一种结合yolov8与UIE模型用于军事领域的图文多模态实体关系抽取的方法
- 国知局
- 2024-10-15 09:30:22
本发明涉及自然语言处理领域,特别是涉及多模态图文信息实体关系抽取的一种方法。
背景技术:
1、自然语言处理(nlp)是计算机科学和人工智能领域的一个重要分支,旨在让计算机理解和处理人类语言。关系抽取(relation extraction,re)是nlp中的一个重要任务,旨在从文本中自动识别实体之间的关系。同时,自然语言处理与计算机视觉也有着密不可分的联系。
2、关系抽取(re)是构建知识图的一个基本过程,其任务内容是识别句子中给定的两个实体之间的语义关系。而多模态关系提取(mre)是一个用视觉线索识别文本关系的任务。视觉信息作为人类重要的获取信息渠道,人类获取的信息超过八成来自视觉信息。而视觉传感器作为辅助人类获取视觉信息的工具,在人类的生产生活中占据了重要的地位。单一得从文本中获得信息具有一定得局限性。视觉内容有助于相对于纯文本基线更精确地识别关系。因此,图文结合用于实体关系抽取的方法因运而生。
3、而近年来深度学习在计算机视觉和自然语言处理领域的飞速发展,其中目标识别与信息抽取都是其中的重要领域。单独只用文本或者图像其中一者的来源得到的效果较为单一,难以满足智能化时代的需求。
技术实现思路
1、本发明提供一种面向军事领域,结合目标检测与文本信息抽取的方法,能够精准识别指定的飞机类型,输出标准的三元组形式。
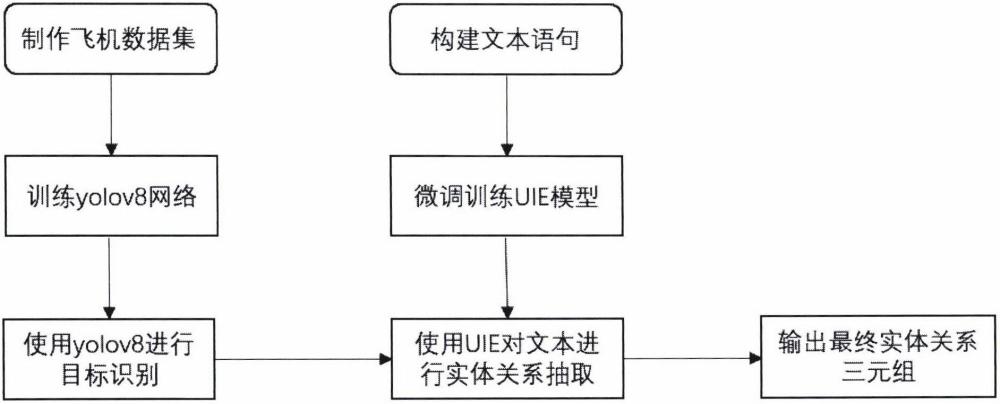
2、本发明所采用的技术方案是:结合yolov8与uie模型用于军事领域的图文多模态实体关系抽取的方法,包括以下步骤:
3、步骤1,在可以查询到的国内外官方军事领域装备网站或官方军事力量网站上查找飞机或飞行器的图片,构建图像数据集,使用yolov8检测图像识别飞机的具体型号;
4、步骤2,制定实体间关系的schema,并且根据schema构建文本关系数据集;
5、步骤3,使用文本数据集对uie信息抽取模型进行微调训练;
6、步骤4,使用微调后的uie对输入的文本进行抽取,并且结合yolov8得到的结果输出最终的实体关系三元组。
7、进一步地,步骤1中,首先制定了46种不同的飞机类型,在国内外官方的军事领域装备网站或官方军事力量网站(https://www.seaforces.org/)上进行选取需要的飞机图片进行爬取:
8、根据爬取得到的飞机图片,经过筛选,剔除质量不好的图片,构建数据集,划分成训练集,验证集,测试集,最终得到的训练集图片共10472张,验证集1164张,测试集1293张;
9、使用yolov8对飞机图片进行训练,使用nvidia geforce rtx 3070 ti的gpu进行加速,cuda版本设置为11.3,软件环境设置为python 3.8,pytorch版本设置为1.9.0+cu111,torchaucio版本设置为0.9.0,torchvision版本设置为0.10.0+cu111,加载yolov8n.pt的预训练模型文件,输入图片大小为640*640,批处理设置为4,训练轮数分别设置为100轮,200轮,300轮,学习率设置为0.001。
10、使用一些测试图片对100轮,200轮,300轮的结果进行对比,发现300轮中对于飞机图片的型号识别的效果最佳。
11、在测试的图片中,若出现较多飞机的场景,例如一艘航空母舰搭载了许多舰载机的情况下,由于识别对象目标较多,远距离拍摄目标画面较小导致的画面不够清晰,或者是由于周围的飞机及其他设备装置遮挡的原因,对于飞机型号的识别率会有所下降。对于识别飞机目标较少甚至只有单个目标的情况下,由于需要识别的目标数较少并且是被的画面足够清晰,对于飞机目标型号的识别率可以超过0.95甚至逼近1。
12、进一步地,步骤2中,对于实体之间的关系,围绕“飞机”这一实体,制定一个schema,指定schema的过程需要考虑相近词义的词语,需要进行筛选剔除,并且最终的关系词语需要符合实际情景。
13、对于这10种不同的与飞机有关的实体关系三元组,选择从军事网站和新闻网站上搜集相关新闻文本,加上人工编写,形成一个能够体现schema中规定的实体关系三元组的文本语句数据集,用于uie模型。
14、进一步地,步骤3中,uie模型是通用信息抽取统一框架,可用于不同任务中的信息抽取。在军事领域中,当输入的文本并未提及具体型号,但相对应的图像中可以识别出飞机的型号时,考虑使用视觉信息补充单一的文本信息作为信息的补充完善。
15、uie模型可以抽取通用的文本信息,不同任务中具备良好的迁移和泛化能力,基于ernie 3.0知识增强预训练模型,训练并开源了首个中文通用信息抽取模型uie。
16、uie模型采用默认的uie-base模型,结构选择12-layers,768-hidden,12-heads,语言模式设置为“中文”。应用场景为“面向文本场景的抽取式模型,支持中文”。
17、给定预训练好的uie模型,通过模型微调快速将其适应不同的ie任务和设置。给定标记的语料库dtask={(s,x,y)},使用teacher-forcing交叉熵损失对uie模型进行微调:
18、
19、使用专门的doccano标注工具对先前的文本数据集进行头尾实体以及关系的标注。标注准则按照先前指定的schema所规定的10种关系类型进行标注,共120条文本语句。
20、将doccano工具标注好的数据文本导出,其文本格式为admin.jsonl,放在./data目录下。
21、调用uie模型,输入规定好的schema,使用的task-path设定为uie-base,输入实例测试文本,得到抽取得的实体三元组关系结果。
22、使用单卡微调的命令,学习率learning_rate设置为1e-5,批次大小设置为4,序列的最大长度设置为512,轮数设置为4,模型选定为uie-base,随机种子seed为1000--logging_steps设置为10,合理步数设置为10,最终保存的训练文件名称为checkpoint-1880。
23、调用uie模型,输入规定好的schema,使用的task-path设定为checkpoint-1880,输入实例测试文本,输入的测试实例文本要求不出现具体的飞机型号,而是用模糊的词代指或者直接写“飞机”,得到抽取的实体三元组关系结果。
24、对比uie-base和checkpoint-1880的结果,发现后者的抽取效果要明显好于前者,其不仅做到了筛选掉了不需要抽取出来的实体和关系,对于schema规定中需要的实体和关系抽取的准确率也有明显提升。
25、进一步地,步骤4中,选择checkpoint-1880,在得到的结果中,通过对比设定一个阈值,若高于这个阈值,则选择输出这个关系;若低于这个值,则不输出。输出的格式为“头实体关系尾实体”。
26、yolov8检测到的结果与规定的46种飞机种类字典做到映射,作为可以替换的实体名称。
27、在输出的头实体或者尾实体,若出现“飞机”的字眼,使用yolov8目标检测得到的飞机具体型号进行替换。
28、以“头实体关系尾实体”的形式输出最终结果。
29、下面结合说明书附图对本发明作进一步描述。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314363.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表