一种基于影响函数的恶意语音检测方法
- 国知局
- 2024-09-14 15:01:51
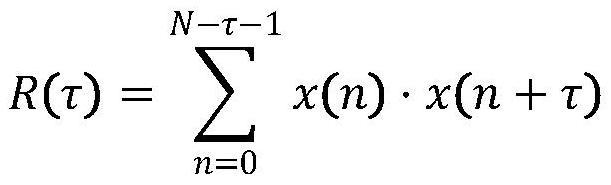
本发明涉及深度学习、机器学习可解释性,是一种基于影响函数的恶意语音检测方法。
背景技术:
1、随着深度学习技术的迅猛发展,语音识别与处理领域能够从前所未有的角度捕捉和解析自然语言。深度学习模型,特别是卷积神经网络cnns、循环神经网络rnns及其变种长短期记忆网络lstms,已经被证明在提取语音信号中的关键信息方面表现卓越。这些进步不仅极大地推进了智能语音助手的实用性,还为视频内容自动生成字幕等实时应用提供了技术支撑。然而,在推进技术的同时,也暴露出一系列新的挑战,尤其是在训练数据中识别和处理包含恶意内容的语音样本的问题尤为突出。
2、这些恶意语音样本的内容可能涵盖了各种攻击性、欺诈性的信息,或其他可被视为不当的言论。如果不能妥善管理和预处理这些数据,会造成模型训练出现偏差,进而影响整个模型的泛化能力和应用的安全性。例如,恶意语音能够操纵语音识别系统执行不当的命令,或者在自动内容审查系统中引入错误,造成严重后果。
3、面对现实中对自动化恶意语音检测的需求,过于依赖传统的人工审核机制已显不足。人工审核不仅耗时耗力,且易受主观偏见影响,而简单的过滤规则在处理复杂、高维度的语音数据时更是力不从心。考虑到现代语音数据的多样性和它所表现出的复杂时间序列特性,单一和静态的检测规则无法有效地区分恶意内容。
4、面对这种局面,急需更为高效和智能的自动检测方法。利用深度学习自身的特点,结合大数据分析,可以发展出自动区分恶意语音的算法。例如,借助自然语言处理和情绪分析技术,我们可以训练专门的深度学习模型来识别语调、语速、停顿以及其他语音特性,从而检测潜在的恶意意图。通过这些技术,可以构建一个多层次综合判定系统,它既可以捕捉到明显的攻击性语言,也能细致分析语言中的隐含情绪和微妙变化。
5、除此之外,对抗性训练可以增强模型对恶意样本的鲁棒性,通过引入专门设计的噪音和扭曲样本来教会模型识别和抵抗潜在的攻击或欺骗企图。此外,集成学习方法通过组合多个模型提升检测准确率和系统的健壮性,使得系统能够在面对不断演变的恶意攻击时保持灵活和有效。
6、总之,为了保障语音处理系统的准确性与安全性,现代技术必须致力于开发出新的方法来应对恶意语音样本带来的挑战。只有这样,深度学习技术在语音识别与处理领域的边界才能不断推进,从而为用户提供更为安全、智能且便捷的服务体验。
技术实现思路
1、本发明针对现有技术存在的技术问题,提供了一种基于影响函数的恶意语音检测方法。
2、本发明所采取的技术方案如下:一种基于影响函数的恶意语音检测方法,其步骤为:
3、1)语音数据集特征的提取:提取基频、梅尔频率倒谱系数、线性预测编码系数、短时能量;
4、1.1)基频f0:基频提取没有固定的公式,因为它依赖于特定的算法或方法,简单的自相关公式如下:
5、
6、其中,r(τ)表示自相关函数,x(n)是时间序列信号,τ是滞后量,n是信号长度。
7、1.2)梅尔频率倒谱系数mfcc:首先,对信号进行预加重和分帧,然后对每一帧使用汉宁窗,即对窗口化后的每一帧信号进行快速傅里叶变换(fft),计算得到功率谱,使用梅尔滤波器组处理功率谱,对每一帧进行离散余弦变换(dct)得到mfcc。
8、
9、其中,w(n)为第n帧的汉宁窗,n是窗口大小。
10、1.3)线性预测编码系数lpc:lpc模型假设当前样本的值可以作为过去样本值的线性组合,加上一个误差项。公式可以表示为:
11、
12、其中,是当前样本的预测值,ai是预测系数,x(n-i)是过去的样本值,e(n)是误差项,p是模型阶数,
13、1.4)短时能量:短时能量的计算公式是:
14、
15、其中,e(m)表示第m帧的能量,x(m+n)表示第m帧的第n个样本值,n为帧长。
16、2)原始影响函数:计算输入特征对应模型影响,对于每个输入特征xtest,ytest,计算在模型中的影响梯度公式如下:
17、
18、其中,x和y分别表示训练数据点的输入和输出,xtest和ytest分别表示测试数据点的输入和输出,θ表示模型的参数,l(x,y,θ)表示给定参数θ的模型的损失函数,和分别表示关于输入x和参数θ的梯度。hθ为参数θ下损失函数的二阶导数矩阵。
19、hessian矩阵h(θ)计算方法如公式所示:
20、
21、其中,θ∈rn为参数向量,ri(θ)为第i个残差项;
22、3)优化影响函数:近似雅可比矩阵转置、权矩阵和雅可比矩阵的乘积来代替hessian矩阵,使用之前得到的特征重要度矩阵作为权重矩阵,对特征的残差分配重要度权重,雅可比权重矩阵g(θ)计算方法如公式所示:
23、g(θ)=j(θ)twj(θ)
24、其中,g(θ)表示损失函数关于参数θ的一阶导数矩阵,j(θ)表示非线性函数ri(θ)对参数向量θ的偏导数矩阵,w是一个对角矩阵,对角线上的元素表示每个残差对应的特征权重;
25、雅可比矩阵j(θ)计算如公式所示
26、
27、其中,θ∈rn参数向量,ri(θ)第i个残余项并且第i行是
28、优化后的影响函数如公式所示:
29、
30、4)语音检测:通过3)中的方法计算雅可比矩阵,通过雅可比矩阵和特征权重,计算得出特征重要性权重矩阵,并通过损失函数计算特征的损失,最终得出单个样本对模型的影响,如果影响超出设定的阈值,认定该样本就是恶意样本,如果影响低于设定的阈值,认定该样本不是恶意样本。
31、本发明创造的有益效果为:本发明不仅为解决深度学习在处理杂净数据方面的挑战提供了新的思路,也为数据科学领域的其他相关任务提供了可行的技术手段,有望成为未来数据分析和模型优化工作的重要工具。
技术特征:1.一种基于影响函数的恶意语音检测方法,其特征在于,其步骤为:
2.根据权利要求l所述的一种基于影响函数的恶意语音检测方法,其特征在于,所述的1)中,具体方法为:
技术总结一种基于影响函数的恶意语音检测方法,该方法通过分析数据点对模型预测的影响度,增强了深度学习模型在恶意语音检测领域的可解释性。利用影响函数对原始声音信号中可能存在的恶意语音进行识别和检测,大幅提升了检测精度和效率。相较于传统方法,该方法通过影响函数使用较少的计算量来达到较好的检测效果。这种技术在保持检测在效率和优势方面表现出色,为深度学习和解释性机器学习领域提供了新的应用可能。该技术不仅提高了恶意语音检测的准确性,还能准确地识别并解释模型为何将特定语音判定为恶意,从而在确保检测率的同时,提升了模型的透明度和信任度。技术研发人员:周翰逊,张硕,王学智,王妍,郭薇,邰滢滢受保护的技术使用者:辽宁大学技术研发日:技术公布日:2024/9/12本文地址:https://www.jishuxx.com/zhuanli/20240914/296706.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表