一种基于隐空间图像-文本匹配的医学影像报告生成方法与流程
- 国知局
- 2024-09-11 14:19:31
本发明涉及计算机视觉、自然语言处理和医学影像分析领域交叉的医学影像报告生成方法,尤其涉及一种基于隐空间图像-文本匹配的医学影像报告生成方法。
背景技术:
1、医学影像报告生成是人工智能在临床辅助决策的重要技术之一,目的在于自动生成诊断性文本去描述影像中的病变情况,以提供参考信息辅助影像科医生进行报告撰写,从而减少临床中的漏诊或者误诊现象。近年来,得益于多模态人工智能技术的迅速发展,采用多模态深度学习相关技术实现医学影像报告生成成为当前主流的研究方向。从早期基于结构化模板填充的报告生成方法,到近年基于编码器-解码器网络模型的文本长度可变、结构自由的报告生成方法,再到基于chatgpt等大语言模型的报告生成方法,生成诊断报告的可读性、准确性以及应用性在不断提高。针对给定的医学影像,医生需要对影像中的各器官组织进行观察并撰写文本报告,报告内容和影像中各器官的病变情况互相匹配。因此,要提高报告生成的准确性和可解释性,首先要学习有效的影像视觉表征,建立起影像特征和报告特征之间的跨模态匹配关系。
技术实现思路
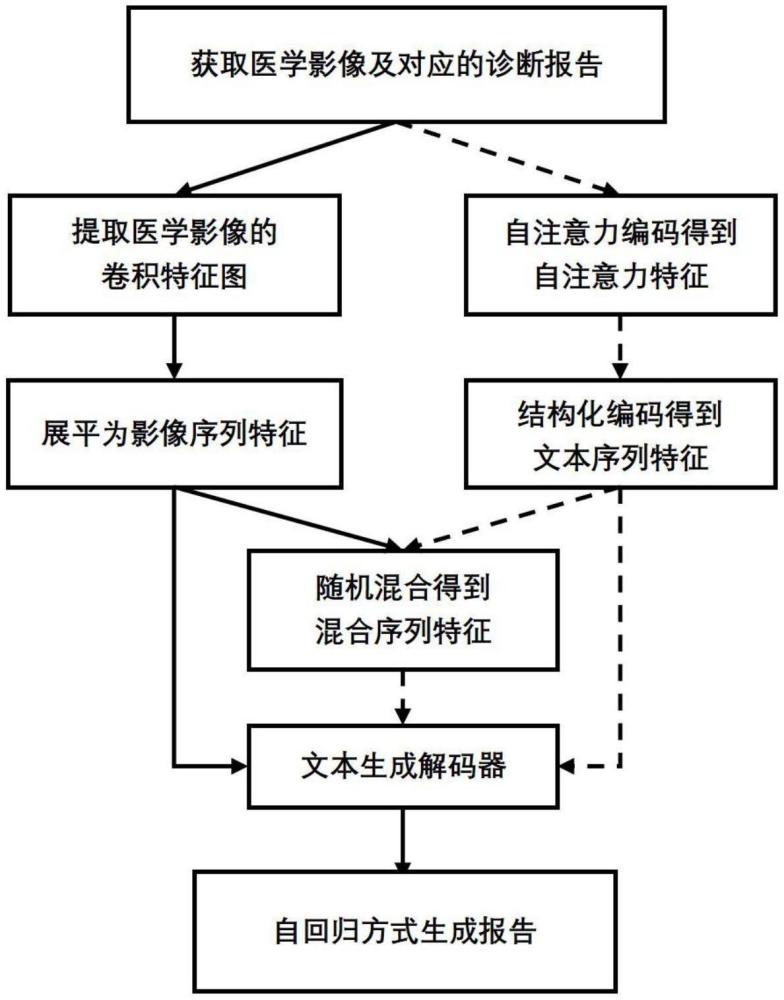
1、本发明的目的是针对现有技术的不足,提出一种基于隐空间图像-文本匹配的医学影像报告生成方法。具体地,本发明通过匹配图像到文本的生成和文本到文本的生成过程,将影像的图像特征和报告的文本特征绑定在同一个隐空间并进行关联。在训练过程中,将医学影像编码为影像序列特征,将对应的诊断报告编码为文本序列特征,并将这两种序列特征随机混合形成混合序列特征。接着,将影像序列特征、文本序列特征和混合序列特征作为提示符号输入到文本生成解码器生成对应的文本,以交替训练的策略来优化模型参数。该方法成功实现了影像和报告之间的语义关联,在三个医学影像报告生成数据集(包括放射影像和病理影像)中都取得了较好的效果。
2、一种基于隐空间图像-文本匹配的医学影像报告生成方法,其具体步骤如下:
3、步骤(1)、选取包含医学影像及其诊断报告的样本{i,r}构成训练数据集。其中,i和r分别表示数据集中的医学影像和互相一一对应的诊断报告;
4、步骤(2)、采用卷积神经网络提取医学影像的卷积特征图,并展平得到影像序列特征用vi表示影像序列特征中的第i个向量,n为影像序列特征的长度,dmodel表示模型的特征维度;
5、步骤(3)、将对应的诊断报告输入到文本自注意力编码层进行自注意力编码,得到自注意力文本序列特征用sl表示自注意力文本序列特征的第l个向量,l为输入报告的文本序列长度;
6、步骤(4)、将自注意力文本序列特征输入到文本结构化编码层进行编码,得到文本序列特征ti表示文本序列特征中的第i个向量,n为文本序列特征的长度,对应的结构化编码公式如下:
7、t=(a×s)w (公式1)
8、其中,表示线性映射矩阵,a∈rn×l为注意力权重矩阵,计算公式如下:
9、a=softmax(w2tanh(w1st)) (公式2)
10、其中,和为线性映射矩阵,dmiddle为结构化映射层的中间特征维度。t表示转置操作,tanh为双曲正切函数,softmax为归一化指数函数;
11、步骤(5)、将影像序列特征v和文本序列特征t通过随机交叉混合得到两种不同的混合序列特征:
12、yt=t⊙mλ+v⊙(1-mλ) (公式3)
13、yv=v⊙mλ+t⊙(1-mλ) (公式4)
14、其中,以及表示混合序列特征,n为混合序列长度。和为线性映射矩阵,dmiddle为结构化映射层的中间特征维度。mλ表示二值随机掩码,λ为掩码的比率,⊙表示逐元素相乘操作;
15、步骤(6)、将影像序列特征v、文本序列特征t、混合序列特征yt以及yv作为文本生成解码器的提示符号,输入文本生成解码器实现报告文本的生成。具体地,模型优化的损失函数如下公式:
16、
17、其中,为交叉熵损失函数,p为输入文本生成解码器的提示符号,可以为影像序列特征v、文本序列特征t、混合序列特征yt或者混合序列特征yv。p表示给定先前相邻时刻t-1生成的报告文本rt-1以及提示符号p,生成当前时刻t的单词为rt的概率;
18、步骤(7)、通过交替训练策略来联合学习模型中各个模块的参数,包括卷积神经网络、文本自注意力编码层、文本结构化编码层和文本生成解码器。具体地,一轮训练包括多个epoch,每一轮训练的最后一个epoch采用进行模型优化,最后第二个epoch采用进行模型优化,其余的epoch采用进行模型优化。随着轮数的增加,掩码的比率λ也会增加,从而加强图文的语义关联。
19、步骤(8)、通过步骤(7)的训练方式,匹配图像到文本的生成和文本到文本的生成过程,将影像的图像特征和报告的文本特征在同一个隐空间进行关联;
20、步骤(9)、在测试过程中,将待测试的影像输入卷积神经网络提取的影像序列特征,并输入文本生成解码器,采用自回归方式生成所有时刻的单词,并取结束字符之前的文本进行串联就实现了完整诊断报告的生成。
21、进一步的,步骤(6)的具体实现如下:
22、6-1.将先前相邻时刻t-1的报告文本rt-1={r1,r2,…,rt-1}进行词向量映射得到et-1={e1,e2,…,et-1}并对et-1中每个对应元素增加对应的位置编码信息,记为报告文本的映射特征e0,其中t≥2。
23、6-2.将序列长度为n的提示符号p和映射特征ei进行拼接输入文本生成解码器,ei的初始值为映射特征e0;文本生成解码器由多个子解码层构成,每个子解码层包括多头注意力层和线性层,具体公式如下:
24、xi=[p;ei] 公式(6)
25、oi=ffn(mha(xi,xi,xi)) 公式(7)
26、ei+1=oi[n+1:n+t-1] 公式(8)
27、其中,i表示第i个子解码层,[;]表示特征拼接操作,mha表示多头注意力层,ffn表示线性层。ei表示第i个子解码层中报告文本对应的映射特征,序列长度为t-1。xi和oi表示第i个子解码层的输入和输出,序列长度为n+t-1。[start:end]表示序列切片操作,取输入序列的start到end的元素。mha由多个头head构成,表示为以下公式:
28、mha(q,k,v)=[head1;…;headh]wo 公式(9)
29、
30、
31、其中,表示第n个头headn的映射矩阵,表示多头注意力层输出的映射矩阵,dk表示q和k的维度,dv表示v的维度。线性层ffn表示为以下公式:
32、ffn(x)=max(0,xwf1+b1)wf2+b2 公式(12)
33、其中,wf1和wf2表示线性映射矩阵,b1和b2表示偏置。
34、6-3.取步骤6-2中文本生成解码器的最后一个子解码层输出的通过线性映射和softmax操作得到当前时刻t的文本输出rt,具体公式如下:
35、
36、其中,wp表示线性映射矩阵,bp表示偏置,u表示子解码层的总数量,pt表示时刻输出的文本单词分布;
37、6-4.采用自回归方式生成所有时刻的单词,并取结束字符之前的文本进行串联,实现完整的诊断报告的生成。
38、本发明的有益效果在于:
39、本发明提出将影像到报告的生成过程和报告到报告的生成过程在一个隐空间进行匹配,为模型学习影像视觉表征和报告文本表征之间的有效语义关联关系提供了一个新的思路。在学习到有效的视觉表征和语义表征后用于医学影像报告生成任务,能够实现快速报告输出,提供诊断报告给影像医生参考,从而辅助医生进行诊断,减少误诊和漏诊现象。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290177.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表