基于混合专家的多方言语音识别模型、训练方法
- 国知局
- 2024-09-11 14:21:03
本发明涉及基于混合专家的多方言语音识别模型,属于自然语言处理。
背景技术:
1、语音识别技术的应用领域非常广泛,包括语音助手、智能家居、汽车语音交互等多个领域。随着深度学习的进步,自动语音识别系统在识别普通话语音方面取得了显著进展。
2、方言是中国民众日常交流的一种流行方式。然而,由于方言和普通话在发音上的固有差异和显著特点,语音识别系统在方言语音中的性能仍然有限,对语音识别技术领域提出了重大挑战。因此,提高汉语多方言语音识别系统的准确性和适应性具有重要意义。本发明主要针对汉语方言,提出的方法也可以推广到其他方言。
3、近年来,大量的研究集中在解决方言语音识别模型性能不佳的挑战。传统的方式是通过不同的建模方法来提高方言语音识别的效果。近年来,基于多任务的方法被广泛应用于方言语音识别任务中。与传统方法相比,多任务学习方法具有更高的效率。提出为每种方言构建方言分类模型和单独的语音识别模型。利用方言分类模型选择相应的方言语音识别模型。然而,这些研究取决于广泛的方言数据集,并且没有检查各种方言之间的共性对模型性能的潜在影响。
4、为了构建低资源条件下可靠的方言语音识别模型,近年来,基于迁移学习的方法被提出,该方法包括一个基于普通话训练的模型,并使用小规模方言数据进行微调。然而,仅仅依靠迁移学习的方式没有充分考虑方言与普通话之间的异同。
技术实现思路
1、为了解决上述问题本发明提出了低资源条件下基于混合专家的汉语多方言语音识别模型、训练方法,本发明所提出的模型以及训练方法在多方言语音识别中表现出了优异的性能。
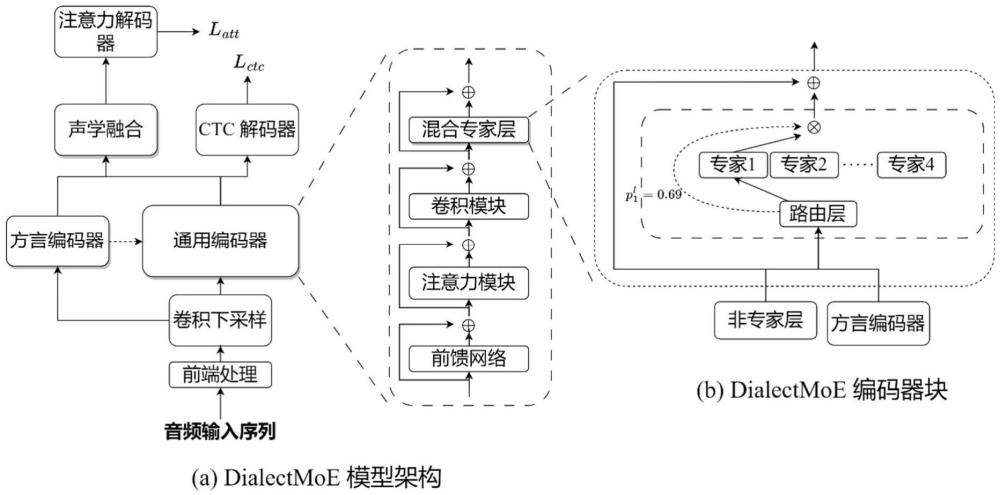
2、本发明的技术方案是:第一方面,本发明提供一种基于混合专家的汉语多方言语音识别模型,所述模型包括通用编码器、方言编码器、声学融合模块、注意力解码器和ctc解码器;
3、所述通用编码器由12层的dialectmoe编码器块组成,负责以方言无关的方式捕获语音信息;
4、所述方言编码器由6层conformer编码器组成,从特征序列中捕获方言信息;
5、所述声学融合模块用于将通用编码器和方言编码器的输出进行声学融合;
6、所述注意力解码器用于根据声学融合模块的输出计算注意力损失并解码出文本;
7、所述ctc解码器用于根据通用编码器的输出计算ctc损失并解码出文本。
8、进一步地,原始音频序列经过前端模块的预处理,提取滤波器组特征;然后,利用卷积下采样对音频特征序列进行时间上的下采样;通过方言编码器从卷积下采样的特征序列中捕获方言信息;再通过通用编码器从卷积下采样的特征序列中以方言无关的方式捕获语音信息;再将通用编码器和方言编码器的输出进行声学融合,通过注意力解码器根据声学融合模块的输出计算注意力损失并解码出文本;通过ctc解码器根据通用编码器的输出计算ctc损失并解码出文本。
9、进一步地,所述通用编码器的dialectmoe编码器块中,输入序列首先通过前馈网络(ffn)层,然后通过注意力和卷积神经网络(cnn)层分别提取全局和局部信息;然后基于动态路由选择混合专家层内合适的专家,专家的输出乘以路由器层分配的权重。
10、进一步地,所述基于动态路由选择混合专家层内合适的专家包括:
11、所述方言编码器捕获的方言信息由路由器层进行加权,路由器层根据动态路由算法以选择合适的专家;动态路由算法利用非专家层的输出序列和方言编码器提供的方言信息来选择合适的专家。
12、进一步地,所述动态路由算法在选择合适的专家时,探究不同方言嵌入,即方言编码器的方言信息对路由算法的影响,具有如下三种策略:
13、独立利用“嵌入(embed)”、将嵌入“连接(concat)”和“累加(add)”到卷积层的输出;具体如下:
14、方言编码器的输出表示为其中t表示序列长度,d表示特征维度;假设有n专家,路由层的输出定义如下:
15、
16、
17、
18、其中wr表示路由器层的权重参数,表示卷积模块的输出;通用路由器层根据输入序列选择专家,再结合了方言编码器的输出来选择最合适的专家;
19、路由器层以路由层输出r为依据,通过动态路由选择概率最大的专家,动态路由概率定义如下:
20、
21、其中是i专家被选中的概率,ri为路由层对应第i个专家的输出,对ri选用e作为底数的指数函数来转换概率,既公式(4)中的exp,防止负数或等于0的输出,为当前路由层对应专家的输出总和;则混合专家层的输出形式化定义如下:
22、
23、其中ei是所选i专家的输出。
24、进一步地,为了将方言信息合并到解码器中,通过合并通用编码器和方言编码器两个独立编码器的输出来合并信息融合;该融合过程通过声学融合模块实现,发生在将结果传输到解码器之前;融合过程定义如下:
25、
26、其中表示两个不同编码器输出的信息融合的结果,表示通用编码器输出的结果,表示方言编码器输出的结果;
27、用于语音识别的综合损失函数包括联合的ctc-注意力损失,以及补充的平衡损失,损失函数的完整公式如下:
28、
29、其中α是平衡损失的权重,λ是语音识别损失的权重,表示平衡性损失,为ctc解码器输出的ctc损失,为注意力解码器输出的注意力损失。
30、第二方面,本发明提供第一方面所述基于混合专家的多方言语音识别模型的训练方法,所述基于混合专家的多方言语音识别模型的训练方法包括如下3个训练步骤:
31、step1、预训练通用编码器:初始化一个conformer模型作为通用编码器,并使用汉语数据集进行预训练;预训练步骤允许模型捕获各种常见的语音特征,从而降低多方言语音识别任务的学习复杂性;
32、step2、训练方言编码器:初始化一个新的conformer模型为方言编码器,并使用方言和普通话数据在方言分类任务上进行训练;用于使方言编码器能够学习多种方言和普通话之间的声学差异,辅助通用编码器完成方言语音识别任务;
33、step3、训练dialectmoe编码器块:将前两步训练的通用编码器和方言编码器初始化为dialectmoe的参数,用使用混合专家层初始化通用编码器中的第二层前馈网络层,仅使用低资源的多方言训练数据来训练最终的多方言语音识别模型。
34、本发明的有益效果是:
35、1、本发明的dialectmoe编码器块结合了混合专家层来解决当模型遇到的复杂多变的语音时产生的解码困难问题;
36、2、在多方言语音识别的背景下,有效解决方言变化的多样性至关重要,本发明提出了一种新的动态路由算法,旨在增强模型对不同方言的适应性和泛化能力;利用非专家层的输出序列和方言编码器提供的方言信息来选择合适的专家;这种动态路由机制在复杂的语音场景中被证明更加有效,尤其是涉及多种方言的场景;
37、3、在aidatatang方言公开数据集上的实验结果表明,所提出的模型在多方言语音识别中表现出了优异的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290329.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。