基于ClusterCentroids欠采样技术预测多种赖氨酸修饰位点的方法
- 国知局
- 2024-10-09 15:49:18
本发明属于人工智能算法应用-生物序列识别领域,涉及一种预测多种赖氨酸翻译后修饰位点的方法。
背景技术:
1、蛋白质的翻译后修饰(post-translationalmodifications,简称ptms)是调控蛋白质功能的关键环节,对细胞活动具有至关重要的影响。ptms涵盖了多种修饰类型,包括磷酸化、甲基化、乙酰化等,这些修饰方式共同作用于蛋白质,影响其结构和功能。异常的ptms与多种疾病的发生和发展紧密相关,因此,准确鉴定ptm位点对于揭示生物过程和疾病形成的分子机制至关重要。
2、近年来,随着人工智能技术的发展,机器学习技术在检测翻译后修饰位点方面取得了显著进展,相较于传统技术,具有成本更低、操作更简便等优势。然而,尽管取得了一定的成果,现有的机器学习技术在预测多种赖氨酸翻译后修饰位点的准确性上仍面临一些挑战:
3、1.串扰问题:当前的许多预测多种赖氨酸翻译后修饰位点的发明倾向于孤立地预测单一类型的ptms,未能充分考虑到不同ptms在单一蛋白质或跨蛋白质间的相互作用和协同效应。这种忽视可能低估了对蛋白质功能调控的复杂性,进而影响预测的全面性和准确性。
4、2.数据不平衡:在多种赖氨酸修饰位点的预测方法发明中,样本数据在不同类别间的分布极不均衡。这种不平衡可能在模型训练时引起偏差,导致评估指标失真,决策边界发生偏移,最终降低模型的稳定性和预测的准确性。
5、3.序列依赖性:生物序列内各组分的相互依赖关系对于蛋白质的功能至关重要。然而,传统机器学习模型通常难以准确捕捉这种复杂的序列依赖性,这限制了模型深入分析和有效应用序列信息的能力。
6、4.模型解释性:在生物性功能预测领域,模型的准确性固然关键,但模型的可解释性同样不可忽视。一个易于解释的模型能够清晰地展示其预测逻辑,这不仅提升了模型的透明度,也增强了其可信性。
7、因此,迫切需要开发一种新型工具,该工具能够综合考虑多种氨基酸残基上的ptm(翻译后修饰)相互影响,有效处理样本不平衡问题,充分考虑序列之间的依赖关系,并具备高度的鲁棒性和良好的解释性。这样的工具不仅可以准确预测多种赖氨酸修饰位点,还能保证结果的可解释性。
技术实现思路
1、为了解决上述问题,本发明提供了一种基于clustercentroids欠采样技术预测多种赖氨酸修饰位点的方法。
2、本发明的技术方案如下:
3、本发明使用数据均源自cplm4.0,这一数据库专注于记录蛋白质中赖氨酸残基侧链氨基经历的多种特定位置翻译后修饰(ptms),该数据库为的发明提供了共计18,978个人类蛋白质序列。为了构造适合训练和测试的数据集,采取了细致而严谨的数据处理策略。然而,发现该数据集存在超过100:1的极度不平衡问题,增加了模型泛化的难度。因此,针对这一问题,本发明提出了一种基于minibatchkmeans的clustercentroids欠采样技术,用于预测多种赖氨酸修饰位点。且本发明采用多标签具体位置三联氨基酸倾向特征提取算法,并结合基于cnn的多标签分类器进行分类,最终开发了一个用户友好型预测器,并对该模型进行了shap可解释分析。
4、基于clustercentroids欠采样技术预测多种赖氨酸修饰位点的方法,步骤如下:
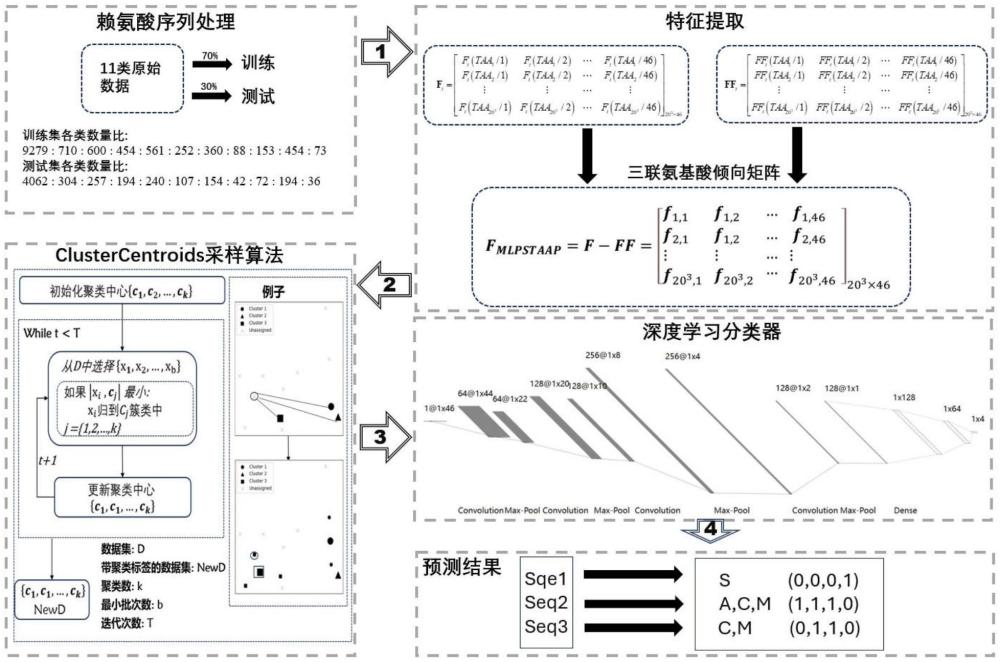
5、第一步:数据集构造
6、为了开发统计预测模型,构建可靠的训练和测试数据集至关重要,因此采取了细致而严谨的策略。具体步骤如下:
7、1.1序列截取与验证:对于收集的18978条人类蛋白质序列,截取实验验证赖氨酸(k)为“acetyllysine”或“crotonyllysine”或“methyllysine”或“succinyllysine”修饰的肽片段(以k为中心,滑动窗口大小为24,即肽片段长度为49)。每条肽片段都可以表示为式(1)的形式:
8、p=r-24r-23…r-2r-1r1r2…r23r24 (1)
9、1.2数据分类与优化:对于预处理的四种赖氨酸修饰数据(acetyllysine、crotonyllysine、methyllysine和succinyllysine),总共可获得十五个类别,去掉序列少于60条的类别,最后数据集被划分成十一个类别:
10、
11、数据类别说明:指中心位置的赖氨酸仅包含乙酰化修饰的蛋白质序列。指既包含乙酰化又包含巴豆酰化修饰的蛋白质序列。其中∩表示该类别样本兼具多种翻译后修饰。去除了数据中重复的肽片段,得到11类数据,各自的样本数量如下:
12、如上述可知第一类样本数量为39938,第二类样本数量为2463,依此类推。为确保评估多标签预测模型时不会因序列的冗余性和同源性导致性能评估偏高,本发明使用了cd-hit程序,并将阈值设置为0.4,以消除这些潜在的同源序列和冗余样本。对于获得的11类数据,随机抽取每个类70%作为训练数据,剩余的30%作为测试数据,得到去冗余后的分割数据集如下:训练集:
13、
14、
15、测试集:
16、
17、
18、第二步:特征提取
19、为了能让计算机识别第一阶段清洗过的数据,本阶段对数据进行特征提取。实验结果表明,针对多种赖氨酸修饰位点预测问题,所采用的多标签具体位置三联氨基酸倾向算法在赖氨酸序列的特征表示方面表现出色。该算法包括3个步骤,具体如下:
20、2.1计算每类赖氨酸序列中每种三联氨基酸在每个位置出现的频率,获得矩阵ft,其数学表达式如下:
21、
22、其中ft(taai/j)表示第t类赖氨酸序列中第taai中三联氨基酸在第j个位置上出现的频率。由此可知共有203个三联氨基酸(taas),taai∈{aaa,aac,aad,…yyy},即taa1=aaa,taa2=aac,…,taa203=yyy,其中i=1,2,3,…,203,j=1,2,3,…,46。
23、2.2计算除第t类外其他十类赖氨酸序列中每种二联氨基酸在每个位置出现的频率,获得对应第t类的矩阵fft其数学表达式如下:
24、
25、其中ft(taai/j)表示除了第t类外的其他十类赖氨酸序列taai三联氨基酸在第j个位置上出现的频率。
26、2.3构建特征矩阵fmlpstaap
27、
28、其中fi,j=ft(taai/j)-fft(taai/j),f=(f1+f2+…+f11)/11,ff=(ff1+ff2+…+ff11/11。
29、第三步:数据不平衡处理
30、在对数据特征提取完成之后,获取维度为46的数据。为使得数据整体趋于平衡,本发明使用基于minibatchkmeans的clustercentroids欠采样算法对第一类数据进行处理。其具体如下:
31、3.1数据不平衡问题:
32、数据类别失衡问题指的是在数据集中,不同类别的样本数量存在显著差异,多数类样本数量远超过少数类。这种不平衡对机器学习模型的影响主要表现在以下几个方面:
33、1.模型偏差:模型可能倾向于过度拟合多数类,导致对少数类的识别能力下降,影响整体分类性能。
34、2.评估指标误导:在数据不平衡的情况下,仅使用准确率作为评估标准可能会产生误导,因为即使模型总是预测多数类,也能获得高准确率,但这并不代表模型具有实际的分类能力。
35、3.决策边界偏移:为了追求高准确率,模型可能会调整决策边界,使之更有利于多数类,从而增加少数类的分类错误率,降低模型的泛化能力。
36、4.训练过程问题:数据不平衡可能导致模型在训练过程中收敛到局部最优解,难以覆盖所有类别,有时需要更长的时间来收敛。
37、由此可见,在进行分类模型的构建之前,解决数据不平衡至关重要。本发明应用了clustercentroids下采样技术,通过聚类确定多数类的代表中心,并用这些中心生成的新样本替换原有样本,有效缓解了过拟合,增强了对少数类的识别,促进了模型的公平性和预测性能。
38、3.2clustercentroids算法:
39、clustercentroids算法主要被用于调整样本分类中数目较多的类别以对抗样本不平衡。其通过执行聚类操作,使得这些类别的样本能够通过较少的代表性质心样本来进行概述,并采用这些质心替代原有的大量样本,以此来降低某一类别样本的数目,有助于实现样本的均等化。通过这种方式,clustercentroids不仅减少数据集中多数类别的样本数量,而且还维持了数据的多样性,有利于解决不平衡问题。该算法的核心步骤涉及将样本数较多的类别进行分组,以形成多个具有代表性的中心点。
40、clustercentroids算法框架如下:
41、1.多数类样本聚类:clustercentroids通过聚类方法,如k-means等,将多数类样本缩减为指定数目个“质心”(centroids),以此对多数类别的样本进行简化处理。
42、2.质心作为新样本:它将这些质心视为新的少数类别样本。这些质心样本的特征值通常是通过聚类算法计算得出的各个簇中心点的平均值。
43、3.样本替换:多数类别的原始样本将被这些质心样本所取代。
44、4.数据平衡:通过调整多数类样本数量,采用具备多数类特性的质心代替原有样本,clustercentroids算法促进了数据集的均衡化。
45、然而,由于k-means需要多次迭代更新簇中心,对于较大的数据集,计算复杂度会显著增加,导致算法执行时间较长,消耗大量内存,因此传统的k-means算法在处理大规模数据集时效率较低。此外,k-means算法在每轮迭代中都会对所有数据点和簇中心间的距离进行计算,将数据点分配至最临近的簇中心,并根据这些点的新分布更新簇心的位置。然而,该方法的迭代操作可能会影响到算法的收敛效率。特别是在处理大规模数据时,k-means算法需要多次迭代计算,直到达到收敛条件,每次迭代都需要计算所有数据点与所有簇中心的距离,这在处理大规模数据时会导致算法的效率低下。本研究采取minibatchkmeans作为欠采样过程中的聚类算法。在聚类技术中,minibatchkmeans算法作为传统kmeans的改良版本,通过使用数据的小批量子集来计算簇中心,提高了聚类过程的效率。minibatchkmeans能够有效缩短kmeans算法求解过程所需的时间,并减小内存使用量的同时,其得到的聚类效果与传统kmeans算法相比也只有轻微的差距。基于minibatchkmeans的clustercentroids算法流程如下:
46、算法流程:
47、输入:数据集d聚类数k小批量大小b最大迭代次数t
48、输出:聚类中心:{c1,c1,…,ck}
49、每个样本的聚类标签
50、i.初始化聚类中心:
51、从数据集中随机选择k个数据点作为初始聚类中心。假设初始聚类中心为
52、{c1,c1,…,ck}。
53、ii.初始化计数器:
54、初始化迭代计数器t=0,用于记录迭代次数。
55、iii.迭代过程:
56、在迭代过程中,不断调整聚类中心,使得每个聚类中心尽可能代表其簇内的数据点。
57、a.随机抽取小批量数据
58、从数据集d中随机抽取b个样本构成小批量数据集m。这样可以降低计算复杂度,提升算法的效率。
59、b.分配样本到最近的聚类中心
60、对每个小批量数据集m中的样本xi:
61、计算xi到每个聚类中心cj的距离。将xi分配到距离最近的聚类中心。
62、c.更新聚类中心
63、对于簇样本,计算所有样本的均值。
64、将聚类中心更新为上述均值,这样可以确保聚类的中心不断向簇中心靠近。
65、d.更新计数器
66、将计数器t加1,进行下一次迭代。
67、iv.终止条件:
68、当迭代次数t达到最大迭代次数t时,停止迭代,输出最终的聚类中心和每个样本的聚类标签。
69、3.3确认第一类数据的采样比例。
70、由于本研究的训练集中11类训练数据的比例为9279:710:600:454:561:252:360:88:153:454:73,显然第一类的数量远远多于其他十类,占了总样本的71%还多,而其他十类样本数量差异并没有这么显著,因此只对第一类数据进行了欠采样。
71、当采用较低的欠采样比例时,原样本丢失过多,聚类欠采样后产生的数据集表示范围会显著缩小,这使得采样后的数据集不再能够充分代表原始数据的分布情况。当采用较高的欠采样比例时,采样后的数据集可以更好的保留多数类样本的信息,仍然有较强的表现能力。但是由于原数据集类别分布极度不平衡,欠采样力度较低可能仍旧无法消除数据集中的类别失衡问题,为了保持一个适中的采样比例。通过实验,选择0.1作为最终的欠采样比例。在成功完成采样后,训练集中的11个类别,样本分布比例为:928:710:600:454:561:252:360:88:153:454:73。
72、3.3.1初始化:将第二步特征提取后得到的第一类数据划分出来,记为d。设置要进行的聚类数:k、小批量数据数:b、最大迭代次数:t、欠采样比例:0.1。
73、3.3.2从d中随机选择k个数据点作为初始聚类中心,记为{c1,c1,…,ck}。
74、3.3.3从d中随机化选择b个数据,记为m。
75、3.3.4将m中的所有数据,分别计算出与{c1,c1,…,ck}的距离。
76、3.3.5将m中的每个数据分配到该数据距离最近的聚类中心。
77、3.3.6更新{c1,c1,…,ck}
78、3.3.7反复执行t次3.3.2-3.3.6之间的操作。
79、3.3.8基于各个聚类中心内的点与质心的最小距离来选取数据,作为欠采样后的数据。选取的数据量为:9279*0.1≈928。
80、3.4将2-11类数据与采样后的第一类数据组合,组成最终的训练数据。
81、第四步:分类模型构建
82、在这一阶段中,本研究致力于通过cnn方法构建一个强大、鲁棒性高且能有效捕捉序列依赖结构的多标签分类模型。该阶段主要包含损失函数定义、激活函数选择、卷积神经网络架构设计以及模型训练验证等关键步骤。具体步骤如下:
83、4.1损失函数定义
84、损失函数在机器学习与深度学习领域内扮演着至关重要的角色。在本研究中,损失函数量化了模型预测的样本标签与实际标签的误差幅度。考虑到每个样本的标签都是四维的独热编码形式,本发明采用了一个适用于多标签分类的二进制交叉熵损失函数,以计算模型对每个样本标签预测的损失。具体计算公式如下:
85、
86、其中n表示样本数量,yi表示第i个样本的真实标签,表示模型对第i个样本的预测概率,即模型输出的值。与均方误差等损失函数相比,二元交叉熵损失对错误分类的惩罚更高,能够更好地引导模型学习正确的分类决策。
87、4.2激活函数选择
88、激活函数在神经网络中赋予非线性映射的能力,提升网络的表达和逼近功能。本发明中,考虑到relu函数简单高效,并且可以有效减缓梯度消失问题,选择relu函数作为卷积层与池化层之间的激活函数,以及全连接部分的隐藏层激活函数。在全连接的输出层中,使用sigmoid激活函数,使得输出的四维向量均介于0和1之间,表示为模型分别对四个标签的预测概率。
89、4.3卷积神经网络架构设计
90、为使模型充分考虑序列的依赖结构,本发明采用四层一维卷积层与池化层构造特征提取模块。其架构设计如下:
91、卷积层:
92、1.功能:卷积层是cnn中用于提取输入数据局部特征的核心组件。通过使用卷积核,该层能够捕捉到数据中的局部依赖关系和模式。
93、2.设计:本研究中使用的卷积核形状为(3,1),意味着每个卷积核覆盖3个时间步长,用于提取序列数据中的依赖特征。
94、3.参数:四层卷积层的参数设置分别如下:
95、第一层:conv1d(in_channels=1,out_channels=64,kernel_size=3)
96、第二层:conv1d(in_channels=64,out_channels=128,kernel_size=3)
97、第三层:conv1d(in_channels=128,out_channels=256,kernel_size=3)
98、第四层:conv1d(in_channels=256,out_channels=128,kernel_size=3)
99、池化层:
100、1.功能:池化层用于降低特征的空间维度,从而减少计算量,并使特征检测更加鲁棒。
101、2.设计:本发明采用最大池化操作,使用(2,1)大小的池化滤波器,步长为2,以实现下采样,同时保留最重要的特征信息。
102、3.效果:池化操作有助于降低过拟合风险,并使模型对输入数据中的微小变化更加鲁棒。
103、全连接层:
104、1.功能:全连接层位于模型的末端,负责将前面层所提取的特征进行整合,并进行最终的分类决策。
105、2.设计:在卷积和池化层之后,全连接层将特征展平并应用线性变换,然后通过激活函数引入非线性,以进行复杂的分类任务。
106、3.参数:
107、
108、4.输出:最终的全连接层输出一个四维向量,每个维度对应一个标签的概率预测,使用sigmoid激活函数确保输出值在0到1之间。
109、4.4模型训练与验证测试
110、一个样本通过模型输出结果为(1,4)的输出矩阵,四个位置每个位置对应一个标签,数值介于0-1之间,表示该样本包含对应标签的概率。举例:(0.9,0.2,0.3,0.4)表示(acetyllysine,crotonyllysine,methyllysine,succinyllysine)相应标签的预测概率。用于训练分类器的损失函数设置为适用于分类问题的交叉熵损失,用于测量目标和预测输出之间的差异。该模型能够充分考虑序列的依赖结构。本发明模型训练实验中采样adam优化器,学习率lr为0.001。基于五重交叉验证和五个评价指标(aiming、coverage、accuracy、absolute_true、absolute_false)选择最优模型。在独立测试集上测试模型效果,获取独立测试结果的评价指标。
111、第五步:可解释分析
112、为了深入理解的模型在预测过程中的工作原理以及预测值的生成方式,采用了shap方法来解释模型的预测过程。以下是该方法的介绍:
113、shap是一种基于博弈论的模型解释技术,其核心目标是评估各个特征对预测结果的影响力度,并为每个特征分配相应的解释性得分。shap值的计算基于shapley值理论,这是一种公平的分配方案,能够将模型的最终输出(例如预测值)合理地归因于各个特征的贡献。通过考虑所有可能的特征组合,shapley值可以精确地评估每个单独特征对模型预测值的具体影响。在解释深度学习模型时,shapley值量化了每个输入特征对模型预测性能的贡献大小。具有较高绝对值的shapley值表明对应特征对预测结果具有较大影响。通过应用shap分析,能够洞察预测结果背后的成因。在本发明中,对提取后的46个维度的特征进行了深入的解释性分析,并对模型的预测结果提供了清晰的阐释。
114、本发明的有益效果:
115、1.现有的发明大多局限于单一类型的修饰,忽略了不同ptms之间的相互影响。本发明建立了一个多标签预测工具,可以直接用于预测多种赖氨酸修饰位点。解决了之前发明没有考虑到的串扰问题。
116、2.基于minibatchkmeans的clustercentroids欠采样算法能有效解决样本不平衡问题,提高模型对样本数较少类别的泛化能力。且在减小内存使用量的同时,得到的效果与传统算法相差无几。
117、3.构造的卷积神经网络架构能考虑序列元素之间的依赖性,充分捕获序列中的信息,加强了模型对序列信息的深入理解和有效利用。
118、4.基于shap值的模型可解释性分析表明,本发明构建的预测模型是有效的,增强了模型的透明度和可信度。
本文地址:https://www.jishuxx.com/zhuanli/20240929/310278.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表