文本无关的说话者识别的制作方法
- 国知局
- 2024-09-11 14:30:11
背景技术:
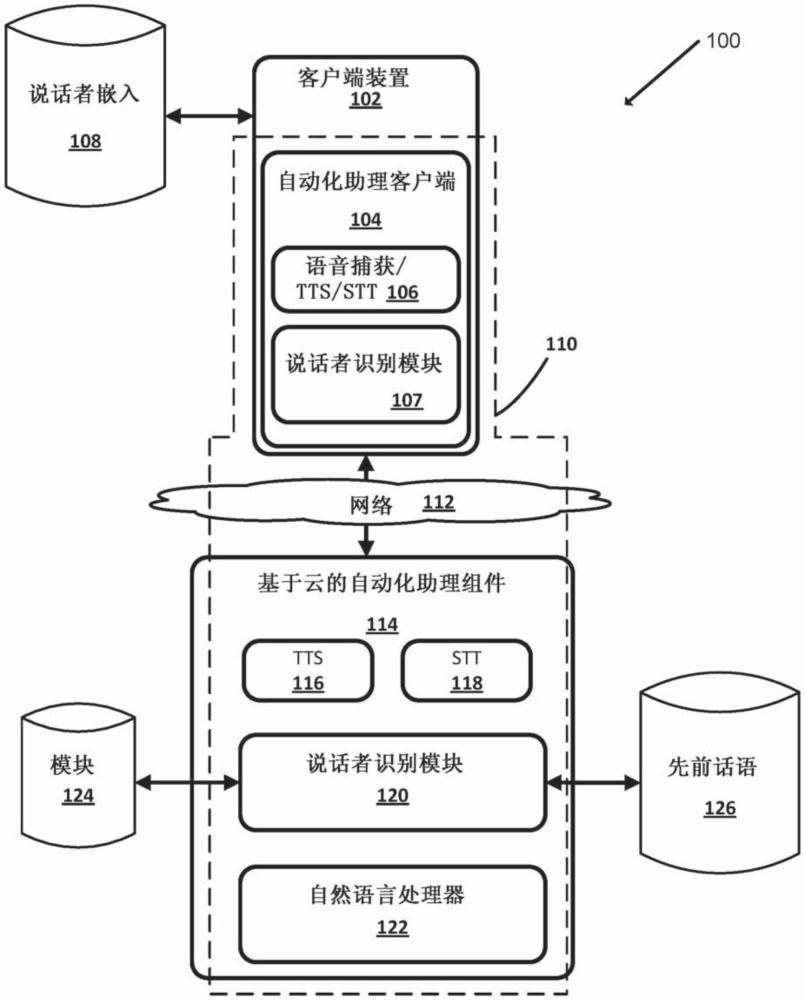
1、自动化助理(也称为“个人助理”、“移动助理”等)可以由用户经由多种客户端装置进行交互,诸如智能电话、平板计算机、可穿戴装置、汽车系统、独立个人助理装置等等。自动化助理接收来自用户的输入,包括口头自然语言输入(即,话语),并且可以通过执行动作、通过控制另一装置和/或提供响应内容(例如,视觉和/或听觉自然语言输出)来进行响应。经由客户端装置交互的自动化助理可以经由客户端装置本身和/或经由与客户端装置网络通信的一个或多个远程计算装置(例如,云中的计算装置)来实现。
2、自动化助理可以将对应于用户的口头话语的音频数据转换成相应的文本(或其他语义表示)。例如,可以基于经由包括自动化助理的客户端装置的一个或多个麦克风检测到用户的口头话语来生成音频数据。自动化助理可以包括语音识别引擎,所述语音识别引擎试图识别在音频数据中捕获的口头话语的各种特性,诸如由口头话语产生的声音(例如,音素)、发音的顺序、语音节奏、语调等。此外,语音识别引擎可以识别出此类特性所表示的文本单词或短语。然后,自动化助理可以进一步处理所述文本(例如,使用自然语言理解引擎和/或对话状态引擎),以确定口头话语的响应内容。语音识别引擎可以由客户端装置和/或远离客户端装置但与客户端装置网络通信的一个或多个自动化助理组件来实现。
技术实现思路
1、本文描述的技术涉及基于捕获口头话语的音频数据的处理的文本无关(ti)的说话者识别。然而,当然应了解,除了提供响应内容之外或代替提供响应内容,可以执行/使得执行其他动作,诸如控制其他装置,所述装置诸如但不限于智能锁、智能警报系统、智能开关和/或智能恒温器。在此类示例中,可以仅响应于验证特定授权用户说出了特定口头话语而使得其他装置受到控制。在用户允许的情况下,可以使用说话者识别来验证用户说出了特定的口头话语。响应于验证用户说出了特定的口头话语,可以响应于所述特定的口头话语来提供内容,其中所述内容既响应于特定的口头话语,又是为用户定制的。说话者识别可以包括使用说话者识别模型来处理捕获口头话语的音频数据以生成输出,并将所述输出与用于用户的说话者嵌入进行比较(例如,与用户的用户配置文件相关联的嵌入)。例如,如果生成的输出和用户的说话者嵌入之间的距离度量满足阈值,则用户可以被验证为说出了特定口头话语的用户。可以基于输出来生成用于用户的说话者嵌入,所述输出是基于对包括来自用户的口头话语的音频数据的一个或多个实例的处理而生成的。例如,说话者嵌入可以基于多个不同嵌入的平均值(或其他组合),每一嵌入是基于对包括来自用户的相应口头话语的相应音频数据实例的处理而生成的。
2、在文本相关(td)的说话者识别中,用户的说话者嵌入是基于仅包括一个或多个特定单词和/或一个或多个特定短语的口头话语而生成的。此外,在使用中,用户必须说出一个或多个特定单词/短语以便使用与说话者嵌入充分匹配的td说话者识别模型来生成输出。作为一个实例,td说话者识别中的一个或多个特定单词/短语可以局限于被配置成调用自动化助理的一个或多个调用短语。自动化助理的调用短语包含一个或多个热词/触发词,例如,“嘿,助理”、“好的,助理”和/或“助理”。
3、相比来说,在ti说话者识别中,使用ti说话者识别模型处理的口头话语并不局限于特定单词和/或特定短语。换句话说,可以使用ti说话者识别模型来处理基于几乎任何口头话语的音频数据以生成输出,所述输出可以有效地与特定用户的ti说话者嵌入进行比较,以确定口头话语是否来自特定用户。此外,在各种实施方式中,在ti说话者识别中利用的用户的说话者嵌入是基于包括不同的单词和/或短语的口头话语来生成的。
4、在各种实施方式中,特定用户的一个或多个说话者嵌入存储在与所述特定用户相关联的客户端装置处(例如,客户端装置与所述特定用户的用户配置文件相关联,并且本地存储的说话者嵌入与用户配置文件相关联)。此外,多个用户可以与同一个客户端装置相关联,且因此若干特定用户的多个说话者嵌入可以存储在客户端装置处(例如,客户端装置与若干特定用户的用户配置文件相关联,其中每一用户配置文件包括相关联的特定用户的至少一个说话者嵌入)。在客户端装置处存储说话者嵌入(与在诸如服务器的远程计算装置处存储说话者嵌入相比)可以有助于保护数据安全性。在各种实施方式中,td说话者识别可以发生在客户端装置处。另一方面,ti说话者识别在计算上可能是昂贵的(例如,处理器和/或存储器资源),和/或依赖于需要大量存储空间的ti说话者识别模型。因此,在许多实施方式中,ti说话者识别可以更好地适用于远程计算装置(例如,一个或多个服务器),所述远程计算装置可以利用它们更鲁棒的资源。另外或可替代地,在许多实施方式中,ti说话者识别可以发生在客户端装置处。例如,当在客户端装置处执行ti说话者识别时,增量式验证结果可以从客户端装置传输到服务器。此外,在各种实施方式中,ti说话者嵌入可以本地存储在客户端装置处,并且与捕获口头话语的音频数据一起传输到远程计算装置,以使得能够使用ti说话者嵌入来验证(通过远程计算装置)话语的说话者。在各种实施方式中,在远程计算装置处与音频数据一起接收并在ti说话者识别中利用的说话者嵌入可以在它们被用于说话者识别过程之后立即从远程计算装置中删除,从而保护数据安全性,并减少了恶意行为者以利用说话者嵌入为目的来访问说话者嵌入从而未经授权而访问内容或控制装置的机会。
5、本文公开的一些实施方式涉及至少选择性地利用说话者识别中的td说话者识别模型和ti说话者识别模型两者。例如,可以使用td说话者识别模型来处理捕获口头话语的音频数据的调用部分,以生成td输出。td输出然后可以与给定用户的td说话者嵌入相比较,以生成给定用户的td用户测量。例如,td用户测量可以基于td输出和td说话者嵌入之间的距离(在嵌入空间中)。此外,可以使用ti说话者识别模型来处理捕获口头话语的音频数据的至少附加部分,以生成ti输出。ti输出然后可以与给定用户的ti说话者嵌入相比较,以生成给定用户的ti用户测量。例如,ti用户测量可以基于ti输出和ti说话者嵌入之间的距离(在嵌入空间中)。
6、td用户测量和ti用户测量可以至少选择性地组合使用,以确定给定用户是否是口头话语的说话者。例如,td用户测量和ti用户测量可以分别与各自的阈值进行比较,可以被平均(或以其他方式组合)并与阈值进行比较,和/或以其他方式在确定给定用户是否是口头话语的说话者时被组合考虑。利用td和ti用户测量两者可以增加说话者识别的鲁棒性和/或准确性。这可以减轻可能损害(例如,数据)安全性的误判,和/或减轻可能导致相应用户需要再次提供口头话语的漏判——防止计算和网络资源在再次处理和传输口头话语时被浪费。
7、在一些实施方式中,ti说话者识别模型仅在td用户测量未能满足阈值时用于说话者识别。例如,如果给定用户的td用户测量以高置信度指示给定用户是口头输入的说话者,则可以绕过ti说话者识别。这可以通过在只有td说话者识别以高置信度识别说话者时阻止执行ti说话者识别来节省计算资源。在一些实施方式中,当ti用户测量和td用户测量两者用于说话者识别中时,可以基于针对其正在识别说话者的请求的一个或多个特征来动态确定两个测量的相应权重。此类特征可以包括例如,请求的口头话语的长度(例如,整体长度、或至少请求的任何非调用部分的长度)、和/或td用户测量的量值。例如,相比于“好的,助理,出了什么事”的请求,对于“好的,助理,我接下来的五个日历条目是什么”的请求,ti用户测量的权重可以更重。此类更重的加权可以至少部分地基于“我接下来的五个日历条目是什么”比“出了什么事”更长(持续时间和/或术语/字符方面)——因为使用ti说话者识别模型处理更长的音频数据可以导致生成更准确的ti用户测量。作为另一实例,当td用户测量指示高置信度时,与td用户测量不指示高置信度时相比,ti用户测量的权重低很多。ti和td用户测量的此类动态加权可以通过以更可能导致准确说话者识别的方式移位加权来减轻误判和/或漏判。
8、上文描述的示例是针对与单个用户相关联的嵌入和测量来描述的。然而,如本文所描述,在各种情况下,客户端装置可以与多个用户相关联,每一用户具有单独的说话者嵌入(例如,每一用户具有相应的ti说话者嵌入和相应的td说话者嵌入)。在这些情况下,针对多个用户中的每一个的相应td用户测量和相应ti用户测量可以用于识别多个用户中的哪一个说出了口头话语。
9、本文公开的一些实施方式另外地或可替代地涉及启动对与请求相关联的多个用户中的每一个的响应内容的确定,其中所述启动发生在完成确定(例如,使用ti说话者识别模型)多个用户中的哪一个说出了在请求的音频数据中捕获的口头话语之前。然后,响应于确定特定用户说出了在请求的音频数据中捕获的口头话语,可以使特定用户的响应内容响应于请求而被呈现。启动确定多个用户中的每一个的响应内容可以使得响应内容能够在已经确定多个用户中的哪一个说出了口头话语之前开始生成。因此,与在启动生成特定用户的响应内容之前等待识别特定用户相比,可以以减少的时延生成和/或呈现特定用户的响应内容(或者可以执行动作)。可选地,如果在完成其他用户的响应内容的生成之前识别出特定用户,则可以停止生成其他用户的响应内容,以防止在继续生成其他用户的此类响应内容时使用任何其他的计算和/或网络资源。
10、此外,在各种实施方式中,启动确定与请求相关联的多个用户中的每一个的响应内容仅响应于那些满足一个或多个阈值的多个用户的最初确定的td测量而发生。例如,如本文所描述,在各种情况下,td测量可以在ti测量之前生成,并且/或者可以包括(或至少指示)在接收到的请求中。如果与请求相关联的三个用户中的两个用户的td测量满足阈值,则可以抢先启动生成这两个用户的响应内容(而对于td测量不满足阈值的另一用户,则不抢先启动)。如果只有一个用户的td测量满足阈值,则可选地可以仅针对所述一个用户抢先启动生成响应内容。如果与请求相关联的所有三个用户的td测量都满足阈值,则可以抢先启动生成所有三个用户的响应内容。
11、一些实施方式另外地或可替代地涉及使用更新的ti说话者识别模型自动地生成给定用户的更新版本的ti说话者嵌入。在这些实施方式中的一些中,从客户端装置接收请求,其中所述请求包括捕获给定用户的口头输入的音频数据,并且包括给定用户的说话者嵌入的版本。在这些实施方式的一些版本中,响应于确定所述版本的说话者嵌入是使用过时的ti说话者识别模型生成的,生成给定用户的更新版本的说话者嵌入。例如,基于包括在请求中的所述版本的说话者嵌入的版本标识符,可以确定已经使用过时的ti说话者识别模型生成了所述版本的说话者嵌入。过时版本的说话者嵌入仍然可以用于将给定用户识别为已经说出了包括在请求的音频数据中的口头输入,以及生成响应于口头输入并且为给定用户定制的响应内容。通过利用过时版本的ti说话者识别模型来处理至少一部分音频数据以生成输出,并将生成的输出与过时版本的说话者嵌入进行比较,可以在识别给定用户时利用过时版本的说话者嵌入。可以响应于请求而将响应内容传输到客户端装置,从而使得在客户端装置处呈现响应内容(或其转换)。利用过时版本的ti说话者识别模型使得能够对包括过时说话者嵌入的请求执行说话者识别,无需等待生成更新的说话者嵌入。尽管部署了更新的说话者嵌入模型,但这可以继续支持过时的说话者嵌入。此外,这可以减轻在生成对包括过时的说话者嵌入的请求的响应中的时延,因为过时的说话者嵌入可以被用来识别说话者,并且可选地传输为所识别的说话者定制的内容——而不是需要等待生成更新的说话者嵌入来验证用户(其中更新的说话者嵌入的生成可能引入不期望的时延)。另外,所述技术确保在大部分时间使用给定用户的最新版本的ti说话者嵌入,同时分散与为所有用户生成和提供更新的说话者嵌入相关联的计算负荷。此外,由于所述版本的ti说话者嵌入仅在接收到来自给定用户的包括内容的请求时生成,所以更新版本的ti说话者嵌入不会自动生成并提供给不再使用或很少使用助理系统的用户。
12、更新版本的说话者嵌入可以基于音频数据的过去实例而生成,这些过去实例被存储(在用户允许的情况下)并且每一实例捕获被确定为由用户说出的过去口头话语。在那些不同实施方式中的一些中,基于寻求增加嵌入的鲁棒性(从而确保基于说话者嵌入的鲁棒的ti说话者识别)的一个或多个准则来选择被选择用于生成说话者嵌入的音频数据的过去实例。例如,可以基于包括集体多样化的话语(例如,语音多样化、单词多样化和/或其他多样化特征)来选择音频数据实例的集合,可以基于包括至少具有阈值长度的话语来选择音频数据的一个或多个实例,等等。此外,利用满足一个或多个准则的音频数据的过去实例可以导致更鲁棒的嵌入。此外,利用过去的实例可以减轻用户再次提供多个登记话语的需要,这可能是耗时的并且可能不必要地消耗资源,诸如处理登记话语时的计算资源和/或传输对应于登记话语的音频数据时的网络资源。一旦生成,可以将更新的说话者嵌入传输到客户端装置,以使得所述客户端装置本地存储更新的说话者嵌入以用于与未来请求一起传输。当响应于被确定为包括过时的说话者嵌入的请求而生成更新的说话者嵌入时,更新的说话者嵌入可以可选地在传输响应于所述请求并且利用过时的ti说话者嵌入生成的响应内容之后被传输。如上文提及,利用过时的ti说话者识别模型可以能够快速地提供生成响应内容(或动作)并减少时延,同时更新的ti说话者嵌入的生成仍在进行。
13、提供以上描述作为本文公开的各种实施方式的概述。本文将更详细地描述那些不同的实施方式以及附加的实施方式。
14、在一些实施方式中,提供一种由一个或多个处理器实现的方法,所述方法包括:从客户端装置并且经由网络接收自动化助理请求,所述请求包括:用于所述客户端装置的特定用户的文本无关(ti)说话者嵌入,以及捕获所述特定用户的口头输入的音频数据,其中所述音频数据经由所述客户端装置的一个或多个麦克风捕获。所述方法进一步包括确定所述ti说话者嵌入是使用过时版本的ti说话者识别模型生成的。所述方法进一步包括响应于确定所述说话者嵌入是使用所述过时版本的所述ti说话者识别模型生成的:使用所述过时版本的所述ti说话者识别模型处理所述音频数据的至少一部分以生成ti输出。所述方法进一步包括通过比较所述ti输出与所述特定用户的所述说话者嵌入,确定所述特定用户是否说出了所述口头输入。所述方法进一步包括响应于确定所述特定用户说出了所述口头输入:执行基于所述音频数据的一个或多个动作;使用更新版本的所述ti说话者识别模型处理捕获所述特定用户的先前口头输入的先前音频数据,以生成更新的说话者嵌入;以及将所述特定用户的所述更新的说话者嵌入传输到所述客户端装置,以使得所述客户端装置本地存储所述更新的说话者嵌入以用于与未来自动化助理请求一起传输。
15、本文所公开的技术的这些和其他实施方式可以包括以下特征中的一个或多个。
16、在一些实施方式中,实现所述方法的一个或多个处理器在远离所述客户端装置的一个或多个计算装置处,并且进一步包括:响应于将用于所述特定用户的所述更新的说话者嵌入传输到所述客户端装置:从所述一个或多个计算装置删除所述更新的说话者嵌入的所有实例。
17、在一些实施方式中,使用过时版本的所述ti说话者识别模型处理所述音频数据的至少一部分以生成ti输出包括:使用所述过时版本的所述ti说话者识别模型处理所述音频数据的附加部分(该附加部分是除了所述音频数据的调用短语部分之外的部分),以生成所述ti输出。
18、在一些实施方式中,使用过时版本的所述ti说话者识别模型处理所述音频数据的至少一部分以生成ti输出包括:使用所述过时版本的所述ti说话者识别模型处理所述音频数据的调用短语部分和所述音频数据的附加部分,以生成所述ti输出。
19、在一些实施方式中,使用更新版本的所述ti说话者识别模型处理捕获所述特定用户的先前口头输入的所述先前音频数据以生成更新的说话者嵌入包括:使用所述更新版本的所述ti说话者识别模型处理所述先前音频数据的多个实例以生成所述更新的说话者嵌入,其中所述先前音频数据的所述实例中的每一个捕获所述特定用户的先前口头输入。
20、在一些实施方式中,所述方法进一步包括基于所述先前音频数据的所述多个实例满足一个或多个准则而选择所述先前音频数据的所述多个实例。
21、在一些实施方式中,所述一个或多个准则包括以下各项中的一个或多个:用于所述先前音频数据的所述多个实例中的每一者的长度准则;以及用于所述先前音频数据的所述多个实例的多样性准则。在这些实施方式的一些版本中,所述方法进一步包括通过下述方式来用捕获所述特定用户的所述口头输入的所述音频数据替换所述先前音频数据的所述实例中的先前音频数据实例:确定所述多个先前音频数据中先前音频数据的每一实例的长度。所述方法进一步包括确定捕获所述特定用户的所述口头输入的所述音频数据的长度。所述方法进一步包括比较所述音频数据的所述长度与先前音频数据的每一实例的所述长度。所述方法进一步包括响应于基于所述比较确定所述音频数据比先前音频数据的一个或多个实例长,用最短长度的所述音频数据替换先前音频数据的所述实例。
22、在一些实施方式中,确定所述ti说话者嵌入是使用过时版本的所述ti说话者识别模型生成的至少部分基于所述ti说话者嵌入的版本标识符,所述版本标识符包括在所述自动化助理请求中。
23、在一些实施方式中,执行基于所述音频数据的一个或多个动作包括基于所述音频数据控制一个或多个外围装置。
24、在一些实施方式中,执行基于所述音频数据的一个或多个动作包括生成为所述特定用户定制并且基于所述音频数据的响应内容,以及使得所述客户端装置基于所述响应内容呈现输出。在这些实施方式的一些版本中,所述方法进一步包括在使得所述客户端装置基于所述响应内容呈现输出之后,完成生成所述更新的说话者嵌入。
25、在一些实施方式中,自动化助理请求进一步包括文本相关(td)用户测量,所述td用户测量是使用本地存储在所述客户端装置处的td说话者识别模型以及使用本地存储在所述客户端装置处的td说话者嵌入而在所述客户端装置本地生成的,所述td说话者嵌入用于所述特定用户,并且其中通过比较所述ti输出与所述特定用户的所述说话者嵌入来确定所述特定用户是否说出了所述口头输入进一步包括:通过比较所述ti输出与所述说话者嵌入来确定ti用户测量;以及使用所述td用户测量和所述ti用户测量两者来确定所述特定用户是否说出了所述口头输入。在这些实施方式中的一些版本中,所述方法进一步包括通过下述方式使用所述td用户测量和所述ti用户测量两者确定所述特定用户是否说出了所述口头输入:通过组合所述td用户测量和所述ti用户测量来确定特定用户概率测量,所述特定用户概率测量指示所述特定用户说出了所述口头输入的概率;以及通过确定所述特定用户概率测量是否满足阈值来确定所述特定用户是否说出了所述口头输入。在这些实施方式中的一些版本中,响应于确定所述说话者嵌入是使用所述过时版本的所述ti说话者识别模型生成的,所述方法进一步包括确定第一用户配置文件和第二用户配置文件都与所述自动化助理请求相关联。所述方法进一步包括响应于确定第一用户配置文件和所述第二用户配置文件都与所述自动化助理请求相关联,启动生成为所述第一用户定制并且响应于所述口头输入的第一响应内容。所述方法进一步包括启动生成为所述第二用户定制并且响应于所述口头输入的第二响应内容。所述方法进一步包括在完成生成所述第一响应内容和所述第二响应内容之前,使用所述ti说话者识别模型至少处理音频数据的所述部分以生成ti输出。所述方法近一步包括通过比较所述ti输出与所述第一用户的说话者嵌入,确定所述特定用户是否是所述第一用户,以及所述特定用户是否说出了所述口头输入。所述方法进一步包括,响应于确定所述特定用户说出了所述口头输入,进一步包括将所述第一响应内容传输到所述客户端装置,而不是将所述第二响应内容传输到所述客户端装置。
26、在一些实施方式中,提供一种由一个或多个处理器实现的方法,所述方法包括从客户端装置并且经由网络接收自动化助理请求,所述请求包括:捕获用户的口头输入的音频数据,其中所述音频数据在所述客户端装置的一个或多个麦克风处捕获,以及文本相关(td)用户测量,所述td用户测量是使用本地存储在所述客户端装置处的td说话者识别模型以及使用本地存储在所述客户端装置处的td说话者嵌入而在所述客户端装置本地生成的,所述td说话者嵌入用于特定用户。所述方法进一步包括使用文本无关(ti)说话者识别模型处理所述音频数据的至少一部分以生成ti输出。所述方法进一步包括通过比较所述ti输出与ti说话者嵌入来确定ti用户测量,所述ti说话者嵌入与所述自动化助理请求相关联并且用于所述特定用户。所述方法进一步包括使用所述td用户测量和所述ti用户测量两者来确定所述特定用户是否说出了所述口头输入。所述方法进一步包括,响应于确定所述口头输入由所述特定用户说出:生成响应于所述口头话语并且为所述特定用户定制的响应内容。所述方法进一步包括将所述响应内容传输到所述客户端装置使得所述客户端装置基于所述响应内容而呈现输出。
27、本文所公开的技术的这些和其他实施方式可以包括以下特征中的一个或多个。
28、在一些实施方式中,经由所述网络从所述客户端装置接收的所述自动化助理请求进一步包括用于所述特定用户的所述ti说话者嵌入。
29、在一些实施方式中,使用所述td用户测量和所述ti用户测量两者确定所述特定用户是否说出了所述口头输入包括:通过组合所述td用户测量和所述ti用户测量来确定特定用户概率测量,所述特定用户概率测量指示所述特定用户说出了所述口头输入的概率。所述方法进一步包括通过确定所述特定用户概率测量是否满足阈值来确定所述特定用户是否说出了所述口头输入。在这些实施方式的一些版本中,组合所述td用户测量和所述ti用户测量包括在所述组合中利用所述td用户测量的第一权重以及在所述组合中利用所述ti用户测量的第二权重。在这些实施方式的一些版本中,所述方法进一步包括基于所述音频数据或所述口头输入的长度来确定所述第一权重和所述第二权重。
30、在一些实施方式中,所述方法进一步包括基于所述td用户测量的量值来确定所述第一权重和所述第二权重。
31、在一些实施方式中,所述方法进一步包括确定所述td用户测量未能满足阈值,其中处理所述音频数据的所述部分以生成ti输出、确定所述ti用户测量、以及使用所述td用户测量和所述ti用户测量两者确定所述特定用户是否说出了所述口头输入,都是仅响应于确定所述td用户测量未能满足所述阈值而执行的。
32、在一些实施方式中,提供一种由一个或多个处理器实现的方法,所述方法包括从客户端装置并且经由网络接收自动化助理请求,所述请求包括捕获口头输入的音频数据,其中所述音频数据是在所述客户端装置的一个或多个麦克风处捕获的。所述方法进一步包括确定第一用户配置文件和第二用户配置文件都与所述自动化助理请求相关联。所述方法进一步包括响应于确定第一用户配置文件和所述第二用户配置文件都与所述自动化助理请求相关联,启动生成为所述第一用户定制并且响应于所述口头输入的第一响应内容。所述方法进一步包括启动生成为第二用户定制并且响应于所述口头输入的第二响应内容。所述方法进一步包括在完成生成所述第一响应内容和所述第二响应内容之前,使用文本无关(ti)说话者识别模型处理所述音频数据的至少一部分以生成ti输出。所述方法进一步包括通过比较对应于所述第一用户配置文件的第一用户说话者嵌入与所述ti输出来确定所述第一用户说出了所述口头输入。所述方法进一步包括,响应于确定所述第一用户说出了所述口头输入,将所述第一响应内容传输到所述客户端装置,而不是将所述第二响应内容传输到所述客户端装置。
33、本文所公开的技术的这些和其他实施方式可以包括以下特征中的一个或多个。
34、在一些实施方式中,确定所述第一用户说出了所述口头输入发生在完成生成为所述第二用户定制的所述第二响应内容之前,并且进一步包括,响应于确定所述第一用户说出了所述口头输入,停止生成为所述第二用户定制的所述第二响应内容。
35、在一些实施方式中,所述方法进一步包括确定除了所述第一用户配置文件和所述第二用户配置文件之外,第三用户配置文件与所述自动化助理请求相关联。所述方法进一步包括,响应于确定所述第三用户配置文件与所述自动化助理请求相关联,启动生成为所述第三用户定制并且响应于所述口头输入的第三响应内容。
36、在一些实施方式中,确定所述第一用户说出了所述口头输入还基于用于所述第一用户配置文件的文本相关(td)用户测量,所述td用户测量包括在所述自动化助理请求中。
37、在一些实施方式中,所述自动化助理请求进一步包括用于所述第一用户配置文件的第一文本相关(td)测量和用于所述第二用户配置文件的第二td测量,并且其中启动生成所述第一响应内容以及其中启动生成所述第二响应内容进一步响应于所述第一td测量和所述第二td测量未能满足一个或多个阈值。
38、另外,一些实施方式包括一个或多个计算装置的一个或多个处理器(例如,中央处理单元(cpu)、图形处理单元(gpu)和/或张量处理单元(tpu))),其中一个或多个处理器可操作以执行存储在相关联的存储器中的指令,并且其中指令被配置成使得执行本文描述的方法中的任一项。一些实施方式还包括存储计算机指令的一个或多个非暂时性计算机可读存储介质,所述计算机指令可由一个或多个处理器执行以执行本文所描述方法中的任一项。
39、应了解,本文更详细描述的前述概念和附加概念的所有组合都被认为是本文所公开的主题的一部分。例如,出现在本公开末尾的要求保护的主题的所有组合被认为是本文所公开的主题的一部分。
本文地址:https://www.jishuxx.com/zhuanli/20240911/291119.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表