基于文件驱动的元数据采集方法、装置、设备及存储介质与流程
- 国知局
- 2024-12-06 12:11:23
本申请涉及数据库领域,特别涉及一种基于文件驱动的元数据采集方法、装置、设备及存储介质。
背景技术:
1、在当今信息化的社会中,大数据分析技术已经成为了企业和政务的重要工具。特别对于实时性要求较高的服务器和数据库系统,数据查询、采集与同步对时效性和一致性的要求较高,而大数据环境下元数据采集效率存在瓶颈。
2、在相关技术中,针对海量数据集中元数据采集过程耗时过长、效率低下的问题。如利用jdbc api连接数据库以查询元数据信息,这种做法在效率上存在明显瓶颈,每次查询操作均需独立建立数据库会话,导致会话创建与销毁的开销显著累积,降低了整体处理效率。尤其在多线程环境下,若每个线程都独立管理其数据库连接,不仅会加剧对数据库资源的竞争,还可能因为频繁地打开和关闭连接而引发性能瓶颈,影响数据库的原本业务连续性和稳定性。
技术实现思路
1、本发明提供一种基于文件驱动的元数据采集方法、装置、设备及存储介质,解决数据采集和查询入库效率不高的问题。
2、一方面,本申请提供一种基于文件驱动的元数据采集方法,所述方法包括:
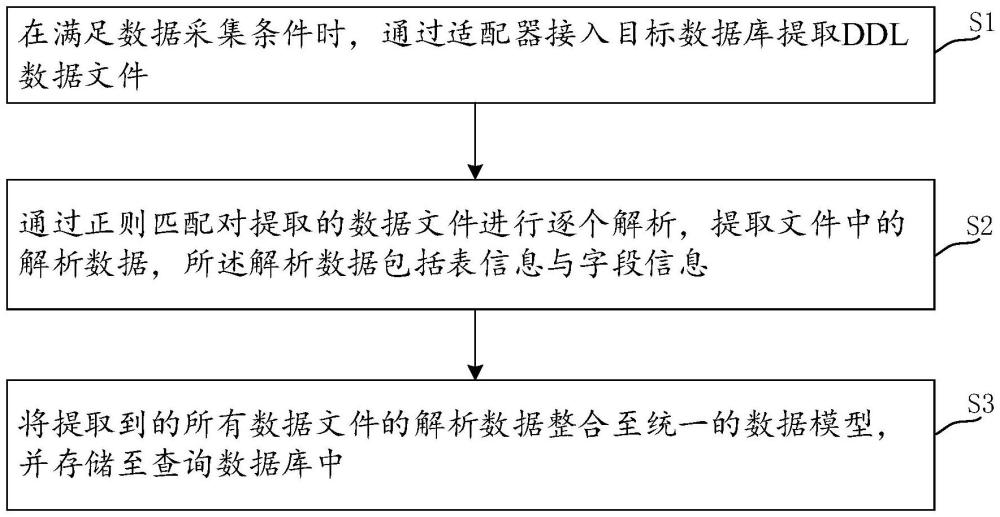
3、在满足数据采集条件时,通过适配器接入目标数据库提取ddl数据文件;
4、通过正则匹配对提取的数据文件进行逐个解析,提取文件中的解析数据,所述解析数据包括表信息与字段信息;
5、将提取到的所有数据文件的解析数据整合至统一的数据模型,并存储至查询数据库中。
6、具体的,所述目标数据包括mysql数据库、oracle数据库和hive数据库中至少一种,每个数据库中存储有各自类型的ddl数据文件。
7、具体的,所述适配器设置有与目标数据库适配的数据接口,其中包含有mysql适配器、oracle和hive适配器中至少一种,分别与mysql数据库、oracle数据库和hive数据库进行连接。
8、具体的,数据采集条件为设定的数据采集时间间隔或接收到外部数据采集指令,当接收到对目标数据库的采集指令时,启动对应适配器遍历其中的所有ddl数据文件,并送入解析器进行解析。
9、具体的,所述提取文件中的解析数据,包括:
10、正则匹配解析目标数据库中所有ddl文件的建表语句;
11、根据建表语句对ddl文件进行提取,获取其中所有的表名、表注释和对应的主键信息;
12、提取每个表的字段名、字段注释、字段类型、字段长度和是否为空信息。
13、具体的,所述将提取到的所有数据文件的解析数据整合至统一的数据模型,包括:
14、将每个解析ddl文件的解析结果以表为单位,分别建立每个表的元数据信息,将所有解析出的元数据信息整合成为统一的数据模型。
15、具体的,在将数据模型存储至查询数据库后,所述方法还包括:
16、响应于接收到数据查询指令,解析其中包含的表名信息或字段名信息,根据表名信息或字段名信息从查询数据库中获取对应的文件信息,并返回查询结果。
17、另一方面,本申请提供一种基于文件驱动的元数据采集装置,所述装置包括:
18、提取模块,用于在满足数据采集条件时,通过适配器接入目标数据库提取ddl数据文件;
19、解析模块,用于通过正则匹配对提取的数据文件进行逐个解析,提取文件中的解析数据,所述解析数据包括表信息与字段信息;
20、整合模块,用于将提取到的所有数据文件的解析数据整合至统一的数据模型,并存储至查询数据库中。
21、另一方面,本申请提供一种基于文件驱动的元数据采集装置,所述装置包括:
22、提取模块,用于在满足数据采集条件时,通过适配器接入目标数据库提取ddl数据文件;
23、解析模块,用于通过正则匹配对提取的数据文件进行逐个解析,提取文件中的解析数据,所述解析数据包括表信息与字段信息;
24、整合模块,用于将提取到的所有数据文件的解析数据整合至统一的数据模型,并存储至查询数据库中。
25、又一方面,本申请提供一种计算机设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现上述任一所述的基于文件驱动的元数据采集方法。
26、又一方面,本申请提供计算机可读存储介质,所述可读存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现上述任一所述的基于文件驱动的元数据采集方法。
27、本发明带来的有益效果至少包括:使用ddl文件提取元数据的采集方法建立数据模型并存储的方式,相较于传统jdbc方法大幅缩短了采集周期。通过引入离线文件作为数据处理的中介,彻底消除了直接对数据库实时业务操作的直接影响,确保了数据库服务的连续性与稳定性,为大数据处理与分析提供了更加安全、高效的数据采集解决方案。
技术特征:1.一种基于文件驱动的元数据采集方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述目标数据包括mysql数据库、oracle数据库和hive数据库中至少一种,每个数据库中存储有各自类型的ddl数据文件。
3.根据权利要求2所述的方法,其特征在于,所述适配器设置有与目标数据库适配的数据接口,其中包含有mysql适配器、oracle和hive适配器中至少一种,分别与mysql数据库、oracle数据库和hive数据库进行连接。
4.根据权利要求1所述的方法,其特征在于,数据采集条件为设定的数据采集时间间隔或接收到外部数据采集指令,当接收到对目标数据库的采集指令时,启动对应适配器遍历其中的所有ddl数据文件,并送入解析器进行解析。
5.根据权利要求1-4任一所述的方法,其特征在于,所述提取文件中的解析数据,包括:
6.根据权利要求5所述的方法,其特征在于,所述将提取到的所有数据文件的解析数据整合至统一的数据模型,包括:
7.根据权利要求6所述的方法,其特征在于,在将数据模型存储至查询数据库后,所述方法还包括:
8.一种基于文件驱动的元数据采集装置,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如权利要求1至7任一所述的基于文件驱动的元数据采集方法。
10.一种计算机可读存储介质,其特征在于,所述可读存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如权利要求1至7任一所述的基于文件驱动的元数据采集方法。
技术总结本申请公开基于文件驱动的元数据采集方法、装置、设备及存储介质,涉及数据库领域,在满足数据采集条件时,通过适配器接入目标数据库提取DDL数据文件;通过正则匹配对提取的数据文件进行逐个解析,提取文件中的解析数据,解析数据包括表信息与字段信息;将提取到的所有数据文件的元数据整合至统一的数据模型,并存储至查询数据库中。使用DDL文件提取元数据的采集方法建立数据模型并存储的方式,相较于传统JDBC方法大幅缩短了采集周期。通过引入离线文件作为数据处理的中介,彻底消除了直接对数据库实时业务操作的直接影响,确保了数据库服务的连续性与稳定性。技术研发人员:马树,郁彬受保护的技术使用者:无锡锡银金科信息技术有限责任公司技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/339858.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。