基于Transformer编码器和自监督预训练模型的车辆驾驶风险分类方法
- 国知局
- 2024-10-21 14:21:23
本发明属于计算机,涉及一种基于transformer编码器和自监督预训练模型的车辆驾驶风险分类方法。
背景技术:
1、在大数据与物联网技术高速发展的当代,车辆驾驶安全越来越成为人们关注的话题,目前的车辆普遍安装有各类用以记录不同行驶数据的传感器,包括gps、速度计、加速度计、电量表等,日积月累之下,智能网联汽车的数据库不断扩张,这些数据覆盖了人、车、路三个维度,有着巨大的研究价值。
2、汽车传感器提供的大量真实数据为我们解决汽车驾驶安全预测这一问题提供了可能,但也存在着一些挑战:
3、1.智能网联场景中的行为差异:智能网联场景下的汽车类型不同,涵盖了传统燃油车辆、混合动力车辆、纯电车辆以及其他类型的新能源车辆等,由于其动力系统的不同,导致在行驶过程中的各项参数上,不同种类的汽车间存在着较大的差异,这导致了目前的驾驶行为分析模型不能很好地广泛应用。
4、2.数据密集,多特征:目前,智能网联场景中的车辆普遍安装有各类用以记录不同行驶数据的传感器,一辆智能网联新能源汽车每天至少收集约10tb的数据,而这些数据又是典型的高维时序数据,使用传统的机器学习方法从中挖掘用于解决汽车驾驶安全预测的模式的难度很高。
5、3.缺乏标注,目前对于车辆驾驶行为数据与驾驶安全性的相关研究尚不成熟,获取用于训练的大量标注数据的难度与成本过高。
6、近年来,多元时间序列(mts)是一种重要的数据类型,它们广泛存在于科学、医学、交通、金融、工程和工业应用等领域。它们通常表示一组同步变量(例如,不同物理量的同时测量)随时间的变化,以及一组因变量与公共自变量的对应变化。与时间序列分析相关的工作主要聚焦于两个方面:一是时间序列趋势预测,即将历史时段的数据作为特征输入,预测后续时段的某些指标的变化趋势;二是时间序列分类,即通过研究时间序列数据的特征与其对应类别之间的关系,通过机器学习或深度学习的方法训练出一个分类器,从而够判断给出的具有相同数据结构的无标签时间序列数据所属的类别。
7、在分类任务中,主要使用自编码的预训练模型。在nlp领域中bert引入了maskedlanguage model(mlm)和next sentence prediction(nsp)两种策略,有利于学习到领域中的通用知识。而对于汽车驾驶风险分类这一时序数据领域的任务,同样可以使用与mlm类似的掩蔽输入序列并预测的策略学习到汽车驾驶时序数据中的模式特征。
8、最后,基于transformer的模型也可用于时间序列建模,transformer是一种重要的、最近发展起来的深度学习模型,在nlp中获得广泛成功的一个关键因素是能够通过无监督的预训练学习如何表示自然语言。transformer中的注意力机制是多头注意力机制,引入自注意机制后会更容易捕获序列中长距离相互依赖特征,transformer利用了自注意机制的并行性,采用多头注意力,将模型分为多个头,形成多个子空间,从而让模型去关注不同方向的信息,多头自注意力由多个单头注意力结果拼接得到,这一特性使它也特别适合于时间序列数据的建模。
技术实现思路
1、为了解决现有技术存在的不足,本发明的目的是提供一种基于transformer编码器和自监督预训练模型的汽车驾驶风险分类方法。将汽车驾驶安全性分析问题建模为多元时间序列数据预测任务,建立相应的模型进行学习与训练,通过对这些驾驶数据进行处理和分析,建立自监督预训练模型的方法解决原始数据的问题,对于车辆驾驶安全性相关的研究工作具有很重大的现实意义。
2、实现本发明目的具体技术方案是:
3、一种基于transformer编码器和自监督预训练模型的汽车驾驶风险分类方法,包括如下步骤:
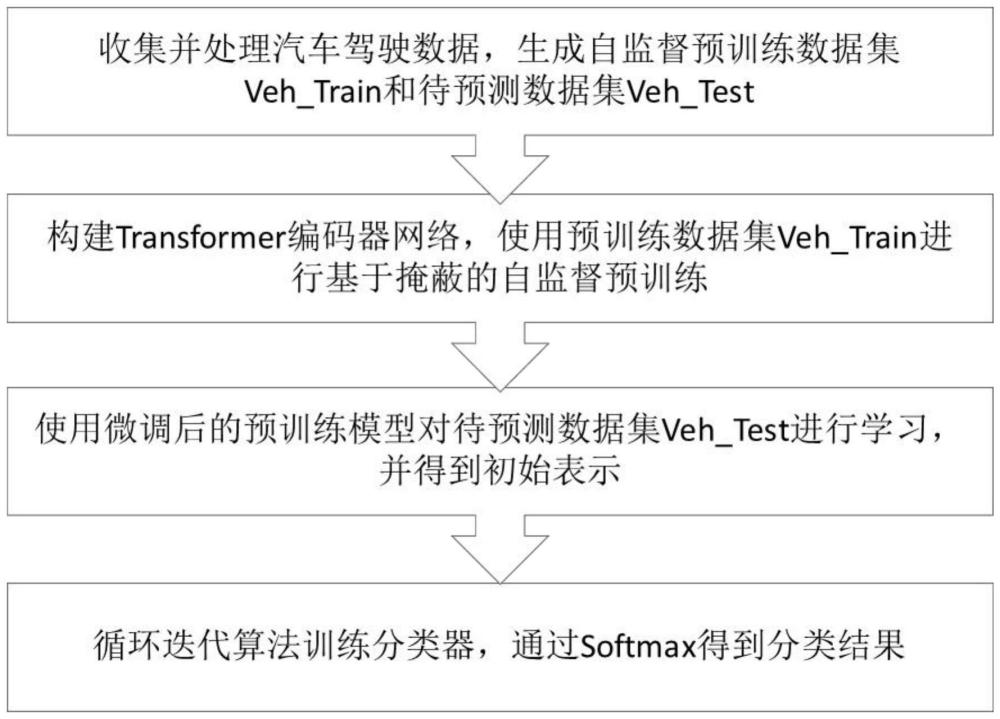
4、步骤一:收集并处理汽车驾驶数据,生成自监督预训练数据集veh_train(占总驾驶序列的20%)和待预测数据集veh_test(剩余的80%);所述驾驶序列是指汽车在某一段行驶过程中各个时刻的瞬时参数按时间构建获得的参数序列;
5、步骤二:构建6层transformer编码器网络用于时间序列数据建模,其中每层包括自注意力层,以及前馈网络两个子层,每个编码器的结构相同并使用不同的权重参数。使用自监督预训练数据集veh_train进行基于掩蔽的自监督预训练;
6、步骤三:对veh_test中的每个驾驶数据段i,使用transformer编码器得到对待预测数据集veh_test的初始表示,使用步骤二中微调后的预训练模型对待预测数据集veh_test进行学习,并得到注意力分数;
7、步骤四:循环迭代训练分类器,对序列计算注意力分数,输出层通过softmax得到分类结果。
8、步骤一中,所述收集并处理的汽车驾驶数据包括gps信息、速度、加速度、电量、转向灯开启状态、油门开合度、刹车开合度、总里程等;所述处理是指对于上述数据中存在的重复值进行删除、对于缺失值进行插补、对于异常值进行删除,并根据瞬时速度,从启动到最终停止这一过程对驾驶数据进行切分,数据段经过上述操作收集并处理后的得到的数据代表了汽车在一段行驶过程中各个时刻的瞬时参数。
9、步骤二中,利用所述自监督训练数据集veh_train微调驾驶时序数据预训练模型(transformer模型),具体通过以下方式进行:
10、将veh_train中的驾驶序列用作自监督预训练的输入序列,该输入序列的随机15%设置为0,然后要求transformer模型给出掩蔽值的预测。对于每轮训练,预训练模型将独立地创建二进制噪声掩码m,通过向量元素乘法屏蔽输入:其中,表示进行掩蔽后的输入,x表示原始输入;每个掩蔽段的长度遵循平均值为3的几何分布,被掩蔽的序列添加位置编码后形成序列嵌入,通过训练transformer模型给出对掩蔽序列的预测,损失函数如下:
11、
12、其中,x表示输入驾驶序列数据的实际值,表示模型对掩蔽后的驾驶序列数据的预测值,为均方误差损失函数,(j,i)为被掩蔽的驾驶序列数据元素的标号;
13、这种掩蔽模式鼓励transformer模型学习关注每一时刻单个特征的前一时段和后一时段的值,以及这一时刻时间序列中其他特征的当代值,以便学习建模变量之间的相互依赖性。transformer编码器输出最终的表示向量rt通过线性层,分类模型将给出原本输入向量的预测。
14、
15、其中,wm,bm是可学习的参数,在训练过程中会被自适应优化得出。表示t时刻模型对原始输入驾驶序列数据的预测值。
16、步骤三中,将驾驶数据训练样本veh_test中每个驾驶数据段的每个维度,用transformer编码器模型减去训练集样本的平均值并将其除以其方差,然后将其线性投影到transformer模型的序列元素表示维度的向量空间中:
17、zt=wpxt+bp
18、z′=z+p
19、其中wp,bp为可学习的模型参数,zt为被编码的驾驶数据时序向量。z为由zt组成的驾驶数据时序矩阵,z′为z添加完位置编码后用作模型输入的矩阵,p为位置编码,z′在乘以相应的线性变换矩阵wq、wk、wv后(wq、wk、wv在模型训练中自适应优化得出)将成为自注意层的查询、键和值,并计算注意力分数:
20、
21、q为查询向量、k为键向量、v为值向量,dk是键向量和查询向量的维度。
22、步骤四中,最终所有时间步长的表示向量将被连接成一个向量ro,用作线性输出层的输入:
23、
24、
25、wo,bo在训练过程中会被自适应优化得出,循环迭代算法模型,预测结果将被传递到softmax层以获得分类结果(安全或危险)。利用交叉熵损失函数优化分类效果,为交叉熵损失函数,batch_size为批大小,y为线性层输出的实际值,为线性层输出的预测值。
26、本发明的有益效果包括:
27、1.基于transformer编码器与序列掩码机制,设计了一套适用于汽车驾驶数据的自监督预训练方案,并通过实验验证了其性能。
28、2.解决了来自汽车传感器的驾驶数据维度高、缺乏数据标注的问题,提升了目前的驾驶行为分类模型的分类准确度。
29、3.本发明的汽车驾驶数据自监督预训练技术实现了在只使用很少一部分标注数据(数据集总条数20%)的前提下,对汽车驾驶行为进行有效的分类。
本文地址:https://www.jishuxx.com/zhuanli/20241021/317840.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。