基于大数据分析的污水处理异常检测与预警系统的制作方法
- 国知局
- 2024-10-09 15:39:23
本发明涉及数据处理,尤其涉及一种基于大数据分析的污水处理异常检测与预警系统。
背景技术:
1、目前污水处理异常检测与预警在现代污水处理领域起着越来越重要的作用,大数据的应用使得处理大量实时数据和历史数据变得可能,能够实时监测污水处理的各种参数,如水质、流量、温度等,并进行复杂的数据分析、模式识别和异常检测,一旦检测到异常情况,能够及时发出预警,帮助操作人员及时采取措施避免进一步问题的发生。
2、现有技术中,通过采集污水处理过程中的各种监测数据,并使用knn算法对各种监测数据进行异常数据检测,从而实现污水处理异常预警的目的。
3、但是,传统方式下在使用knn算法进行异常数据检测时,通常是计算每个点到其k个最近邻点之间的距离之和或者平均距离,同时设定一个距离阈值,距离之和或者平均距离大于该距离阈值的点被认为是异常点,但实际过程中,由于污水处理中数据类型和数据量较大,所以一个数据点的k个最近邻点中可能存在极少数最近邻点与该数据点距离较远,或者该点的最近邻点中存在一个或多个点对于整体数据点分布离散程度较大,增大了数据点与k个最近邻点的距离之和或者平均距离,且超过距离阈值,这种情况下会对数据点做出错误判断,将数据点误认为异常点,导致检测的准确性降低。
4、因此,如何提高利用knn算法进行污水处理异常预警的准确性和鲁棒性成为亟需解决的问题。
技术实现思路
1、有鉴于此,本发明实施例提供了一种基于大数据分析的污水处理异常检测与预警系统,以解决如何提高利用knn算法进行污水处理异常预警的准确性和鲁棒性的问题。
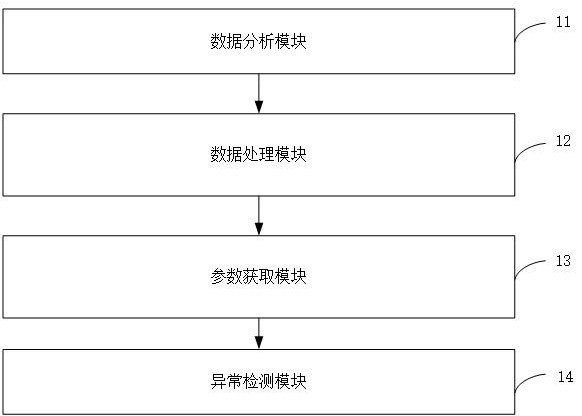
2、本发明实施例中提供了一种基于大数据分析的污水处理异常检测与预警系统,该系统包括:
3、数据分析模块,用于分别获取预设时段内污水处理时的至少两种数据指标,对应得到每种数据指标的数据序列,根据所述数据序列之间的相关性,将所有数据指标的数据序列划分为至少一个类别;
4、数据处理模块,用于针对任一类别,对所述类别中的所有数据指标进行归一化处理,得到归一化数据指标,构建所有归一化数据指标的散点图,在利用knn算法对所述散点图中的所有数据点进行分类时,获取所述knn算法的初始k值,根据所述初始k值,获取所述散点图中的每个数据点的异常程度;
5、参数获取模块,用于根据所述散点图中所有数据点的异常程度,获取异常点,根据所述异常点和所述初始k值,自适应获取所述散点图中的每个数据点的最佳k值;
6、异常检测模块,用于根据所述散点图中每个数据点的最佳k值,利用所述knn算法对所述散点图中的所有数据点进行分类,得到所述类别对应的分类结果,根据每个所述类别对应的分类结果进行污水处理的异常预警。
7、进一步的,所述数据分析模块中根据所述数据序列之间的相关性,将所有数据指标的数据序列划分为至少一个类别,包括:
8、针对任意两个数据序列,计算所述两个数据序列之间的斯皮尔曼相关系数,将所述斯皮尔曼相关系数的绝对值作为所述两个数据序列的趋势变化特征值;
9、若所述趋势变化特征值在预设范围内,则将所述两个数据序列分为同一类别,根据每两个所述数据序列之间的趋势变化特征值将所有数据指标的数据序列划分为至少一个类别。
10、进一步的,所述数据处理模块中根据所述初始k值,获取所述散点图中的每个数据点的异常程度,包括:
11、针对所述散点图中的任一数据点,分别计算所述数据点与每个其他数据点之间的欧式距离,对所有欧式距离进行从小到大排序,取排序后的欧式距离中的前k个欧式距离对应的其他数据点作为所述数据点的最近邻数据点;
12、根据每个所述最近邻数据点的分布特征,获取每个所述最近邻数据点的偏离系数,利用每个所述最近邻数据点的偏离系数,对所述数据点与每个所述最近邻数据点之间的欧式距离进行优化,得到所述数据点与每个所述最近邻数据点之间的特征距离;
13、根据所述数据点与每个所述最近邻数据点之间的特征距离和欧式距离,获取所述数据点的异常程度。
14、进一步的,所述数据处理模块中根据每个所述最近邻数据点的分布特征,获取每个所述最近邻数据点的偏离系数,包括:
15、将所述散点图中的所有数据点进行曲线拟合得到数据趋势分布拟合曲线;
16、针对任一最近邻数据点,获取所述数据点与所述最近邻数据点所在的直线,得到所述直线与所述数据趋势分布拟合曲线的交点,获取所述数据趋势分布拟合曲线在所述交点处的切线,获取所述切线与所述直线之间的最小角度值的正弦值,将所述正弦值与常数1相加得到所述最近邻数据点的偏离系数。
17、进一步的,所述数据处理模块中利用每个所述最近邻数据点的偏离系数,对所述数据点与每个所述最近邻数据点之间的欧式距离进行优化,得到所述数据点与每个所述最近邻数据点之间的特征距离,包括:
18、针对所述数据点与任一最近邻数据点之间的欧式距离,将所述欧式距离和所述最近邻数据点的偏离系数之间的乘积作为所述数据点与所述最近邻数据点之间的特征距离。
19、进一步的,所述数据处理模块中根据所述数据点与每个所述最近邻数据点之间的特征距离和欧式距离,获取所述数据点的异常程度,包括:
20、获取所述数据点与每个所述最近邻数据点之间的特征距离中的最大值,将所述数据点与每个所述最近邻数据点之间的特征距离进行累加得到累加结果,计算所述最大值与所述累加结果的比值作为第一变量,将所述第一变量的双曲正切函数值作为第一函数值;
21、计算所述数据点与每个所述最近邻数据点之间的欧式距离的平均值得到平均距离,计算所述数据点与每个所述最近邻数据点之间的欧式距离的标准差,将所述标准差与所述平均距离的比值作为第二变量,将所述第二变量的双曲正切函数值作为第二函数值;
22、将所述第一函数值和所述第二函数值进行加权求和得到所述数据点的异常程度。
23、进一步的,所述参数获取模块中根据所述散点图中所有数据点的异常程度,获取异常点,包括:
24、针对任一异常程度,若所述异常程度在预设异常程度范围内,则将所述异常程度对应的数据点标记为异常点。
25、进一步的,所述参数获取模块中根据所述异常点和所述初始k值,自适应获取所述散点图中的每个数据点的最佳k值,包括:
26、针对所述散点图中的任一异常点,利用预设的调整值对所述初始k值进行减小调整,得到调整后的k值,根据所述调整后的k值,获取所述异常点的异常程度,若所述异常点的异常程度在所述预设异常程度范围内,则利用所述调整值对所述调整后的k值继续进行减小调整,得到新调整k值,将所述新调整k值作为所述调整后的k值,重复所述异常点的异常程度的获取步骤,直至所述异常点的异常程度不在所述预设异常程度范围内,则将对应的调整后的k值作为所述异常点的最佳k值。
27、将所述初始k值作为所述散点图中的每个非异常点的最佳k值。
28、本发明实施例与现有技术相比存在的有益效果是:
29、本发明提供了一种基于大数据分析的污水处理异常检测与预警系统,包括数据分析模块,用于分别获取预设时段内污水处理时的至少两种数据指标,对应得到每种数据指标的数据序列,根据所述数据序列之间的相关性,将所有数据指标的数据序列划分为至少一个类别;数据处理模块,用于针对任一类别,对所述类别中的所有数据指标进行归一化处理,得到归一化数据指标,构建所有归一化数据指标的散点图,在利用knn算法对所述散点图中的所有数据点进行分类时,获取所述knn算法的初始k值,根据所述初始k值,获取所述散点图中的每个数据点的异常程度;参数获取模块,用于根据所述散点图中所有数据点的异常程度,获取异常点,根据所述异常点和所述初始k值,自适应获取所述散点图中的每个数据点的最佳k值;异常检测模块,用于根据所述散点图中每个数据点的最佳k值,利用所述knn算法对所述散点图中的所有数据点进行分类,得到所述类别对应的分类结果,根据每个所述类别对应的分类结果进行污水处理的异常预警。其中,由于污水处理异常检测中包含的数据类型较多且数据量大,如果直接构建散点图会使得散点图非常拥挤,难以分辨每种数据指标的分布,会掩盖掉数据之间存在的相关性或模式,所以首先对每种数据指标的数据序列进行分类,然后根据分类结果构建散点图,由于污水处理异常检测过程中包含大量的实时数据和历史数据,k个最近邻数据点中不乏会出现一些与样本点的距离较远的数据偏离点,这些数据偏离点会在knn算法运行过程中产生极大的干扰,导致样本点被误认为异常点,所以根据散点图中各个数据点的分布特征,获取各个数据点的异常程度,根据异常程度自适应获取最佳k值,通过减小k值排除数据偏离点的干扰,在使用knn算法对污水处理异常检测时,选取最佳k值对数据进行分析和识别,排除了数据偏离点在knn算法运行过程中产生的干扰,提高对数据点检测的准确率。
本文地址:https://www.jishuxx.com/zhuanli/20241009/309493.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。