一种面向无人机视角的目标检测方法与流程
- 国知局
- 2024-12-06 12:28:49
本发明属于目标识别检测,尤其涉及一种面向无人机视角的目标检测方法。
背景技术:
1、在现代无人机技术的快速发展中,目标检测已成为一个关键的研究领域,尤其是在复杂的环境下如城市景观或拥挤的场所中进行实时精确的目标识别和定位。目标检测,旨在在给定的图像或视频中检测出目标物体在图像中的位置和大小,并进行分类或识别等相关任务。
2、但是,目前的目标检测系统,由于应用领域(基本上监控器或者智能汽车驾驶)的关系,其检测的视角多为静态视角或者地面视角。其检测对象的特点与无人机存在较大的差异。因此,传统的目标检测系统面临着多种挑战,包括目标尺寸小、易于与背景融合以及遮挡等问题,这些问题严重影响了检测的准确性和实用性。尽管目前已有多种基于深度学习的目标检测算法,如ssd、yolo和faster r-cnn等,它们在一定程度上提高了检测的准确性和速度,但在处理高动态环境下的小目标检测时仍然存在诸多不足。特别是从无人机视角进行观察时,目标的小尺寸和动态变化使得检测更加困难。
3、因此,怎样才能保证高动态环境下的小目标检测的有效性,从而保证无人机在复杂背景和多尺度目标场景下的目标检测结果的可靠性,成为目前亟待解决的问题。
技术实现思路
1、针对上述现有技术的不足,本发明提供了一种面向无人机视角的目标检测方法,可以保证高动态环境下的小目标检测的有效性,从而保证无人机在复杂背景和多尺度目标场景下的目标检测结果的可靠性。
2、为了解决上述技术问题,本发明采用了如下的技术方案:
3、一种面向无人机视角的目标检测方法,包括以下步骤:
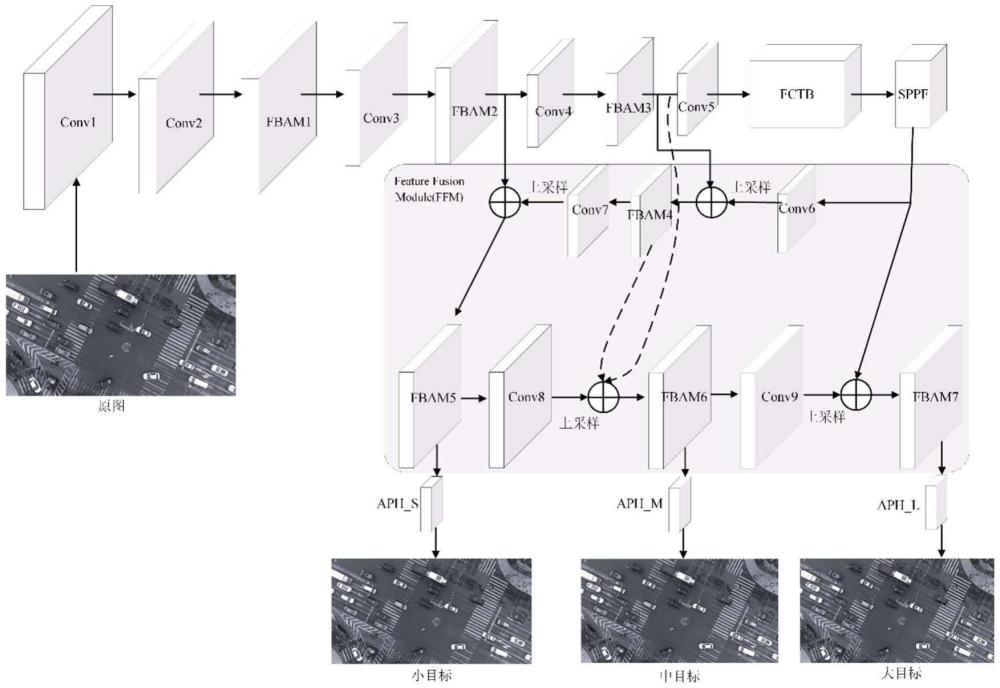
4、s1、构建目标检测网络ct-rodn;ct-rodn包括主干网络、特征融合模块和注意力预测头;主干网络用于对输入图像进行特征提取;特征融合模块用于对提取的各层级特征进行融合;注意力预测头用于提取融合后的特征图的关键区域,并基于提取的关键区域进行目标检测识别;
5、其中,主干网络包括基于频率域的分块复合注意力模块fbam,以及基于频率域的cnn-transformer模块fctb;fbam模块通过结合频域分析来增强对空中小目标的理解;fctb模块用于对卷积获取的特征图进行处理和聚合,以获取图像的全局信息;
6、主干网络的工作过程包括:首先,对于输入图像,通过卷积模块conv1和conv2进行四倍下采样;然后,使用fbam模块和conv模块交替进行特征提取和图像下采样;接着,使用fctb模块对卷积捕获的特征图信息进行处理和聚合,以获取图像的全局信息,同时引入快速空间金字塔池化sppf,通过多分支池化层构建不同尺度的特征图,并将它们融合以增强特征的表达能力;
7、s2、获取无人机视角下的拍摄图像并进行处理,得到训练数据;并使用训练数据对目标检测网络ct-rodn进行训练;
8、s3、使用训练后的目标检测网络ct-rodn,进行实际的无人机目标检测任务。
9、本发明与现有技术相比,具有如下有益效果:
10、1、使用本方法,进行目标识别时,fbam模块通过结合频域分析来增强对空中小目标的理解。这样,通过强调图像中的重要频率成分,使得网络能够更加聚焦于局部的重要特征,从而提高了对小而低对比度目标的识别精度。fctb模块用于对卷积获取的特征图进行处理和聚合,以获取图像的全局信息。这样,通过结合目标周围的上下文环境,通过分析整体的频谱信息,提高了目标检测的准确性,特别是在目标部分被遮挡的情况下。这种上下文感知的方法显著增强系统在高动态和复杂环境中的识别能力,确保无人机在执行关键任务时的性能和可靠性。
11、2、本方法中,特征融合模块ffm可以为低层特征注入更多高层语义信息,同时为高层特征提供更丰富的细节,从而增强检测器对小目标的跨尺度检测性能。
12、3、注意力预测头的设置,可以提取融合后的特征图的关键区域,通过引入注意力机制,可以提高检测复杂背景中目标的能力,从不同分辨率的特征图中检测不同尺度的目标。
13、本方法构建的目标检测网络ct-rodn,可以同时兼顾模型的复杂度与检测精度,不仅提升目标检测的速度和精度,还能够显著增强无人机在实际操作环境中的应用潜力,满足现代无人机技术发展对实时、精确目标检测的迫切需求。
14、综上,使用本方法,可以保证高动态环境下小目标检测的有效性,从而保证无人机在复杂背景和多尺度目标场景下目标检测结果的可靠性。
15、优选地,fbam模块的工作过程包括:
16、首先,将输入特征图f∈rc×h×w沿空间维度均匀分割为多个局部块fp;再沿通道维度进一步等比例分隔为多个局部子块ci,i∈{1,2,…,n};其中,ci∈r(c/n)×p×p;p代表局部块的尺寸;n是等分的数量;
17、然后,对于每个局部子块ci,提取其频率分量,并将该频率分量与对应的局部子块ci进行逐元素相乘,得到对应的频率成分特征;并将各局部子块ci的频率成分特征进行拼接组合,形成局部块的通道频率注意力向量freq;
18、接着,将频率注意力向量freq和对应的局部块特征fp进行逐元素相乘,得到分块频率通道注意力特征组合;并将分块频率通道注意力特征组合还原为原始尺寸,得到完整聚合向量fc;将fc和原始特征向量f进行concat拼接,得到通道维数为2c的中间特征图,并采用卷积核大小为1×1的卷积层将其通道数降为c,得到特征图-s;
19、然后,对于特征图fs,沿着通道方向分别进行最大池化和平均池化,生成特征图fsmax∈r1×h×w和fsavg∈r1×h×w;将fsmax和esavg沿着通道进行拼接,并将拼接得到的特征使用7×7卷积降维,再通过sigmoid激活函数,生成特征es∈r1×h×w;
20、最后,将es与fs相乘,得到通道与空间信息聚合后的注意力特征fo。
21、这样的设置,基于频率域的分块复合注意力模块fbam通过结合频域分析来增强对空中小目标的理解,极大地丰富了不同频率特征的多样性,优化了频率信息的利用。
22、优选地,使用二维离散余弦变换2d-dct提取局部子块ci的频率分量。
23、这样,在通道注意力机制中引入2d-dct来自适应的在不同频率分量上获取更加鲁棒的频域特征。
24、优选地,fctb模块的工作做成包括:
25、首先,将特征图经过一个1×1卷积操作,步幅为1,将特征图的通道数减半,保持特征图的空间尺寸不变;
26、之后,将特征图分别通过两个分支进行处理;其中一个分支进入频谱块spectralblock操作捕捉特征图中的频率成分;另一个分支进入卷积多头自注意力cmhsa机制,通过cmhsa对特征图进行处理,捕捉特征图中不同位置之间的依赖关系和全局信息;
27、然后,两个分支的输出特征图进行拼接,再将拼接后的特征图经过另一个1×1卷积操作,步幅为1,得到最终的特征图。
28、这样的设置,通过频谱块和卷积多头自注意力机制的组合,fctb模块能够同时捕捉特征图中的频率成分和全局依赖关系。这种多尺度、多角度的特征融合有助于增强模型的表征能力,使其能够更全面地理解输入数据。除此,对于需要同时考虑局部细节和全局信息的任务(如图像识别、视频分析等),fctb模块可能带来性能上的提升。通过整合频谱块和卷积多头自注意力机制的优势,模型能够更准确地捕捉和理解输入数据中的关键信息。
29、优选地,频谱块spectral block由一个频谱门控网络构成;频谱门控网络包括快速傅里叶变换fft层、加权门控和逆快速傅里叶变换ifft层。
30、优选地,频谱块spectral block的工作过程包括:
31、首先,使用fft将图像空间转换为频谱空间;
32、之后,加权门控应用一个特定的可学习权重参数wc来确定每个频率成分的权重,并通过反向传播技术进行学习,以捕捉图像的线条和边缘;
33、然后,将加权后的频谱数据通过ifft转换回图像空间,再通过层归一化进行归一化处理,并通过多层感知器mlp块实现通道混合,得到频率域特征提取结果;
34、最后,按照残差连接的方式将频率域特征提取结果与原始输入执行按元素相加操作。
35、这样的设置,通过频谱块spectral block,可以捕捉图像中不同的频率成分,以理解局部频率。
36、通过fft将图像从空间域转换到频率域,使得图像中的线条、边缘等高频成分和背景、平滑区域等低频成分在频谱上得以分离。加权门控机制通过可学习的权重参数wc对不同的频率成分进行加权,有助于模型在训练过程中学习到哪些频率成分对于特定任务更为重要。这种频率域的特征提取方式,相比直接在空间域上进行卷积操作,能够更直接地关注到图像中的纹理、结构等特性。
37、加权门控机制不仅可以帮助模型捕捉到重要的频率成分,还可能在一定程度上抑制噪声或不必要的频率成分。因为噪声往往分布在高频区域,而加权门控可以通过学习到的权重参数来降低这些区域的贡献。此外,通过ifft将加权后的频谱数据转换回图像空间,并结合层归一化和mlp块进行进一步处理,可以进一步增强模型对重要特征的提取能力,并减少噪声的干扰。
38、mlp块在频谱块中起到了通道混合的作用,它能够将不同通道的特征进行融合,从而增强模型的表征能力。这种通道混合的方式有助于模型从多个角度理解图像,捕捉到更丰富的特征信息。最后,通过残差连接将频率域特征提取结果与原始输入进行按元素相加操作,有助于保持输入信息的完整性,并减少在深层网络中的梯度消失或梯度爆炸问题。残差连接使得模型在训练过程中更容易收敛,同时也能够提高模型的泛化能力。
39、优选地,卷积多头自注意力cmhsa机制对特征图进行处理的过程包括:
40、将投影的标记展平为一维向量:
41、
42、其中,是第i层q/k/v矩阵的标记输入;flatten()表示展平操作;conv是标准卷积操作;s=1表示卷积核的大小;xi为卷积投影之前的标记;
43、q、k和v之间的注意力函数为:
44、
45、其中,c为输入标记的通道数;k=4表示cmhsa的头数;conv表示标准的1×1卷积操作;在softmax之后通过实例归一化in计算点积矩阵;
46、将每个头部的输出值通过线性投影拼接并调整成二维特征图作为最终输出。
47、这样,与线性投影相比,每个cmhsa的卷积投影只需要s2c2参数和o(s2c2t)flops,其中t是处理的标记数量,c是标记的通道维度。这些参数相对于模型的flops和总参数量来说可以忽略不计。在无人机视角下的车辆目标检测中,使用传统的多头自注意力机制msha存在着计算复杂度高,参数量大和处理局部特征不如卷积操作有效等问题。相比之下,本发明设计的卷积多头自注意力cmhsa具有计算复杂度低、参数量小等优点。
48、优选地,注意力预测头aph基于归一化的注意力模块nam注意力机制设置;注意力预测头aph分别在通道和空间两个独立维度上推断输入图像的注意力图,并利用这些注意力图对输入特征图进行加权,从而自适应地捕捉图像的显著区域。
49、这样的设置,可以提取出关键区域,使模型专注于有用的对象,提高检测模型抵抗混淆信息的能力。
50、优选地,注意力预测头aph包括通道注意力子模块和空间注意力子模块;通道注意力子模块使用批归一化的缩放因子来反映每个通道的重要性;空间注意力子模块使用相同的归一化方法来处理空间中每个像素,以抑制无关特征;
51、其中,缩放因子bout的计算式如下:
52、
53、式中,bn表示批归一化操作,μb和σb分别是小批量样本b的均值和标准差,而γ和β是可训练的仿射变换参数;ε为一个小的常数,通常取10-5或者10-6,以防止除零操作,提高计算的数值稳定性;bin为通道注意力子模块输入特征图;
54、通道注意力子模块的表达式为:
55、mc=sigmoid(wγ(bn(f1)));
56、其中,mc表示输出特征,γ为每个通道的缩放因子;权重wγ=γi/∑j=0γj。
57、空间注意力子模块的表达式为:
58、ms=sigmoid(wλ(bn(f2)));
59、其中,ms表示输出特征,λ为每个通道的缩放因子,权重wλ=λi/∑j=0λj。
60、这样,结合通道注意力子模块和空间注意力子模块的aph,能够同时从通道和空间两个维度对输入特征图进行自适应加权,从而更加精准地捕捉图像中的显著区域和关键特征。这种机制有助于提升模型的整体性能,包括分类准确性、检测精度和鲁棒性等方面。同时,由于两个子模块都利用了归一化方法进行计算,因此整体计算效率也较高,适合在实际应用中部署。
61、优选地,特征融合模块为基于双向特征金字塔网络bifpn的特征融合模块。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341626.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表