一种融合文本语义特征的低资源情感语音合成装置及方法
- 国知局
- 2024-10-09 15:29:21
本发明涉及一种融合文本语义特征的低资源情感语音合成装置及方法,属于自然语言处理和语音合成。
背景技术:
1、随着人工智能技术的飞速发展,语音合成(text-to-speech,tts)技术已经取得了显著的进步,并在多个领域得到了广泛应用。传统的语音合成系统主要关注于从文本中生成清晰、自然的语音,然而,随着情感计算在人机交互中的重要性日益凸显,如何生成具有情感色彩的语音成为了当前研究的热点之一。情感语音合成(emotional speechsynthesis)作为人机交互和智能语音应用领域的重要研究方向,吸引了广泛的关注。情感语音合成旨在使合成的语音具有逼真的情感表达,从而增强语音交互的自然度和情感传递的效果。然而,传统的情感语音合成方法往往依赖于大规模的训练数据,并且在低资源情况下面临着困难和挑战。在实际应用场景中,获得大规模标注的情感语音合成数据集是一项昂贵和耗时的任务。如何在数据有限的情况下实现高质量的情感语音合成仍然是一个具有挑战性的问题。
技术实现思路
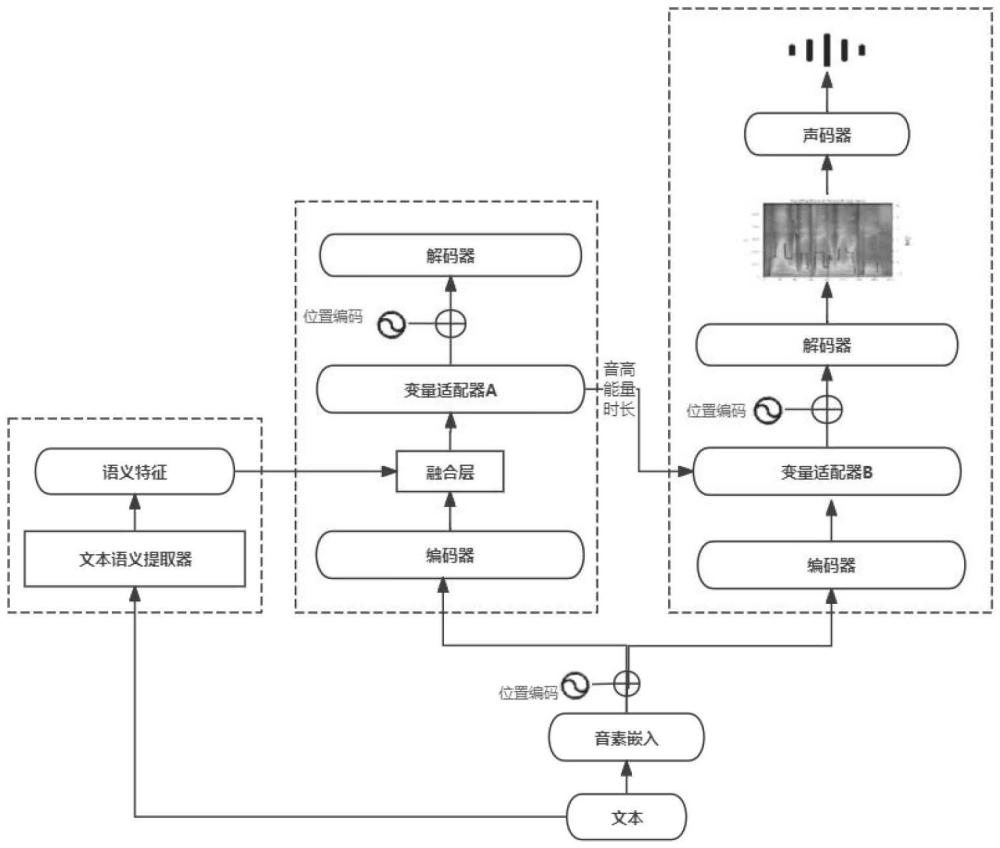
1、为了克服现有研究的不足,本发明提供了一种融合文本语义特征的低资源情感语音合成装置及方法,通过从文本中提取情感特征,并将其融合到以fastspeech2为骨干框架的语音合成模型中,实现蕴含情感表达的语音合成。为了应对低资源情况下的挑战,采用了一种基于少量训练数据的策略,将采用少量情感音频训练出的音高预测器、能量预测器和时长预测器迁移至采用fastspeech2预训练完成的不含情感的合成模型中,从而可以生成质量高的具有情感表达的语音。
2、一种融合文本语义特征的低资源情感语音合成装置,包括:
3、变量提取模块:用于从训练数据集中提取音频的音高、能量、时长、语谱图的真实值,用作在训练过程计算预测值与真实值之间的损失;
4、输入模块:在训练模型的过程中用于将文本分别输入至语义提取模块、文本嵌入、合成模块、将提取出的音高、能量、时长、语谱图输入到合成模块,在采用训练的模型进行训练时,仅需要将文本分别输入至语义提取模块、文本嵌入模块;
5、语义提取模块:用于从文本中提取出文本语义特征cemotion;
6、语义提取模块具体用于:
7、将文本输入至文本语义提取器中;
8、提取文本的语义特征;
9、对语义特征进行线性变换将特征维度由768维转换为256维得到cemotion,与文本编码器的输出维度保持一致,从而使两个特征可以融合;
10、文本嵌入模块:用于将文本转成音素嵌入序列,并通过编码器获得文本编码特征ctext;
11、融合模块:用于将文本语义特征cemotion和文本编码特征ctext采用加法融合策略获取融合特征序列cfusion;
12、融合模块具体用于:
13、将文本语义特征cemotion的序列长度与文本嵌入获得文本编码特征ctext的序列长度进行比较,若长度不一致则实施零填充策略,处理后两者在序列长度上相等;
14、将处理后的文本编码特征ctext与文本语义特征cemotion采用加法策略进行融合,获得融合特征序列cfusion;
15、情感预测模块:通过融合特征序列cfusion预测时长pduration、音高cpitch、能量cenergy,并将预测出的cpitch,cenergy嵌入到cfusion中得到cfpe,并根据pduration的值在每个音素上进行复制拼接得到cfped;
16、情感预测模块具体用于:
17、将融合特征序列输入至时长预测器中进行时长预测pduration;
18、将融合特征序列输入至音高预测器中,获得音高嵌入cpitch;
19、音高嵌入同融合特征序列相加;
20、cfp=cfusion+cpitch
21、并将结果cfp输入至能量预测器中,获得能量嵌入cenergy;
22、能量嵌入与cfp相加得到cfpe;
23、cfpe=cfp+cenergy
24、将嵌入了音高和能量的特征序列cfpe根据pduration的值在每个音素上进行复制拼接得到cfped;用来控制在音频中每个音素的时长;
25、合成模块:用于将cfped输入到解码器中合成语谱图,将语谱图输入到声码器中合成具有情感的音频。
26、一种融合文本语义特征的低资源情感语音合成方法,包括以下步骤:
27、步骤一、制作语音数据集:情感语音数据集总时长不少于10分钟,数据集包含音频文件和文本文件,文本文件中包含音频文件路径、说话人和该路径下音频文件对应的文字内容;
28、步骤二、构建文本语义提取器:采用基于预训练的roberta模型进行微调训练,从而得到可以有效识别neutral、happy、sad、angry、surprise5类情感的英文文本情感分类模型,从该模型中可以获得与情绪相关的语义特征;
29、步骤三、对数据集进行预处理:对于步骤一中制作的数据集进行处理,对于数据集中的音频文件,提取每条音频中的音高、能量、时长、语谱图,对与数据集中的文本文件提取文本中语义特征;
30、步骤四、构建低资源情感语音合成模型:低资源情感语音合成模型包括文本语义提取器,编码器、变量适配器、解码器,训练该模型的目的是可以通过文本和文本的语义特征训练变量适配器中包含的时长、音高、能量预测器,从而获取到与文本语义特征对应的时长、音高、能量;
31、步骤五、进行语音合成:将用户输入的文本输入文本语义提取器提取文本中的语义特征,将文本转成音素序列输入到不含情感的语音合成模型的编码器中生成256维的文本嵌入特征,语义特征与文本嵌入特征进行融合后输入至变量适配器中加入根据步骤四低资源情感语音合成模型预测出的音高,能量和时长,最后由解码器生成语谱图,由声码器输出合成的音频。
32、所述步骤二具体包括:
33、s2.1:将文本输入至文本语义提取器中;
34、s2.2:提取文本的语义特征;
35、s2.3:对语义特征进行线性变换将特征维度由768维转换为256维得到cemotion,与文本编码器的输出维度保持一致,从而使两个特征可以融合。
36、所述步骤三具体包括:
37、s3.1:将音频文件统一为采样率为22050hz的wav格式的音频文件,统一采样率和格式可以提高之后提取音频中的音高、能量、时长和语谱图的效率;
38、s3.2:对数据集中的每一条音频都进行提取音高、能量、时长和语谱图的操作,并将提取出的信息每一条都保存成为单独的数组文件,该步骤在之后训练低资源情感语音合成模型时计算预测值与实际值之间的loss,进而使模型在迭代训练过程中不断优化模型。
39、所述步骤四具体包括:
40、s4.1:将文本输入至编码器中获得文本嵌入特征ctext;
41、s4.2:将步骤三获取的对应文本内容的语义特征的序列长度与文本嵌入的序列长度进行比较,若长度不一致则实施零填充策略;
42、s4.3:将处理后的文本嵌入特征与语义特征进行融合,获得融合特征序列cfusion;
43、s4.4:将融合特征序列输入至变量适配器中进行音高、能量嵌入,并对合成的音频时长进行预测。
44、所述步骤五具体包括:
45、s5.1:将文本输入至文本语义提取器中,获取文本的语义特征cemotion;
46、s5.2:加载训练好的低资源情感语音合成模型memotion;
47、s5.3:将文本输入至memotion的编码器中获取文本嵌入特征ctext;
48、s5.4:对cemotion与ctext的序列长度实施零填充策略;
49、s5.5:将处理后的文本嵌入特征ctext与语义特征cemotion进行融合,获得融合特征序列cfusion;
50、s5.6:将cfusion输入至memotion的变量适配器中预测时长pduration、音高cpitch、能量cenergy;
51、s5.7:加载普通无情感语音合成模型mnormal;
52、s5.8:将文本输入至mnormal的编码器中,获得文本嵌入特征etext;
53、s5.9:将s5.6获取的时长pduration、音高cpitch、能量cenergy嵌入到etext中获得edpe,时长、音高、能量由变量适配器a提供;
54、s5.10:将edpe输入至解码器中获得语谱图;
55、s5.11:将语谱图输入到声码器合成音频,此时合成的音频既保留了mnormal合成音频的质量,同时又有了根据memotion预测出的时长pduration、音高cpitch、能量cenergy而具有的情感。
56、所述s4.4具体包括:
57、s4.4.1:融合特征序列输入至时长预测器中进行时长预测pduration;
58、s4.4.2:融合特征序列输入至音高预测器中,获得音高嵌入cpitch;
59、s4.4.3:音高嵌入同融合特征序列相加;
60、cfp=cfusion+cpitch
61、并将结果cfp输入至能量预测器中,获得能量嵌入cenergy;
62、s4.4.4:能量嵌入与cfp相加得到cfpe;
63、cfpe=cfp+cenergy
64、s4.4.5:将嵌入了音高和能量的特征序列cfpe根据pduration的值在每个音素上进行复制拼接得到cfped,用来控制在音频中每个音素的时长;
65、s4.4.6:将cfped输入至解码器,通过解码器合成语谱图;
66、s4.4.7:计算预测出的时长、音高cpitch、能量cenergy和语谱图与在步骤二中获取的时长、音高、能量、语谱图之间的损失,迭代训练不断降低损失,保存模型为memotion。
67、与现有技术相比,本发明的有益效果在于:
68、本发明提出一种融合文本语义特征的低资源情感语音合成装置及方法,从文本中提取语义特征,训练出的合成模型可以学习到不同文本所蕴含的不同的语义特征,进而合成具有不同情感的音频。
69、本发明采用少量情感语音数据集训练语音合成模型,主要训练与音频情感有关的时长、音高、能量,这三个参数不同的组合可以使音频具有不同的情感表达,将这三个参数迁移至不含情感的语音合成模型中,可以在保留原有模型合成音频质量的基础上使合成音频具有情感表达。采用少量情感语音数据集降低了数据获取的难度,对预测的时长、音高、能量进行迁移达到合成高质量情感语音的目的。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308906.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表