用于对语码转换和单语自动语音识别进行联合建模的条件因式分解的制作方法
- 国知局
- 2024-08-30 15:09:05
本公开的实施例涉及自动语音识别领域。更具体地,本公开的实施例涉及在双语语音识别和语码转换语音识别的背景下的自动语音识别领域。
背景技术:
1、自动语音识别(automatic speech recognition,asr)系统旨在识别口语单词。虽然大量的asr系统针对的是单语语音,但是由于双语语音是最常见的交流场景之一,因此,具有同时支持双语的asr系统受到了越来越多的关注。为双语语音提供双语支持的asr系统很少考虑序列内语码转换。由于双语使用者经常在他们所说的不同语言之间无缝地进行语码转换,因此需要识别包括句内语码转换的语音的asr系统。
2、相关工作中已经调整了大规模的多语言模型来更灵活地识别语言切换点,但这些系统的性能取决于所选择的语言的跨语言动态。对所选择的语言的跨语言动态的理解通常是一项困难且资源密集型的工作。相关工作中也试图将ars系统直接优化用于特定双语对的句内语码转换()。这些系统通常与特定的双语对相关联,而不会推广到其他语言对。在相关技术中应用的方法是:通过显式地定义跨语言电话合并规则或通过隐式地学习潜在语言身份表示来改善两种不相关语言之间的语言差异,或者,通过将单语数据并入声学和语言建模的数据有效方法以及通过生成合成语码转换数据的数据增强技术来改善成对语码转换语音数据的稀缺性。因此,相关技术中的asr系统要么没有覆盖双语场景,尤其是句内语码转换场景,要么只关注于特定语言集之间的双语场景,变得难以普及并且不能在单语场景中充分执行。
3、因此,需要asr系统,其在单语场景和双语场景中,特别是句内语码转换方面,都有良好的表现,同时资源密集度较低。
技术实现思路
1、本公开解决了一个或多个技术问题。为了广泛地覆盖双语语音,自动语音识别(asr)系统不仅需要识别单语话语(来自一种语言或多种语言),还需要识别两种语言都存在的句内语码转换(code-switched,cs)话语。本公开的实施例可以涉及可以覆盖单语和句内cs场景两者的会话双语asr系统。
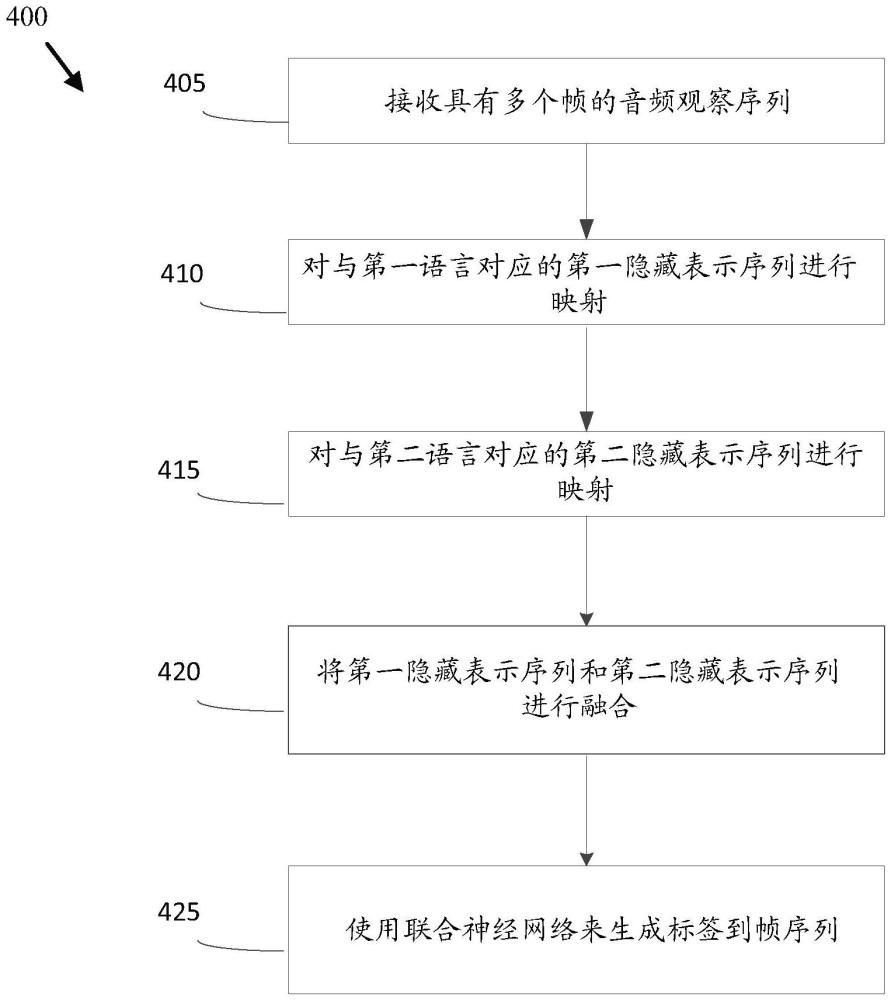
2、根据本公开的实施例,可以提供一种使用条件因式分解对双语语码转换和单语语音进行自动语音识别的方法。所述方法可以由一个或多个处理器执行,并且所述方法可以包括:接收包括多个帧的音频观察序列,所述音频观察序列包括第一语言的音频或第二语言的音频;将所述音频观察序列映射为第一隐藏表示序列,该映射由与所述第一语言对应的第一编码器生成;将所述音频观察序列映射为第二隐藏表示序列,该映射由与所述第二语言对应的第二编码器生成;以及使用基于联合神经网络的模型,基于所述第一隐藏表示序列和所述第二隐藏表示序列来生成标签到帧序列。
3、根据本公开的实施例,可以提供一种使用条件因式分解对双语语码转换和单语语音进行自动语音识别的装置。所述装置可以包括:至少一个存储器,其被配置为存储程序代码;以及至少一个处理器,其被配置为读取所述程序代码并根据所述程序代码的指令进行操作。所述程序代码可以包括:第一接收代码,其被配置为使得所述至少一个处理器接收包括多个帧的音频观察序列,所述音频观察序列包括第一语言的音频或第二语言的音频;第一映射代码,其被配置为使得所述至少一个处理器将所述音频观察序列映射为第一隐藏表示序列,该映射由与所述第一语言对应的第一编码器生成;第二映射代码,其被配置为使得所述至少一个处理器将所述音频观察序列映射为第二隐藏表示序列,该映射由与所述第二语言对应的第二编码器生成;以及第一生成代码,其被配置为使得所述至少一个处理器使用基于联合神经网络的模型,基于所述第一隐藏表示序列和所述第二隐藏表示序列来生成标签到帧序列。
4、根据本公开的实施例,可以提供一种存储有一个或多个指令的非暂时性计算机可读介质。所述一个或多个指令在由使用条件因式分解对双语语码转换和单语语音进行自动语音识别的设备的一个或多个处理器执行时,可以使得所述一个或多个处理器执行以下步骤:接收包括多个帧的音频观察序列,所述音频观察序列包括第一语言的音频或第二语言的音频;将所述音频观察序列映射为第一隐藏表示序列,该映射由与所述第一语言对应的第一编码器生成;将所述音频观察序列映射为第二隐藏表示序列,该映射由与所述第二语言对应的第二编码器生成;以及使用基于联合神经网络的模型,基于所述第一隐藏表示序列和所述第二隐藏表示序列来生成标签到帧序列。
技术特征:1.一种使用条件因式分解对双语语码转换和单语语音进行自动语音识别的方法,所述方法由一个或多个处理器执行,所述方法包括:
2.根据权利要求1所述的方法,其中,所述生成标签到帧序列包括:
3.根据权利要求1所述的方法,其中,在所述标签到帧序列中的任何位置处的标签与所述第一语言相关联或与所述第二语言相关联,并且其中,所述标签不与所述第一语言和所述第二语言两者均相关联。
4.根据权利要求1所述的方法,其中,所述第一编码器是使用第一连接主义时序分类框架训练的第一预训练神经网络模型,并且其中,所述第二编码器是使用第二连接主义时序分类框架训练的第二预训练神经网络模型。
5.根据权利要求4所述的方法,其中,所述第一编码器被配置为:基于确定所述音频观察序列的多个帧中的相应帧与第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第一标签,并且其中,所述第一编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
6.根据权利要求4所述的方法,其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的相应帧与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第二标签,并且其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
7.根据权利要求1所述的方法,其中,使用损失函数来训练所述基于联合神经网络的模型,所述损失函数基于与所述基于联合神经网络的模型相关联的联合损失、与所述第一编码器相关联的第一损失以及与所述第二编码器相关联的第二损失。
8.一种使用条件因式分解对双语语码转换和单语语音进行自动语音识别的装置,所述装置包括:
9.根据权利要求8所述的装置,其中,所述第一生成代码包括:
10.根据权利要求8所述的装置,其中,在所述标签到帧序列中的任何位置处的标签与所述第一语言相关联或与所述第二语言相关联,并且其中,所述标签不与所述第一语言和所述第二语言两者均相关联。
11.根据权利要求8所述的装置,其中,所述第一编码器是使用第一连接主义时序分类框架训练的第一预训练神经网络模型,并且其中,所述第二编码器是使用第二连接主义时序分类框架训练的第二预训练神经网络模型。
12.根据权利要求11所述的装置,其中,所述第一编码器被配置为:基于确定所述音频观察序列的多个帧中的相应帧与第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第一标签,并且其中,所述第一编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
13.根据权利要求11所述的装置,其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的相应帧与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第二标签,并且其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
14.根据权利要求8所述的装置,其中,使用损失函数来训练所述基于联合神经网络的模型,所述损失函数基于与所述基于联合神经网络的模型相关联的联合损失、与所述第一编码器相关联的第一损失以及与所述第二编码器相关联的第二损失。
15.一种存储有指令的非暂时性计算机可读介质,所述指令包括:一个或多个指令,所述一个或多个指令在由使用条件因式分解对双语语码转换和单语语音进行自动语音识别的设备的一个或多个处理器执行时,使得所述一个或多个处理器执行以下操作:
16.根据权利要求15所述的非暂时性计算机可读介质,其中,所述生成标签到帧序列包括:
17.根据权利要求15所述的非暂时性计算机可读介质,其中,在所述标签到帧序列中的任何位置处的标签与所述第一语言相关联或与所述第二语言相关联,并且其中,所述标签不与所述第一语言和所述第二语言两者均相关联。
18.根据权利要求15所述的非暂时性计算机可读介质,其中,所述第一编码器是使用第一连接主义时序分类框架训练的第一预训练神经网络模型,并且其中,所述第二编码器是使用第二连接主义时序分类框架训练的第二预训练神经网络模型。
19.根据权利要求18所述的非暂时性计算机可读介质,其中,所述第一编码器被配置为:基于确定所述音频观察序列的多个帧中的相应帧与第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第一标签,并且其中,所述第一编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第一语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
20.根据权利要求18所述的非暂时性计算机可读介质,其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的相应帧与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的相应第二标签,并且其中,所述第二编码器被配置为:基于确定所述音频观察序列的所述多个帧中的所述相应帧不与所述第二语言相关联,生成与所述音频观察序列的所述多个帧中的所述相应帧相关联的空白标签。
技术总结一种使用条件因式分解对双语语码转换和单语语音进行自动语音识别的方法、装置和非暂时性计算机可读介质,可以包括:接收包括多个帧的音频观察序列,所述音频观察序列包括第一语言的音频或第二语言的音频。所述方法还可以包括:将所述音频观察序列映射为第一隐藏表示序列,该映射由与所述第一语言对应的第一编码器生成;以及将所述音频观察序列映射为第二隐藏表示序列,该映射由与所述第二语言对应的第二编码器生成。所述方法还可以包括:使用基于联合神经网络的模型,基于所述第一隐藏表示序列和所述第二隐藏表示序列来生成标签到帧序列。技术研发人员:张春雷,布莱恩·严,俞栋受保护的技术使用者:腾讯美国有限责任公司技术研发日:技术公布日:2024/8/27本文地址:https://www.jishuxx.com/zhuanli/20240830/285663.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表