一种面向边界敏感数据的旅游场景槽位填充方法
- 国知局
- 2024-10-09 16:06:56
本发明属于自然语言处理,具体涉及一种面向边界敏感数据的旅游场景槽位填充方法。
背景技术:
1、现有的管道式任务型对话系统通常可分为自然语言理解、对话状态跟踪、对话策略和自然语言生成模块。槽位填充(slot filling)是自然语言理解模块下的关键任务之一,旨在于标记并识别句中有意义的部分,将其和事先定好的标签联系起来。通过槽位填充,可以将文本转化为结构化数据,便于进行下一步的处理。
2、通常情况下,槽位填充被视为序列标注任务,即对文本中的每个词元进行一次多分类。现有的方法使用序列标注范式解决槽位填充问题,使用准确率和召回率等指标进行评估,达到了很高的性能。然而,现有模型并没有很好地解决槽位边界不清晰的问题。在旅游场景下,一些重要信息,如时间、电话号、地名等,属于边界敏感数据。这类数据的存在导致模型准确率之类的表面指标虽然很高,但是实际抽取表现往往不尽人意。例如,假设正确预测的槽值对为(地址,中国上海)、(电话号码,12345678901),而现有模型预测的槽值对为(地址,中国)、(电话号码,1234567890),由于边界模糊性,抽取得到的关键信息存在偏差,因此实际抽取表现非常不佳。由此也可以得出,精确率这种传统评估指标很多时候并不能很好地反映实际抽取质量。
3、现有的尝试解决槽位边界模糊问题的方法大都聚焦于模型层面,通过结合位置编码等信息试图从一定程度上解决这种问题。然而这些方法可能伴随着模型复杂、可解释性低等问题。同时大多方法使用传统深度学习指标进行评估,仅仅说明模型在序列标注任务上有较好性能,并不能说明最终抽取质量高,无法保证那些边界敏感数据能被精准地抽取。
4、综上所述,现有方法存在以下问题。
5、1、旅游场景下,现有槽位填充方法没有真正解决槽位边界不清晰的问题,致使实际抽取表现不佳,槽值对预测结果不准确,同时还伴随着模型复杂和可解释性低等问题。
6、2、现有方法所使用的评估指标不足以反映最终抽取质量:现有方法使用准确率、召回率等指标只聚焦于这个深度学习任务本身,并没有关注最终抽取结果质量,忽略了结果完整性、精确性,致使旅游场景下抽取得到的关键信息存在偏差。
技术实现思路
1、为了解决上述问题,本发明提出了一种面向边界敏感数据的旅游场景槽位填充方法,设计了基于一致性引导集成的旅游场景槽位填充架构cgssf(consistency-guidedstacking for slot filling),该架构确保在不使模型变得过分复杂的同时,大幅降低了边界模糊出现的可能性,显著改善了旅游场景任务型对话中的槽位填充实际表现,提升了最终抽取质量。除此之外,本发明还提出了一种基于差集的相似性度量指标dcsi(difference coefficient similarity index),可以更好地检验模型抽取出的槽值对质量,更真实地反映实际抽取效果。
2、本发明的技术方案如下:
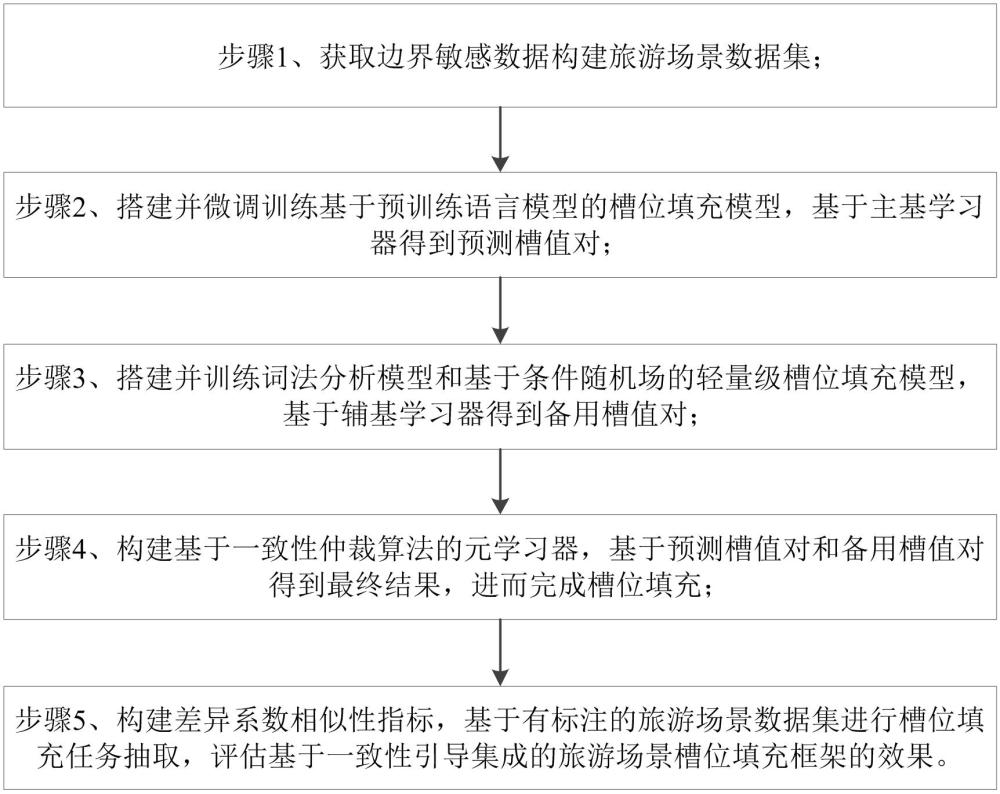
3、一种面向边界敏感数据的旅游场景槽位填充方法,构建基于一致性引导集成的旅游场景槽位填充框架,框架包括主基学习器、辅基学习器和元学习器,主基学习器采用预训练语言模型的槽位填充模型,辅基学习器采用词法分析模型和基于条件随机场的轻量级槽位填充模型,元学习器采用一致性仲裁算法;槽位填充方法包括如下步骤:
4、步骤1、获取边界敏感数据构建旅游场景数据集;
5、步骤2、搭建并微调训练基于预训练语言模型的槽位填充模型,基于主基学习器得到预测槽值对;
6、步骤3、搭建并训练词法分析模型和基于条件随机场的轻量级槽位填充模型,基于辅基学习器得到备用槽值对;
7、步骤4、构建基于一致性仲裁算法的元学习器,基于预测槽值对和备用槽值对得到最终结果,进而完成槽位填充;
8、步骤5、构建差异系数相似性指标,基于有标注的旅游场景数据集进行槽位填充任务抽取,评估基于一致性引导集成的旅游场景槽位填充框架的效果。
9、进一步地,所述步骤1中,构建的旅游场景数据集为,数据集为对话形式,数据集中具体包括时间、电话号、地名;旅游场景数据集中包含个样本,每个样本包含若干条对话,整个数据集中用于序列标注的槽位类别数有种。
10、进一步地,所述步骤2的具体过程为:
11、步骤2.1、构建主基学习器网络结构,主基学习器的工作过程为:
12、首先,使用预训练的类bert编码器对旅游场景数据进行编码:
13、(1);
14、其中,模型的隐层向量长度为,词元序列长度为,表示句中每个词元的表示向量,表示全局池化表示向量,和分别表示当前对话和历史对话对应的句子,表示句中的第个词元;为编码器;
15、然后,按照如下规则进行张量变换,实现特征融合:
16、 (2);
17、其中,为更新操作;为重复指定维度张量操作;为维度扩充张量操作;为拼接张量操作;
18、最后,通过前馈神经网络得到序列标注预测结果;前馈神经网络包括线性层、分类层和激活函数层,具体计算公式如下:
19、(3);
20、其中,为通过前馈神经网络得到的序列标注预测结果;和分别表示线性层的权重和偏执;为relu激活函数;和分别表示分类层的权重和偏执;
21、将通过前馈神经网络得到的序列标注预测结果转为字典形式,得到预测槽值对字典;字典的键表示槽位,每个键对应的值表示包含若干槽值的集合;
22、步骤2.2、使用代价敏感学习策略对基于预训练语言模型的槽位填充模型进行微调训练;具体过程为:
23、首先,统计数据集中每个槽位类别出现次数,定义表示记录所有槽位类别出现次数的向量;槽位类别出现次数的计算公式如下:
24、 (4);
25、其中,表示槽位类别序号;表示槽位类别的出现次数;为旅游场景数据集中的样本;为槽位类别出现次数变量;表示满足在中出现了次的条件时取值为1,否则取值为零;
26、然后,计算每个槽位类别的类别权重,定义表示记录所有槽位类别权重的类别权重向量;槽位类别类别权重的计算公式如下:
27、(5);
28、其中,表示向量所有值的和;表示槽位类别的类别权重;为实数;
29、根据类别权重向量,加权得出第一损失函数,并使用梯度下降方法进行优化:
30、(6);
31、其中,为交叉熵损失函数;表示第一损失函数中独热编码形式的标签。
32、进一步地,所述步骤3的具体过程为:
33、步骤3.1、构建基于半监督增量学习的词法分析模型,采用词法分析模型完成分词和词性标注;具体过程为:
34、获取一个预训练好的词法分析模型,首先,对旅游场景数据集逐句使用词法分析模型进行细粒度中文分词,得到若干词段序列;接下来对于词段序列中非空槽位部分进行标注,得到了若干条部分标注的数据;然后,使用预训练好的词法分析模型进行预测,完成词性标注,未标注的部分使用本轮生成的标注结果,其余部分一律使用第一轮标注的结果;通过两轮标注,得到了一个完全标注好的旅游场景数据集;最后,使用完全标注好的旅游场景数据集增量训练模型;
35、步骤3.2、搭建并训练基于条件随机场的轻量级槽位填充模型;基于条件随机场的轻量级槽位填充模型的工作过程为:
36、使用预训练静态词向量表获取词段序列中每个词的词义向量,同时使用word2vec方法获取每种词性对应的词性向量,并匹配给序列中的每个词性;将两者拼接,得到融合词义和词性特征的向量表示:
37、 (7);
38、其中,和分别表示词段序列对应的词义张量和词性张量,表示词粒度序列长度,表示词义向量维度,表示词性向量维度;表示拼接后的向量表示结果;
39、使用双向门控循环单元处理拼接后的向量表示结果:
40、 (8);
41、其中,为处理后的张量,为隐层维度大小;表示构建出的双向门控单元模型;
42、使用条件随机场完成最终分类并得到结果:
43、(9);
44、其中,为通过条件随机场得到的序列标注预测结果;表示构建出的条件随机场模型;
45、将通过条件随机场得到的序列标注预测结果转为字典形式,得到备用槽值对字典;
46、最后,使用交叉熵计算第二损失函数,对轻量级槽位填充模型进行优化:
47、(10);
48、其中,表示第二损失函数中独热编码形式的标签。
49、进一步地,所述步骤4中,定义相似度计算公式如下:
50、(11);
51、其中,表示计算和两个槽值字符串的相似度得分;表示求取所有参数的最大值;表示求和两个槽值字符串的最长公共子串;表示求长度;
52、一致性仲裁算法进行仲裁的具体过程为:对于主基学习器输出的预测槽值对字典中出现的每个槽位,检查辅基学习器输出的备用槽值对字典中是否有对应结果;如果有对应槽位且槽值结果一致,则无需额外处理即可加入最终仲裁结果中;如果有对应槽位但槽值结果不一致,则基于公式(11)进行相似度计算,预先定义一个相似度阈值,如果相似度大于阈值则调整槽值边界以修正槽值结果,修正后加入最终仲裁结果中;如果没有对应槽位,则取出当前槽位对应的槽值,从辅基学习器的所有槽值中寻找和取出与当前槽位对应的槽值最相似的槽值,将取出的槽值和当前槽位对应的槽值基于公式(11)进行相似度计算,如果相似度大于阈值则调整槽值边界以修正槽值结果,修正后加入最终仲裁结果中;最后根据最终仲裁结果完成槽位填充。
53、进一步地,所述步骤5中,设计差异系数相似性指标,公式为:
54、 (12);
55、其中,为差异系数相似性指标;为预测值集合;为标签集合;表示满足的条件时取值为1,否则取值为零;当恒有时,差异系数相似性指标简化为:
56、(13);
57、除公式(13)这种形式外,差异系数相似性指标还有另一种计算方法,两种方法等价;在使用时选择最易于实现的一种;差异系数相似性指标的另一种计算方法如下:
58、 (14)。
59、进一步地,所述步骤5中,将槽位填充任务抽取得到的槽值对表示为“键—值集合”形式,即用键值字典形式数据结构存储;规定预测和标签的槽值对字典分别为和,预测和标签中字典键的集合分别为、,令:
60、(15);
61、其中,为预测和标签中字典键的集合的交集;
62、则有:
63、(16);
64、其中, 为和通过差异系数相似性指标求出的相似度得分;为槽位类别的预测槽值对字典;为槽位类别的标签槽值对字典;
65、使用公式(16)对槽位填充任务抽取结果进行评估,如果满足预期则将搭建好的基于一致性引导集成的旅游场景槽位填充框架部署并投入使用,如果没有满足预期则重复步骤2-步骤4重新训练直至满足预期为止。
66、本发明所带来的有益技术效果如下。
67、1、有助于提高槽位填充的准确性和完整性。该发明通过设计一致性引导集成架构cgssf,显著降低了槽位边界模糊的可能性,使得在旅游场景下的任务型对话系统能够更准确地提取出关键信息。与传统方法相比,该方法能更有效地识别和标记完整性敏感数据,如时间、地名、电话号码等,从而提高了槽位填充的准确性和信息完整性。
68、2、有助于提升槽位填充评估质量。该发明提出的dcsi(difference coefficientsimilarity index)为模型的实际抽取质量提供了一种新的度量方法。与传统的准确率、召回率等指标相比,dcsi能更真实地反映槽值对的提取效果,关注结果的完整性和精确性。这种新的评估方式不仅能够提供更高效的反馈以指导模型改进,还能帮助在旅游场景下更准确地识别和处理关键信息,提高任务型对话系统的实际应用效果。
本文地址:https://www.jishuxx.com/zhuanli/20240929/311686.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。