一种基于跨语言数据迁移的端到端伪造语音检测系统
- 国知局
- 2024-12-06 12:30:21
本发明涉及音频信号处理,尤其涉及一种基于跨语言数据迁移的端到端伪造语音检测系统。
背景技术:
1、随着深度语音合成技术的迅猛发展,文本到语音转换技术及语音到语音转换技术在语音质量上取得了显著的飞跃,这使得合成语音与自然语音之间的界限变得愈发模糊。然而,这种技术进步也带来了一系列安全问题。犯罪分子开始利用这些高保真度的深度合成系统进行身份冒充,实施舆论操纵、电信诈骗和声音身份盗窃等不法行为,对个人隐私和社会安全构成了严重威胁。因此,深度合成技术的音频伪造问题对司法取证工作提出了前所未有的挑战,亟需一种有效的解决方案来识别和防范伪造语音。
2、近年来,研究人员对面向深度合成的伪造音频取证的研究主要集中在是否伪造的真假鉴定上,主要包括流水线与端到端两类方法。流水线方法将检测过程分为前端特征提取和后端分类器设计两个部分。特征提取主要提取区分性特征,常用特征包括谱特征(如线性倒谱系数、梅尔倒谱系数、常数q倒谱系数、修改的组延迟倒谱系数特征、基于滤波的倒谱系数等)、韵律特征(如f0轮廓特征、基频变化特征、音素时长特征、f0子带特征等)、深层嵌入特征等。分类器包括传统机器学习(如支持向量机、隐马尔可夫模型等)和深度学习方法。端到端检测方法集成了前端特征提取与后端分类器,通过直接将两部分联合优化,可以获得较好的性能。
3、目前大多检测方法在域内的检测性能较为显著,而域外数据的检测性能较差。为了提升训练数据的多样性,尽可能覆盖测试数据分布,数据增强是其中一种简单有效的方法。大多数据增强方法通过两个数据增强途径增加训练数据:引入噪声及混响;利用多种声码器合成语音。然而,目前通过声码器合成语音的增强方法需要针对特定目标语言,而合成具有足够多样性的数据往往需要巨大的时间和资源投入。例如,构建asvspoof2019 la子数据集花费了超过6个月的时间。
4、为此,本专利提出一种基于跨语言数据迁移的端到端伪造语音检测系统。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的一种基于跨语言数据迁移的端到端伪造语音检测系统。
2、为了实现上述目的,本发明采用了如下技术方案:
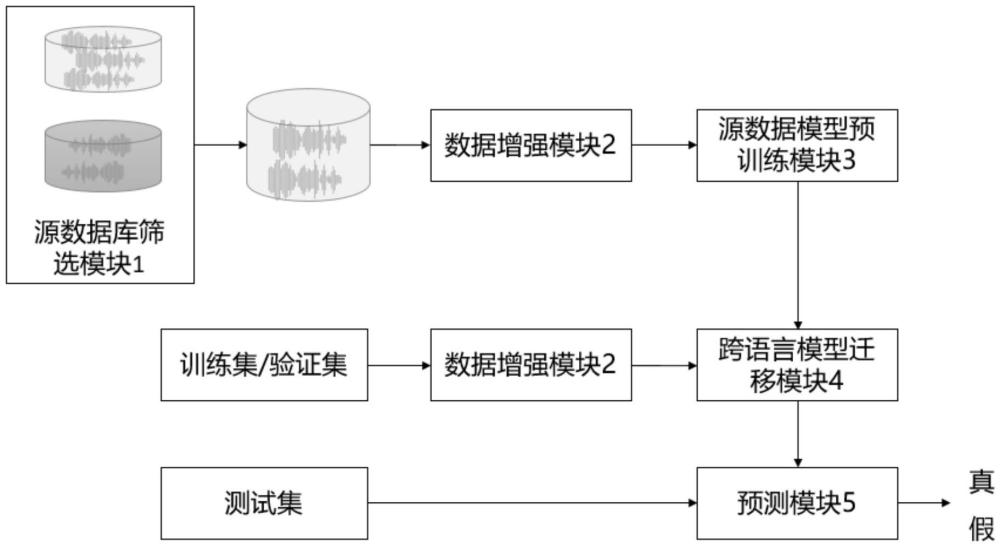
3、一种基于跨语言数据迁移的端到端伪造语音检测系统,包括源数据库筛选模块、数据增强模块、源数据模型预训练模块、跨语言模型迁移模块、预测模块。
4、进一步的,所述源数据库筛选模块用于基于已有的公开数据库筛选出可用于目标语言数据增强的数据。
5、进一步的,所述数据增强模块与所述源数据库筛选模块相连接,用于对语音数据进行增强,以提升数据的多样性。
6、进一步的,所述源数据模型预训练模块与所述数据增强模块相连接,用于基于数据增强后的源数据库产生端到端伪造语音检测预训练模型;
7、所述源数据模型预训练模块包括:
8、前端的深层特征提取模块,用于提取增强后的源数据库的语音的深层特征;
9、线性层模块,与所述前端的深层特征提取模块相连接,用于调整前端的深层特征提取模块的特征维度,允许模型在保留预训练特征的同时,适应伪造语音检测任务;
10、后端的分类器模块,与所述线性层模块相连接,用于鉴别输入源语音的真伪。
11、进一步的,所述跨语言模型迁移模块与所述数据增强模块和源数据模型预训练模块相连接,用于产生目标语言的伪造语音检测模型。
12、进一步的,所述预测模块与所述跨语言模型迁移模块相连接,用于预测目标语言的测试语音是否伪造。
13、相比于现有技术,本发明的有益效果在于:
14、1.本发明采用包括多种语音生成技术的数据库进行预训练,并在目标数据上微调,可以得到更好的性能;
15、2.本发明提高了域外数据的检测性能,增强了模型的泛化能力;
16、3.本发明通过跨语言数据增强,减少了构建训练数据集所需的时间和资源,本发明可以推广到其他语言,特别是低资源语言的伪造语音检测,具有较高的应用价值。
17、综上所述,本发明可以综合提高目标语言伪造语音检测的准确性和效率,使用简单,适用于任意目标语言伪造语音检测任务,具有较高的实用价值。
技术特征:1.一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,包括源数据库筛选模块(1)、数据增强模块(2)、源数据模型预训练模块(3)、跨语言模型迁移模块(4)、预测模块(5)。
2.根据权利要求1所述的一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,所述源数据库筛选模块(1)用于基于已有的公开数据库筛选出可用于目标语言数据增强的数据。
3.根据权利要求2所述的一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,所述数据增强模块(2)与所述源数据库筛选模块(1)相连接,用于对语音数据进行增强,以提升数据的多样性。
4.根据权利要求3所述的一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,所述源数据模型预训练模块(3)与所述数据增强模块(2)相连接,用于基于数据增强后的源数据库产生端到端伪造语音检测预训练模型;
5.根据权利要求4所述的一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,所述跨语言模型迁移模块(4)与所述数据增强模块(2)和源数据模型预训练模块(3)相连接,用于产生目标语言的伪造语音检测模型。
6.根据权利要求5所述的一种基于跨语言数据迁移的端到端伪造语音检测系统,其特征在于,所述预测模块(5)与所述跨语言模型迁移模块(4)相连接,用于预测目标语言的测试语音是否伪造。
技术总结本发明提供了一种基于跨语言数据迁移的端到端伪造语音检测系统,涉及音频信号处理技术领域,包括:源数据库筛选模块,用于基于已有的公开数据库筛选出可用于目标语言数据增强的数据;数据增强模块,用于对语音数据进行增强,以提升数据的多样性;源数据模型预训练模块,用于基于数据增强后的源数据库产生端到端伪造语音检测预训练模型;跨语言模型迁移模块,用于产生目标语言的伪造语音检测模型;预测模块,用于预测目标语言的测试语音是否伪造。本发明可以综合提高目标语言伪造语音检测的准确性和效率,使用简单,适用于任意目标语言伪造语音检测任务,具有较高的实用价值。技术研发人员:戚肖克,易江燕,顾浩,陶建华受保护的技术使用者:中国政法大学技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/341785.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表