一种基于多模态软提示学习的中文点击诱饵检测方法
- 国知局
- 2024-10-21 14:36:46
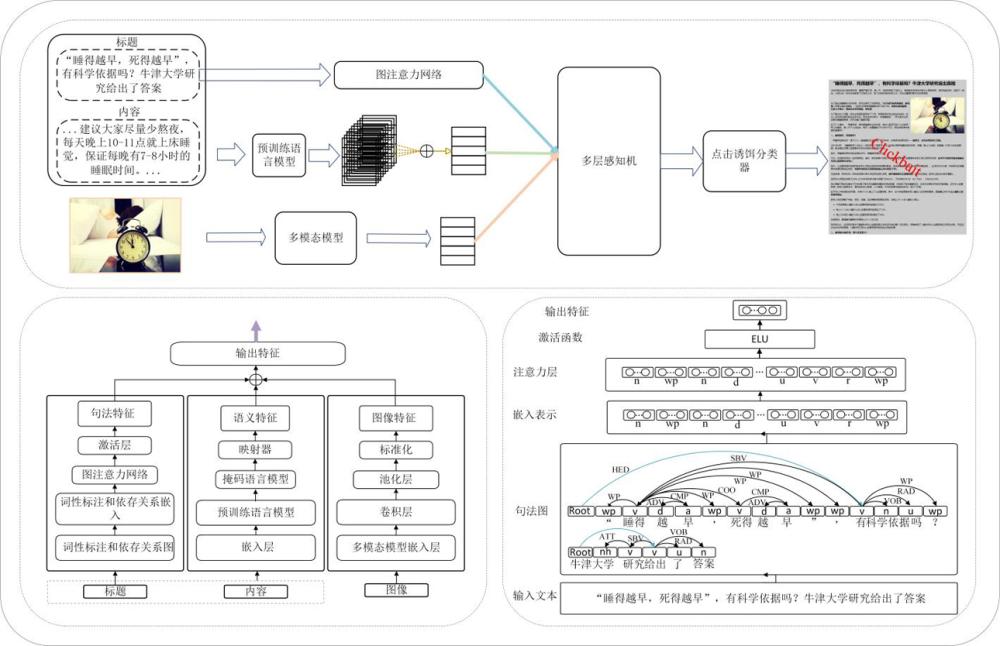
本发明涉及自然语言处理研究领域,特别涉及一种基于多模态软提示学习的中文点击诱饵检测方法。
背景技术:
1、在近年来,社交媒体及新闻门户等在线服务快速扩展,证明吸引更多点击和网络流量直接关联着更多盈利和商业收入。为追求此目标,众多内容发布者甚至新闻平台自身采用了标题夸张、耸人听闻,与真实内容不符的手法来吸引用户点击,被称为"点击诱饵"。
2、汉语作为现代世界唯一保留的象形文字,也是拥有最多网民的语言之一。举例来说,微信和新浪微博作为中国最受欢迎的社交媒体应用,在2023年第一季度的月活跃账户分别达到了13.1亿和5.9亿。在中国,标题党现象以前所未有的速度传播,例如,中国最大的实时通信工具微信在2023年明确了禁止传播标题党链接的规定。
3、迄今为止,针对中文点击诱饵的检测研究范式已经从深度神经网络发展到对plms模型的微调,并最近进展到即时调整模型。一些方法采用深度方案学习具有代表性的特征,以获得更好的点击诱饵检测性能。随着plms模型在各种自然语言处理任务中广泛应用,微调模型能够有效地将上游预训练的知识运用于下游子任务,包括点击诱饵检测。
4、尽管取得这些进展,但仍有两个主要限制阻碍了这些方法的进一步发展,首先是有效地利用新闻或帖子中的多模态上下文信息,这些信息通常包括文本和图像。虽然先前的尝试将多模态信息用于点击诱饵检测,但所采用的方式过于简单,且由于深度全连接网络的限制,仅使用lstm和cnn无法充分捕捉多模态信息中全局特征。中文点击诱饵检测的第二个挑战是学习中文复杂特征和融合特征(包括标题和内容)。相对于英语和其他语言,汉语的表达形式多样,这给理解具有复杂语义和句法结构的文本带来了巨大挑战。
技术实现思路
1、本发明的目的是克服现有技术缺陷,提供一种基于多模态软提示学习的中文点击诱饵检测方法,将文本和图像信息联合构建成一个连续的提示嵌入,作为plms的输入,通过训练样本持续更新软提示,得到最优的提示模板;通过这种方式,模型只利用少量的训练样本就可以学习到更加准确的特征表示,有效的提升检测的准确率。
2、本发明的目的是这样实现的:一种基于多模态软提示学习的中文点击诱饵检测方法,包括以下步骤:
3、1)将新闻中包含的图片传入预训练的clip模型,捕获其中包含的特征信息;
4、2)通过将标题的词性标注作为节点,依存句法关系作为边,构建有向图,然后,将该图传入gat网络,以获取标题的句法结构特征;
5、3)选择合适的预训练语言模型,将该训练模型作为主干,构建提示学习中的标签词和模板;
6、4)最后将每个标签词的概率映射到对应的类别标签中,并用该类别标签的最终预测分数作为分类结果。
7、作为本发明的进一步限定,所述步骤1)包括:
8、1.1)在处理图像内容时,给定一组图像f={img1,...,imgi,...,imgn},对于每张图像imgi,首先使用clip模型的编码器进行特征提取,图像特征表示为:
9、
10、1.2)将编码后的图像特征通过投影头进行映射,将其映射到较低维的空间中,得到投影后的特征向量
11、
12、1.3)对图像数据进行了标准化处理,得到最终的图像特征表示
13、
14、1.4)在获得每张图像的特征表示,将来自同一篇新闻的图像特征拼接起来,获取最终的图像特征表示fimg:
15、
16、其中combined()表示拼接图像特征的操作。
17、作为本发明的进一步限定,所述步骤2)包括:
18、2.1)首先利用分词工具对标题进行分词,得到分词结果:t={w1,w2,...,wm-1,wm},将标题分割为单个词语;然后使用ltp4工具对每个词进行词性标注,得到词性标注结果:p={p1,p2,...,pm-1,pm},其中pi表示第i个词的词性标注;将每个词性标注作为节点,将相邻节点之间的依赖关系作为有向边,构建一个有向图g;
19、2.2)对于每一个节点,随机初始化一个150维的特征向量表示其初始状态;节点之间的注意力权重表示为:
20、
21、其中是可学习的参数,||表示拼接操作,eij表示节点i和j之间的注意力权重,zi和zj表示节点i和j的特征矩阵;对于节点i,与其相邻节点j的注意力权重为:
22、
23、2.3)通过注意力权重对邻居节点的表示进行加权求和:
24、
25、其中hi表示节点i聚合邻居节点后的表示,zj表示节点j的特征矩阵;
26、2.4)对于标题中的所有节点特征hi,通过加权求和来得到标题级语法表示fsem:
27、
28、其中wi是一个可调节的权重矩阵。
29、作为本发明的进一步限定,所述步骤3)包括:
30、3.1)选择基于中文的roberta模型作为预训练语言模型,使用全词的mask方法学习中文文本的特征;
31、3.2)通过软模版来构建输入,在一个连续空间中训练模型以得到最优提示;模板t可以被设计为:
32、t={[ui],...,x,...,[un],[mask]} (9)
33、其中ui表示第i个可学习的token;然后将构造好的提示t传入plm的encoder层:
34、hi,...,hx,...,hn,hmask=encoder(t) (10)
35、其中hi表示第i个token的隐向量,得到输入的隐向量后,再通过bilstm来学习文本的上下文信息,以更新可学习tokenui的参数,这个过程被形式化为:
36、hi=bilstm(h0,hx,hn) (11)
37、最后关于hi的损失函数被形式化为:
38、
39、其中,m(x,mask)表示预训练语言模型m在帖子内容x和掩码mask上的输出,表示使损失函数最小化的变量hi的值。
40、作为本发明的进一步限定,所述步骤4)包括:
41、4.1)plm的encoder层的输出会被传到plm的transformer层:
42、hmask=transformer(encoder(t)) (13)
43、通过将包含上下文信息的向量与式(4)得到的句法结构特征拼接:
44、
45、输入到多层感知机mlp来获取词集中每一个标签词的概率,将点击诱饵的检测问题转换成标签词的概率计算问题,计算公式为:
46、p(y∈y|x)=p(fcom=v∈vy|x) (15)
47、使用交叉熵损失函数来更新整个模型在训练过程中的参数:
48、
49、其中,n表示样本数量,作为平均损失的归一化因子,∑表示将所有样本的损失进行累加,y*是指真实的标签,α表示正则化项的系数,用于控制正则化项在总损失中的权重。
50、本发明采用以上技术方案,与现有技术相比,有益效果为:1)本发明利用多模态软提示学习,将文本和图像信息联合构建为连续的提示嵌入,作为预训练语言模型(plms)的输入,这对于中文点击诱饵检测具有显著的价值和影响。
51、2)本发明建立了一个多模态网络,针对每个新闻或帖子创建了分类模型;这个模型充分考虑了图像数据在补充文本数据方面的作用,有助于更全面地理解多模态数据,提升了点击诱饵检测的性能。
52、3)本发明的软提示设计,包括gat模型等,旨在充分利用中文复杂语义和句法结构的融合特征;与以往不同的是,提出了自动生成模板的最佳软提示,这些改进显著提高了检测性能。
53、4)通过在三个基准数据集上的实验证明,本方法在中文点击诱饵检测任务中表现出鲁棒性和有效性。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318717.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种电能质量扰动识别方法
下一篇
返回列表