一种聚类中心更新方法和K均值聚类算法加速系统
- 国知局
- 2024-09-11 14:19:31
本发明涉及聚类算法,具体涉及一种聚类中心更新方法和k均值聚类算法加速系统。
背景技术:
1、在传统的k均值聚类算法中,算法步骤大致可以这样描述:
2、1、初始化:首先,为每个聚类随机选取一个初始的聚类中心,这些中心通常是数据点或者通过特定算法(如k-means++)精心选择。
3、2、距离计算:接着,遍历遍历数据集中的每一个数据点,计算它到所有聚类中心的欧氏距离(即l2距离),然后将每个数据点分配给最近的聚类中心所属的类。
4、3、归类:对于每个类,统计被分配给它的所有数据点。对于类内的每一个维度,累加这些数据点在该维度上的值,形成一个累加和。
5、4、更新聚类中心:在累加完成后,对每个聚类,将该类内所有数据点的每个维度的累加和除以该类的成员数(即属于该类的数据点数量),得到新的聚类中心的坐标值。简而言之,新的聚类中心的每个维度是该维度所有数据点值的均值。
6、5、重复:重复步骤2至4,直到聚类中心的变化小于某个阈值,或者达到预设好的迭代次数,算法结束。
7、这个过程实质上是通过不断迭代,逐步调整聚类中心位置,使每个聚类内数据点到中心的总距离最小化,以此达到数据聚类的目的。每一次迭代中,聚类中心的更新依赖于当前数据点的分配,而数据点的分配又依赖于聚类中心的位置,二者相互影响,直至收敛。
8、在传统的硬件实现中,更新聚类中心的步骤通常涉及对每个聚类逐一处理,需要访问内存来读取和更新聚类中心的坐标值,这涉及到大量的读写内存操作,在多线程或并行环境下,还会遇到内存一致性问题。
技术实现思路
1、本发明的目的在于克服背景技术中存在的上述缺陷或问题,提供一种聚类中心更新方法和k均值聚类算法加速系统,其能够改善现有技术中更新聚类中心的方法存在的频繁读写内存造成的延迟问题,以及由于内存一致性无法并行处理数据的问题。
2、为达成上述目的,本发明采用如下技术方案:
3、技术方案一:一种聚类中心更新方法,其用于对k均值聚类算法中的聚类中心进行更新;k均值聚类算法在进行聚类中心更新步骤前,还包括初始化、距离计算和归类步骤;所述初始化步骤设定有若干类,每一类包括一初始的聚类中心;所述距离计算步骤计算所有数据点与各个聚类中心的距离;所述归类步骤基于距离计算步骤所得到的距离,对每一数据点赋予对应其所属类的编号;所述聚类中心更新步骤包括:逐次获取并行处理的数据点和与各数据点对应的编号;将每次获取的数据点存储至数据点矩阵,数据点矩阵的行对应于并行处理的各个数据点,列对应于每一数据点的各个维度;将每次获取的编号存储至编号矩阵,编号矩阵的行对应于并行处理的各个编号,列对应于每一编号所对应的类;将同一次存储的数据点矩阵和转置后的编号矩阵相乘,得到输入矩阵;逐次地将输入矩阵累加,得到累加矩阵;逐次地将编号矩阵累加,得到数量矩阵;将累加矩阵与数量矩阵相除,得到聚类矩阵;所述聚类矩阵的行对应于各个类,列对应于每一类的聚类中心的各个维度。
4、基于技术方案一的技术方案二:每次获取的编号通过以下公式进行处理后存储至编号矩阵:编号矩阵=relu((a-编号)·(2-a+编号));其中,relu函数公式为:a=[1,2,3,4,5,6…,kmax],kmax为聚类中心的最大数量;所述编号矩阵中,以每一行中元素1的位置表示该编号对应的类。
5、基于技术方案一的技术方案三:所述数据点矩阵的大小为(pd,dmax),pd为数据点并行度,表示并行处理的数据点的数量,dmax为数据点的最大维度;每次获取的数据点的维度不足dmax个时,将不足的位置的元素取0。
6、基于技术方案一的技术方案四:所述数据点矩阵在每次获取完毕所有并行处理的数据点后,输出存储结果并将所有元素清零以重新开始获取下一次的并行处理的数据点。
7、基于技术方案一的技术方案五:所述编号矩阵在每次获取完毕所有并行处理的数据点对应的编号后,输出存储结果并将所有元素清零以重新开始获取下一次的并行处理的数据点对应的编号。
8、基于技术方案一的技术方案六:通过计数器对获取的数据点进行计数以实现对并行处理的数据点的逐次获取;所述计数器的预设值为数据点的维度,在每一次获取完毕一个数据点时计数器重置,当计数器的重置次数与并行处理的数据点的数量一致时,完成一次对并行处理的数据点的获取。
9、基于技术方案一的技术方案七:在得到聚类矩阵后,对聚类矩阵中的各个元素进行提取并存储,以供下一次迭代取用。
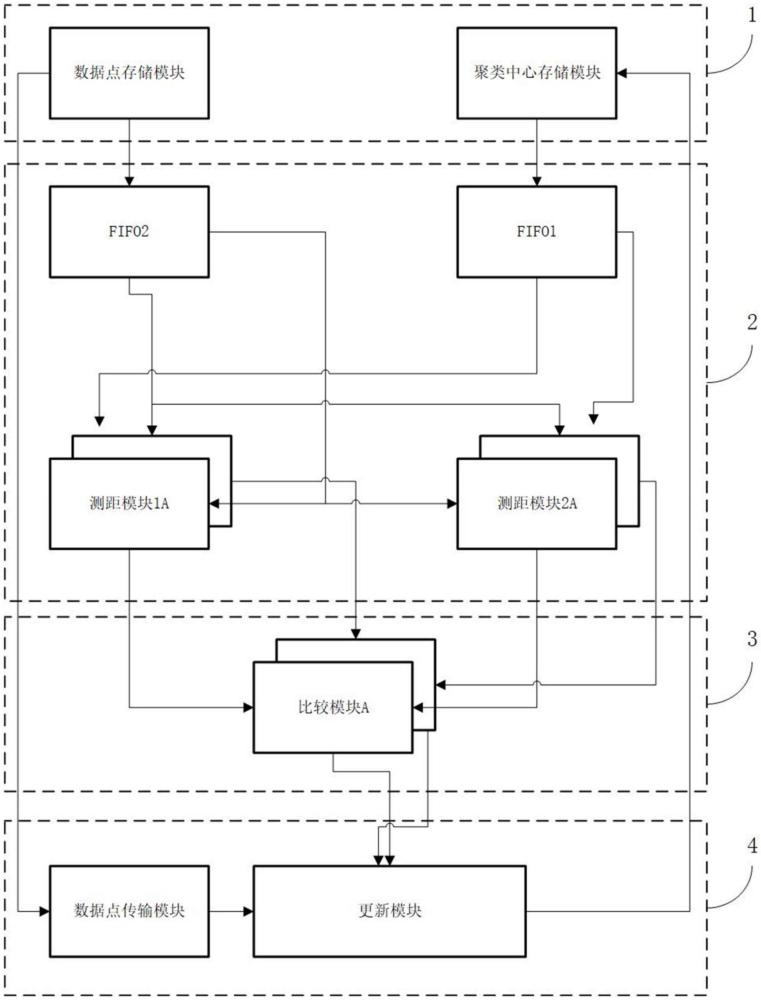
10、此外,本发明还提供技术方案八:一种k均值聚类算法加速系统,其用于对k均值聚类算法进行加速,其包括:输入组件,其包括数据点存储模块和聚类中心存储模块,所述数据点存储模块存储所有数据点,所述聚类中心存储模块存储所有聚类中心;测距组件,其包括若干测距模块,所述测距模块接收数据点存储模块传输的数据点和聚类中心存储模块传输的聚类中心,并计算每一数据点与各聚类中心的距离;归类组件,其包括若干比较模块,所述比较模块用于对比测距组件计算得到的距离得到与数据点距离最近的聚类中心,并将该聚类中心对应的类的编号赋予该距离点;和更新组件,其采用如权利要求1-7任一项所述的聚类中心更新方法对聚类中心进行更新,其接收的数据点和编号分别来自于所述输入组件和归类组件,更新后的聚类中心传输至所述聚类中心存储模块。
11、基于技术方案八的技术方案九:所述更新组件包括:数据点传输模块,其用于接收并逐次输出并行处理的数据点;更新模块,其用于获取数据点传输模块逐次输出的并行处理的数据点和与数据点对应的编号,并根据技术方案一至七任一项所述的聚类中心更新方法对聚类中心进行更新。
12、基于技术方案八的技术方案十:所述测距组件中,测距模块分为两组以同时计算一数据点与两聚类中心的距离,每一组包括与并行处理的数据点的数量一致的测距模块以同时计算多个数据点与聚类中心的距离;所述归类组件中,比较模块的数量与并行处理的数据点的数量一致以同时对多个数据点进行比较。
13、由上述对本发明的描述可知,相对于现有技术,本发明具有如下有益效果:
14、本发明提供的聚类中心更新方法,采用了矩阵运算替代常规的内存读写操作,改善了现有技术中更新聚类中心的方法存在的频繁读写内存造成的延迟问题,以及由于内存一致性无法并行处理数据的问题。
15、该聚类中心更新方法在获取数据点和对应的编号后,形成数据点矩阵和编号矩阵,之后将二者相乘得到输入矩阵,输入矩阵累加即可得到累加矩阵,同时编号矩阵累加即可得到数量矩阵;其中,累加矩阵保存了属于同一类的数据点的累加值信息,数量矩阵保存了每个类中已经累加的数据点的数量,通过二者分别保存的数据点和分类的信息,最后相除即可得到聚类矩阵,聚类矩阵保存了新的聚类中心的信息。数据点矩阵用于将并行处理的数据点整合为矩阵,方便后续的并行计算操作;编号矩阵是将数据点对应的编号信息以矩阵的方式拼接,并用于与数据点矩阵相乘得到新的输入矩阵。在对矩阵的处理过程中,输入矩阵累加是指在每一次得到输入矩阵后,将该次得到的输入矩阵与之前的累加矩阵相加,得到新的累加矩阵;数量矩阵的累加与之类似。
16、通过将数据点矩阵和编号矩阵相乘,可以将数据点分配至对应的位置,避免了常规的更新方法中需要通过编号进行内存搜索,才能将数据点放入对应的位置;另一方面,分配到同一个位置的数据点会进行矩阵的加法,从而把常规更新方法中需要对内存进行多次读写操作汇总成一次操作,有效地降低了多次读写内存所造成的延迟;每一次对累加矩阵的加法,都可在原有的累加矩阵的数据点的信息上加上该次获取的并行处理的多个数据点的信息,因此通过一次矩阵加法即可替代常规更新方法中需要进行的多次读写操作。
17、此外,编号通过转换处理存储至编号矩阵,该处理方式可以并行地对多个编号进行处理,还能够替代地址映射的操作,再通过矩阵加法得到数量矩阵的方式去汇总多次累加计算,可降低常规更新方法中内存频繁读写造成的延迟。
18、本发明还提供k均值聚类算法加速系统,该加速系统中的更新组件采用了上述的聚类中心更新方法,改善了现有技术中更新聚类中心的方法存在的频繁读写内存造成的延迟问题,以及由于内存一致性无法并行处理数据的问题。
19、此外,该加速系统还可以通过设置多个测距模块、比较模块来调整数据点处理的并行度,以满足不同的处理需求。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290176.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。