩阵,利用训练好的相似度模型,得到输出分量;根据输出分量和不同类别噪声信号的典型特征矩阵得到初步去噪后的声信号中含有的各种类型噪声分量,根据初步去噪后的声信号的特征矩阵和初步去噪后的声信号中含有的各种类型噪声分量得到干净声信号。
15、进一步地,上述的系统的噪声及相似度模块,具体配置为:构建相似度模型,相似度模型包含至少5层卷积神经网络,其中每一层卷积神经网络经过一个卷积操作之后通过批标准化和relu激活函数,再加入最大池化层,最后进行dropout操作;卷积神经网络包括通道注意力机制模块,通道注意力机制模块包括自适应平均池化层、压缩卷积层、relu激活函数、还原卷积层、sigmoid激活函数;自适应平均池化层为自适应全局池化层,用于每帧特征求平均;压缩卷积层、relu激活函数、还原卷积层和sigmoid激活函数,用于每帧求注意力权重并与原始每帧特征相乘、输出帧间注意力加权后的特征矩阵;获取多类型噪声信号,对多类型噪声信号进行提取mel频率倒谱系数,得到mel频率倒谱系数特征矩阵;根据mel频率倒谱系数特征矩阵,得到训练数据集,将训练数据集按预设比例进行划分,得到训练集和测试集;利用训练集对相似度模型进行训练,当训练次数达到预设数值后,利用adam算法对训练后的相似度模型进行优化,得到优化的相似度模型;利用测试集对优化的相似度模型进行预测,得到预测正确率;当预测正确率不大于预设正确率时,继续对相似度模型进行训练和优化;当预测正确率大于预设正确率时,得到训练好的相似度模型。
16、进一步地,上述的系统的基于u-net的条件变分自编码器构建模块,具体配置为:获取u-net网络模型;在u-net网络模型的编码器和解码器之间加入双向长短时记忆网络,在u-net网络模型的编码器之后连接两个双向长短时记忆网络层、一个全连接层和leakyrelu激活函数,双向长短时记忆网络层包括两个长短时记忆网络层,构建基于u-net的条件变分自编码器的隐藏层,得到基于u-net的条件变分自编码器;隐藏层,用于将输入数据通过编码器和双向长短时记忆网络得到的输出向量沿着第一个维度一分为二,分别作为均值向量和对数方差向量,然后计算潜在变量,如公式:
17、
18、其中,z为潜在变量,mu为均值向量,epsilon为从标准正态分布中采样得到的随机噪声,logvar为对数方差向量;构造损失函数,损失函数用于训练基于u-net的条件变分自编码器,如公式:
19、dkl=0.5*(mu2+elogvar-logvar-1)
20、
21、其中,dkl为kl散度损失,mu为均值向量,e为自然底数,logvar为对数方差向量,nll为负对数似然损失,x为输入数据;kl散度损失和负对数似然损失相加得到总损失。
22、进一步地,上述的系统的混合声模块,具体配置为:获取干净语音信号和随机噪声信号,根据干净语音信号和随机噪声信号得到混合声信号;根据混合声信号,得到混合多类型声信号的mel频率倒谱系数特征矩阵,根据混合多类型声信号的mel频率倒谱系数特征矩阵,得到混合训练集和混合测试集;根据干净语音信号,得到监督信息;利用混合训练集、混合测试集和监督信息对基于u-net的条件变分自编码器进行训练和测试,得到训练好的基于u-net的条件变分自编码器;根据混合多类型声信号的mel频率倒谱系数特征矩阵,利用训练好的基于u-net的条件变分自编码器,得到初步去噪后的声信号的特征矩阵。
23、进一步地,上述的系统的去噪模块,具体配置为:将初步去噪后的声信号的特征矩阵输入到训练好的相似度模型,得到输出分量;根据输出分量和不同类别噪声信号的典型特征矩阵,得到余弦相似度、欧氏距离、最大欧氏距离和最小欧氏距离;根据干净语音信号和不同类别噪声信号的典型特征矩阵,得到第二余弦相似度、第二欧氏距离、第二最大欧氏距离和第二最小欧氏距离;根据余弦相似度、欧氏距离、最大欧氏距离、最小欧氏距离、第二余弦相似度、第二欧氏距离、第二最大欧氏距离和第二最小欧氏距离,得到每一类噪声相似度,根据输出分量、混合声信号和不同类别噪声信号的典型特征矩阵,得到去噪后的声信号中的噪声分量,根据初步去噪后的声信号和去噪后的声信号中的噪声分量,得到干净声信号,如公式:
24、
25、其中,αi为每一类噪声相似度,cos(θi)为余弦相似度,di为和欧氏距离,dmax为每一类噪声信号的最大欧氏距离,dmin为每一类噪声信号的最小欧氏距离,cos(θi)为第二余弦相似度,di为第二欧氏距离,dmax为每一类噪声信号的第二最大欧氏距离,dmin为每一类噪声信号的第二最小欧氏距离。
26、实施本发明提供的同时去除多类型噪声的方法及系统,具有以下有益效果:
27、1、通过基于u-net的条件变分自编码器,可以从有多种类型噪声干扰的声信号中分离处干净信号,避免信息的丢失或模糊化,并且去除多种类型噪声时,不需要对系统重新进行调整和校准,具有快速的处理速度和实时的处理能力;
28、2、通过计算混合音频特征矩阵与噪声信号特征矩阵相似度,并减去相应的噪声信号分量,可以同时去除多种类型的噪声信号,并且去除多类型噪声时,只需要采集到多类型噪声的典型特征矩阵,适用性广泛。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286279.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。