基于HVS的上下文对比和局部敏感特性的无参考图像质量评估方法、电子设备和存储介质
- 国知局
- 2024-12-06 12:30:56
本发明涉及计算机视觉,特别是指一种基于hvs的上下文对比和局部敏感特性的无参考图像质量评估方法、电子设备和存储介质。
背景技术:
1、图像质量评估(image quality assessment,iqa)致力于评估与人类视觉系统(human visual system,hvs)一致的数字图像的感知质量。它已应用于许多计算机视觉领域的研究,包括但不限于图像恢复和超分辨率。在真实世界中经常会遇到参考图像不可用和参考图像质量有问题的情况,因此尽管全参考iqa在各种研究中显示出了有前景的结果,但不需要参考图像的盲图像质量评估(blind image quality assessment,biqa)仍然更有吸引力、适用性和研究价值。
2、理想的biqa方法应与人体主观评分的图像质量具有较高的一致性。现有的sotabiqa方法通过模拟人类视觉系统来实现的一致性。例如,一些传统方法使用扭曲的图像、错误图和主观评分来学习hvs行为。随着深度学习的发展,通过在imagenet上提出的一个深度cnn预训练,直接预测主观质量评分的知觉分布。最近的工作,依靠预训练的上游骨干学习图像内容,随后判断图像质量,模拟图像的hvs感知。虽然目前这些尝试取得了有前景的改进,但仍存在两个缺陷:①从单一图像独立预测图像质量并不是最符合hvs的,因为人类倾向于比较图像而不是单独判断图像;②从预训练模型中提取的语义特征在biqa中往往是次优的,这是因为当图像的其余部分表现出相当好的质量时,hvs对局部失真尤为敏感,仅关注语义特征是不够的。例如,授权专利号为cn111709914b的发明专利公开了《一种基于hvs特性的无参考图像质量评价方法》,其方法步骤为:
3、(1)首先将图像数据库中的失真图像分为训练图像集和测试图像集;
4、(2)然后提取训练图像集和测试图像集的显著性区域,将训练图像集和测试图像集中的每幅图像划分为易引起视觉注意的显著性区域和不易引起人眼关注的非显著性区域;
5、(3)最后对训练图像集和测试图像集中的每幅图像进行分块,分别对训练图像集中显著性区域的图像块和非显著性区域的图像块提取自然统计特征,将测试集图像中提取的统计特征输入支持向量机svm中进行回归预测获得分数。
6、该方法虽然能够较好模拟hvs对显著性区域的关注,但是缺乏对比数据库上下文的质量信息,并没有完全实现模拟人类的感知过程。
技术实现思路
1、本发明的目的在于提供一种基于hvs的上下文对比和局部敏感特性的无参考图像质量评估方法、电子设备和存储介质,解决现有技术中存在的缺少全面模拟人类质量感知的缺陷而导致评价精度较低问题,能够更精确地模拟人类感知过程,提高图像质量评估的精度。
2、为了达成上述目的,本发明的解决方案之一是:
3、一种基于hvs的上下文对比和局部敏感特性的无参考图像质量评估方法,包括以下步骤:
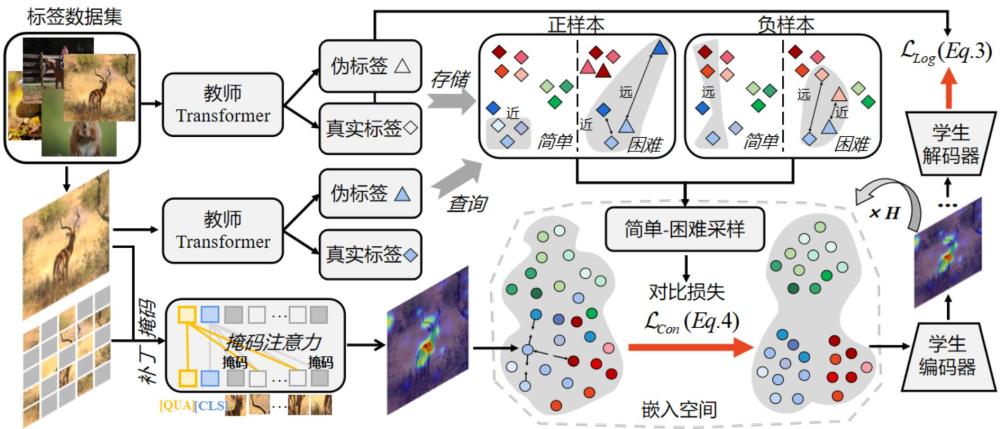
4、步骤1、构建网络模型,该网络模型包括以transformer为主干网路预训练的biqa教师模型、与教师模型具有相同主干网络的biqa学生模型;
5、步骤2、给定用于图像质量评估的训练数据集,对网络模型进行训练;
6、步骤3、将待评估图像输入训练后的网络模型,由网络模型输出预测的分数结果;
7、其中,步骤1按照以下三个准则进行:
8、(1)定义新的质量感知令牌,用于辅助网络模型提取与高级语义信息分离的低级质量特征;
9、(2)基于训练数据集与待评估图像之间的质量水平的相似性构建正集、负集;
10、(3)在知识蒸馏的框架下引入困难采样策略,其包括采样质量相似但教师推理不相似的困难正样本,以及采样质量不同但教师推理相似的困难负样本;使用infonce对比损失来捕获嵌入空间中的全局属性。
11、所述步骤1的准则(1)中,构造了一个掩码和注意掩码,其表达式如下:
12、;
13、;
14、其中,表示实数空间;表示补丁编码的数量加上类别编码的数量;表示掩码函数;下标表示补丁编码被掩码的位置;表示指示函数;以上两个表达式意味着质量令牌只关注那些没有被随机屏蔽的补丁令牌;
15、对于编码器的第个注意层,利用多头自我注意(mhsa)进行计算:
16、;
17、其中,表示编码器在第个注意层输出的特征;表示softmax函数;、、表示的线性变换;表示编码器的注意层总数;表示的线性变换;表示网络模型的第一层输入特征;
18、最后,由编码器在第个注意层后产生最终的输出特征,并由变压器解码器进行解码。
19、所述步骤2中,采用8个训练数据集,其中4个为合成失真数据库,另外4个为真实失真数据库;对网络模型进行训练的具体步骤是:
20、步骤2-1、将训练数据集中的图像输入网络模型,由教师模型通过transformer主干网络获得低质量图像的伪标签;
21、步骤2-2、根据获得的低质量图像的伪标签及其真实值(ground truth),通过步骤1的准则(3)采样正负样本,并使用infonce对比损失来捕获嵌入空间中的全局属性。
22、优选地,所述网络模型的输入是低质量标记数据集knoiq的低质量图像,其中、分别表示图像的高和宽,rgb格式的图像对应的标签为;具体步骤是:
23、步骤2-1、将图像输入网络模型,由教师模型获得图像的伪标签;
24、步骤2-2、根据训练批次的图像的标签和教师模型推断获得的伪标签进行简单-困难正负样本的采样;其中正负样本的定义是:
25、首先将分数向量扩展为矩阵,其中表示训练批次的大小;然后使用曼哈顿距离计算得分距离矩阵,对于每一对图像和,对的第行进行排序,得到升序的距离向量,中的和的得分距离对应的指标记为;若指标小于和的乘积则为正样本,反之如果指标大于和的乘积则为负样本,其中和是预设的超参数,本实施例中分别是20%和60%;以上,用计算公式表达如下:
26、;
27、其中,表示计算曼哈顿距离;表示的转置;表示类别分类器;表示正样本;表示负样本。
28、优选地,所述步骤2中,抽取简单样本的过程是:
29、对于每个嵌入图像特征的特征,从矩阵中按升序的顺序抽取前10%和后40%的样本,分别作为简单正样本、简单负样本,其中表示图像特征;然后,使用简单正样本、简单负样本计算对比损失;
30、由教师模型生成伪分数向量,将其扩展为矩阵,最终的分数预测误差矩阵为;抽取困难样本的过程是:
31、首先从矩阵中按升序的顺序抽取前10%最接近的样本作为困难正样本、前40最遥远的样本作为困难负样本,将困难正样本、困难负样本与简单正样本、简单负样本相交,以减少抽样方法的偏差,使得本发明的对比学习能够优先考虑具有挑战性的样本进行预测,从而使嵌入对质量变化更加敏感;其次,利用infonce对比损失扩展到监督设置,结合简单-困难正负样本采用并利用现有的监督对比学习,定义质量上下文对比损失为:
32、;
33、其中,表示质量上下文对比损失;、分别表示查询到的正样本和负样本的特征。
34、本发明的解决方案之二是:
35、一种电子设备,包括处理器、存储器和应用程序;所述应用程序被存储在所述存储器中,并被配置为由所述处理器执行如权利要求1至5任一所述的基于hvs的上下文对比和局部敏感特性的无参考图像质量评估方法。
36、本发明的解决方案之三是:
37、一种计算机可读存储介质,所述存储介质存储有计算机程序;所述计算机程序在所述计算机中执行时,使计算机执行如权利要求1至5任一所述的基于hvs的上下文对比和局部敏感特性的无参考图像质量评估方法。
38、采用上述技术方案后,本发明具有以下技术效果:
39、本发明利用特征对比学习机制,允许模型通过数据库的上下文质量信息进行对比获得与质量相关的特征,以模拟人类擅长比较图像而不是直接判断图像来进行质量预测这一特性;利用质量感知掩码注意力机制,允许模型通过随机掩码图像块,利用一个新的质量令牌捕捉比较细节的质量特征,以模拟人类视觉系统往往会对局部失真敏感的特性。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341862.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表