语音文本纠错方法、装置、设备及存储介质与流程
- 国知局
- 2024-12-06 12:28:07
本发明涉及语音识别,尤其涉及一种语音文本纠错方法、装置、设备及存储介质。
背景技术:
1、在现有自动语音识别领域中,随着语音技术的发展,从语音到对应文本的语音转录技术在日常生活中逐步普及。语音转录技术主要针对较长的语音进行语音转文字处理,从而得到语音的文字内容。目前,语音转录技术已广泛应用于包括录音笔的内容识别、字幕生成等多种应用场景。
2、因此,自动语音识别(asr)文本纠错技术具有重要的作用,例如在当前的保险业务场景中,客户可以通过语音输入信息,而asr文本纠错技术可以自动识别并更正错误单词或短语,使客户能够更流畅地输入信息,从而提高客户体验和工作效率。虽然现有技术中可以引入了语音信息(汉语拼音),但它们通常将语音表示与字符表示合并,这往往会削弱正常文本的表示效果。
3、自动语音识别(asr)引入的错误通常会影响语音搜索、语音翻译等下游任务的执行。当前纠错技术已被用于优化自动语音识别(asr)模型的输出句子,并实现比原始asr输出更低的单词错误率(wer)。现有技术将语音特征融合到模型中主要有两种方法。首先,使用门机制对汉字拼音进行编码并融合到汉字表示中。其次,引入发音预测目标来模拟音系相似字符之间的关系。尽管这些方法的性能得到了相当大的提高,但它们存在两个潜在的问题。首先,在训练过程中,由于拼音和文本表示之间的纠缠,拼音信息可能被文本信息所忽略或主导。其次,拼音特征的引入可能会削弱正常文本的表征。从直观上看,汉语拼音应该是对汉语文本信息的补充,而不是替代,原因有二。首先,存在一对多关系在拼音和汉字之间,仅从拼音中恢复正确的汉字比从汉字中恢复正确的汉字更困难。其次,在现有的语言模型中,拼音表示没有作为文本表示进行预训练。因此,模型应避免过度依赖拼音,以免造成过拟合。
技术实现思路
1、本发明的主要目的在于提供一种语音文本纠错方法、装置、设备及存储介质,旨在解决现有语音文本纠错技术对语音文本纠错准确性低的技术问题。
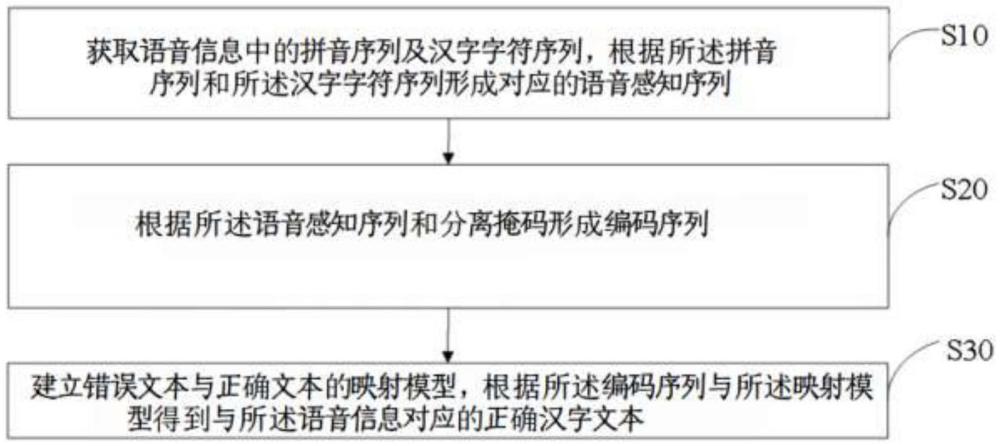
2、为实现上述目的,本发明提供一种语音文本纠错方法,所述语音文本纠错方法包括以下步骤:
3、获取语音信息中的拼音序列及汉字字符序列,根据所述拼音序列和所述汉字字符序列形成对应的语音感知序列;
4、根据所述语音感知序列和分离掩码形成编码序列;
5、建立错误文本与正确文本的映射模型,根据所述编码序列与所述映射模型得到与所述语音信息对应的正确汉字文本。
6、可选地,所述根据所述拼音序列和所述汉字字符序列形成对应的语音感知序列的步骤包括:
7、将所述汉字字符序列中的每一个汉字编码为词嵌入、位置嵌入和段嵌入的和;
8、将所述拼音序列中的每一个拼音编码为初始嵌入、最终嵌入、位置嵌入和段嵌入的和,其中每一个汉字与其对应的拼音在编码后的位置嵌入相同。。
9、可选地,所述根据所述语音感知序列和分离掩码形成编码序列的步骤包括:
10、所述分离掩码为掩码矩阵m∈r2n×2n:
11、
12、将所述分离掩码用于对所述语音感知序列的编码,输出ol公式为:
13、
14、ol=alvl.
15、公式中为可训练参数,hl-1为前一层的输出,d为维度大小,m为掩码矩阵。
16、可选地,所述建立错误文本与正确文本的映射模型的步骤包括:
17、获取所述错误文本与所述正确文本的训练数据集,将所述错误文本与所述正确文本映射为公式:
18、hq=wqhe+be
19、hk=wkhc+bc;
20、公式中错误文本的表示为he,正确文本的表示为hc,hq为将错误文本he映射后的错误的隐藏表示,hk为将正确文本hc映射后的正确的隐藏表示;
21、采用双仿射注意力模拟hq和hk之间的相互作用,公式为:
22、
23、公式中u∈r|h|x|h|x|l|,|h|、|l|表示隐藏大小和标签集大小;
24、训练至使交叉熵最小化,得到所述映射模型。
25、可选地,所述得到所述映射模型的步骤之前,还包括:
26、获取训练样本,根据所述训练样本生成文本部分的预测损失函数,公式为:
27、公式中x为所述训练样本中的字符序列,y为所述训练样本中x的校正序列,p为输出分布;
28、获取与所述矫正序列对应的拼音序列z,生成拼音部分的预测损失函数,公式为:
29、根据所述文本部分的预测损失函数与所述拼音部分的预测损失函数及交叉熵所述训练模型。
30、可选地,所述根据所述文本部分的预测损失函数与所述拼音部分的预测损失函数及交叉熵所述训练模型的步骤包括:
31、根据所述文本部分的预测损失函数与所述拼音部分的预测损失函数及交叉熵建立总损失函数,公式为:
32、公式中α、β是可调的超参数,通过使所述总损失函数l最小化训练模型。
33、可选地,所述获取语音信息中的拼音序列及汉字字符序列的步骤包括:
34、从所述语音信息中分离出原始人声信号;
35、对所述所述原始人声信号进行语音端点检测,以根据检测到的语音端点将所述原始人声信号拆分成至少一段人声信号;
36、对每段人声信号进行语音识别,得到每段人声信号对应的所述拼音序列及所述汉字字符序列。
37、进一步地,为实现上述目的,本发明还提供一种语音文本纠错装置,所述语音文本纠错装置包括:
38、语音感知模块,获取语音信息中的拼音序列及汉字字符序列,根据所述拼音序列和所述汉字字符序列形成对应的语音感知序列;
39、语音编码模块,根据所述语音感知序列和分离掩码形成编码序列;
40、语音映射模块,建立错误文本与正确文本的映射模型,根据所述编码序列与所述映射模型得到与所述语音信息对应的正确汉字文本。
41、进一步地,为实现上述目的,本发明还提供一种语音文本纠错设备,所述语音文本纠错设备包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的语音文本纠错程序,所述语音文本纠错程序被所述处理器执行时实现如上述所述的语音文本纠错方法的步骤。
42、进一步地,为实现上述目的,本发明还提供一种存储介质,所述存储介质上存储有语音文本纠错程序,所述语音文本纠错程序被处理器执行时实现如上所述的语音文本纠错方法的步骤。
43、本发明通过获取语音信息,得到语音信息中的汉字字符序列及与汉字字符序列对应的拼音序列,再根据拼音序列与汉字字符序列组合生成语音感知序列,再引入带分离掩码的编码器,根据语音感知序列与分割掩码形成编码序列,同时根据错误文本与正确文本之间的依赖关系建立映射模型,则根据编码序列及映射模型得到与语音信息对应的正确汉字文本,能更准确地定位可能存在错误的部分,可以更好地处理语言结构上的复杂性,从而提高了纠错的准确性。
技术特征:1.一种语音文本纠错方法,其特征在于,所述语音文本纠错包括以下步骤:
2.如权利要求1所述的语音文本纠错方法,其特征在于,所述根据所述拼音序列和所述汉字字符序列形成对应的语音感知序列的步骤包括:
3.如权利要求1所述的语音文本纠错方法,其特征在于,所述根据所述语音感知序列和分离掩码形成编码序列的步骤包括:
4.如权利要求3所述的语音文本纠错方法,其特征在于,所述建立错误文本与正确文本的映射模型的步骤包括:
5.如权利要求4所述的语音文本纠错方法,其特征在于,所述得到所述映射模型的步骤之前,还包括:
6.如权利要求5所述的语音文本纠错方法,其特征在于,所述根据所述文本部分的预测损失函数与所述拼音部分的预测损失函数及交叉熵所述训练模型的步骤包括:
7.如权利要求1所述的语音文本纠错方法,其特征在于,所述获取语音信息中的拼音序列及汉字字符序列的步骤包括:
8.一种语音文本纠错装置,其特征在于,所述语音文本纠错装置包括:
9.一种语音文本纠错设备,其特征在于,所述语音文本纠错设备包括存储器、处理器以及存储在所述存储器上并可以在所述处理器上运行的语音文本纠错程序,所述语音文本纠错程序被所述处理器执行时实现如权利要求1-7中任一项所述的语音文本纠错方法的步骤。
10.一种存储介质,其特征在于,所述存储介质上存储有语音文本纠错程序,所述语音文本纠错程序被处理器执行时实现如权利要求1-7中任一项所述的语音文本纠错方法的步骤。
技术总结本发明公开了一种语音文本纠错方法、语音文本纠错装置、语音文本纠错设备及存储介质,该方法通过获取语音信息,得到语音信息中的汉字字符序列及与汉字字符序列对应的拼音序列,再根据拼音序列与汉字字符序列组合生成语音感知序列,再引入带分离掩码的编码器,根据语音感知序列与分割掩码形成编码序列,同时根据错误文本与正确文本之间的依赖关系建立映射模型,则根据编码序列及映射模型得到与语音信息对应的正确汉字文本,能更准确地定位可能存在错误的部分,可以更好地处理语言结构上的复杂性,从而提高了纠错的准确性。技术研发人员:张镛,王健宗,程宁,范佳欣受保护的技术使用者:平安科技(深圳)有限公司技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/341557.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。