一种基于大小模型协同的银行客服对话文本纠错方法与流程
- 国知局
- 2024-09-11 14:26:58
本发明涉及数据处理,具体涉及一种基于大小模型协同的银行客服对话文本纠错方法。
背景技术:
1、在当今数字化时代,文本信息的准确性和质量对于金融行业各类应用场景至关重要,尤其是银行业务中,从合同文档、财务报告到客户服务对话,文本的准确性直接关联到资金流转的正确性与法律法规的遵循。在银行客服为客户服务的过程中,客服和客户之间的对话通常会被记录,银行以此来保证服务质量和防止未来产生纠纷,同时为了方便后续审核和质检,一般会保存语音和自动语音识别(asr)后的转译文本两份记录。但asr识别时可能会受到录音环境噪声、对话双方音调音色等因素的影响,导致转译后的文本存在各种各样的错误,所以需要通过文本纠错方法对其进行识别纠正,确保文本信息的准确性。然而,传统的文本纠错方法大多依赖于规则匹配、统计模型或简单机器学习技术,这些方法在处理常见语法错误和拼写错误方面具有一定效果,但在面对复杂语境、专业术语、新兴表达及多语言混杂等情境时,纠错能力往往显得力不从心。
2、随着人工智能技术的飞跃发展,特别是自然语言处理(nlp)领域的进步,大语言模型(llm)凭借其在大规模文本数据上训练出的深厚语言理解和生成能力,为文本纠错提供了新的可能性。大语言模型能够捕捉语言的细微差异和复杂结构,理解上下文含义,从而在纠错过程中不仅能够识别并修正基础的拼写和语法错误,还能处理语义偏差、专有名词误用、不恰当的表达形式等问题,显著提升纠错的准确率和智能化水平。然而,现在市面上很多的大模型都是通用大模型,这类大模型缺少企业内部的数据和用户数据,缺乏对一些专业领域知识的了解,因此面对特定领域时可能需要重新训练模型或者通过微调模型来让大模型学到更多专业知识,但是又因为大模型的训练往往需要大量的硬件资源和时间成本,导致重新训练或微调的成本大大增加,这对于一些资源有限的企业和个人来说,可能会存在较大的门槛。
技术实现思路
1、本发明的目的是提供一种基于大小模型协同的银行客服对话文本纠错方法,解决传统文本纠错方法中的问题,提高文本纠错的准确率。
2、为了实现上述目的,本发明提供如下技术方案:一种基于大小模型协同的银行客服对话文本纠错方法,包括:
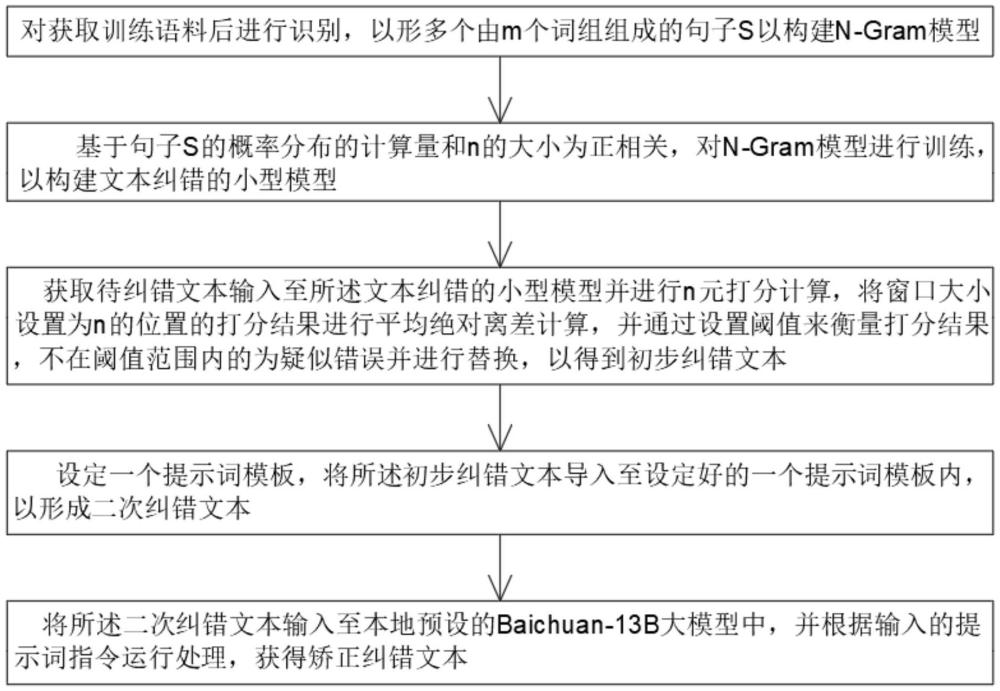
3、s01、对获取训练语料后进行识别,以形成多个由m个词组组成的句子s以构建n-gram模型;
4、s02、基于句子s的概率分布的计算量和n的大小为正相关,对n-gram模型进行训练,以构建文本纠错的小型模型,其中:
5、当n=2时,对应的p(s)计算公式如下所示:
6、
7、当n=3时,对应的p(s)计算公式如下所示:
8、
9、s02、获取待纠错文本输入至所述文本纠错的小型模型并进行n元打分计算,将窗口大小设置为n的位置的打分结果进行平均绝对离差计算,并通过设置阈值来衡量打分结果,不在阈值范围内的为疑似错误并进行替换,以得到初步纠错文本;
10、s03、设定一个提示词模板,将所述初步纠错文本导入至设定好的一个提示词模板内,以形成二次纠错文本;
11、s04、将所述二次纠错文本输入至本地预设的baichuan-13b大模型中,并根据输入的提示词指令运行处理,获得矫正纠错文本。
12、作为优选的,所述步骤s01对获取训练语料后进行识别,包括:
13、s11、将训练语料文本里的内容按照字节进行长度为n的滑动窗口操作,形成了长度为n的字节片段序列,其中,每个字节片段定义为gram;
14、s12、对所有gram的出现频率进行统计,并且按照设定的阈值进行过滤,形成文本的向量特征空间,其中,每一种gram就是一个特征向量维度。
15、作为优选的,所述步骤s02中句子s的概率分布的计算量和n的大小为正相关为文本的向量特征空间中第n个词出现与前n-1个词相关,整个句子s出现的概率就等于各个词n出现的概率乘积。
16、作为优选的,所述步骤s02中s=w1w2w3.....,wm,则构建的n-gram模型通过如下公式表示:
17、p(s)=p(w1)p(w2|w1)p(w3|w1w2)...p(wm|w1w2w3...wm-1);
18、其中,p(s)表示句子s在语料库中出现的概率,p(wm|w1w2w3...wm-1|)表示句子s在前m-1个词为w1w2w3...wm-1的情况下,第m个词为wm的概率
19、作为优选的,所述步骤s02得到所述初步纠错文本的步骤包括:
20、s21、将疑似错误的字词通过已建立的词典进行字音字形的替换,构成纠错候选集合;
21、s22、将候选纠错字词代入句子中,通过ppl困惑度计算句子通顺程度并进行计算得分,ppl困惑度计算公式如下:
22、
23、其中,m代表句子长度,p(wi)代表第i个词的概率;
24、s23、取ppl最大值对应的文本为纠错正确的文本。
25、作为优选的,所述步骤s02中平均绝对离差计算用于度量数据的离散程度,当每一句离散程度过大,则该点为异常数据点表现为文本可能出现错误的位置。
26、作为优选的,将所述步骤s23中获取的所述纠错正确的文本作为历史数据记录在词典和语料库内作为训练集合,利用kenlm工具对所述文本纠错的小型模型进行训练,以获取新的文本纠错的小型模型。
27、作为优选的,所述训练语料包括银行业务领域的专业词汇以及术语。
28、在上述技术方案中,本发明提供的一种基于大小模型协同的银行客服对话文本纠错方法,具备以下有益效果:通过将训练语料文本根据句号,划分为若个独立的句子s,然后再将整句s拆分为若干词义的词组,然后通过文本纠错的小型模型计算获取错误的每一个整句s中的若干词组。然后再利用平均绝对离差计算将获得评分数据与预设的阈值进行,从而将在预定阈值范围内的错误进行选取,然后再将错误的词组输入至提示词模板内,在通过已有的baichuan-13b大模型中进行错误词组替换。通过对每一个单独的句子s中的词组划分以及对划分出来的词组的评价,从而加快文本纠错的速度。
技术特征:1.一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,包括:
2.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述步骤s01对获取训练语料后进行识别,包括:
3.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述步骤s02中句子s的概率分布的计算量和n的大小为正相关为文本的向量特征空间中第n个词出现与前n-1个词相关,整个句子s出现的概率就等于各个词n出现的概率乘积。
4.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述步骤s02中s=w1w2w3.....,wm,则构建的n-gram模型通过如下公式表示:
5.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述步骤s02得到所述初步纠错文本的步骤包括:
6.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述步骤s02中平均绝对离差计算用于度量数据的离散程度,当每一句离散程度过大,则该点为异常数据点表现为文本可能出现错误的位置。
7.根据权利要求5所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,将所述步骤s23中获取的所述纠错正确的文本作为历史数据记录在词典和语料库内作为训练集合,利用kenlm工具对所述文本纠错的小型模型进行训练,以获取新的文本纠错的小型模型。
8.根据权利要求1所述的一种基于大小模型协同的银行客服对话文本纠错方法,其特征在于,所述训练语料包括银行业务领域的专业词汇以及术语。
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至8任一项所述基于大小模型协同的银行客服对话文本纠错方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至8任一项所述基于大小模型协同的银行客服对话文本纠错方法的步骤。
技术总结本发明公开了一种基于大小模型协同的银行客服对话文本纠错方法,具体涉及数据处理技术领域,对获取训练语料后进行识别,以形成多个由m个词组组成的句子S以构建N‑Gram模型;S02、基于句子S的概率分布的计算量和n的大小为正相关,对N‑Gram模型进行训练,以构建文本纠错的小型模型。该方法在经过大小模型协同作用下连续两次的文本纠错后,最终获得的文本具有较高的准确率和连贯性,能够大大减轻银行员工的工作压力,避免耗费大量的时间和精力对文本信息进行审查、纠错,从而把更多精力放在分析、质检、决策等重要工作上。技术研发人员:林路,夏天舒,宣明辉,章东平,汤斯亮,张帅,刘中秋,陈萍,张文桥,余家斌,张文宇受保护的技术使用者:信雅达科技股份有限公司技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/290859.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。