基于ISAC的车联网协同感知资源分配方法
- 国知局
- 2025-01-10 13:11:36
本发明属于移动通信,涉及一种基于isac的车联网协同感知资源分配方法。
背景技术:
1、单个联网自动汽车(connected automatic vehicles,cav)的感知能力存在固有的局限性,基于车联网的协同感知技术的出现可以克服这一缺陷,通过融合多个cav和rsu的感知数据,可以大幅扩展感知范围并提高感知准确性。然而,现有的单层协同感知方案仍存在一些问题。首先是带宽和计算能力利用率饱和或不足,早期融合中,过量的原始数据传输可能会导致带宽饱和而计算能力未充分利用,后期融合中,本地处理后发送对象数据可能会导致计算能力饱和而带宽未充分利用,即使是中期融合在动态网络条件下,仍存在上述问题。其次,对于单个cav,其最关注的路况信息并不是全局的地图信息而是较近范围内的路况信息,生成完整的全局环境地图需要处理大量的感知数据,给系统的计算和通信带来巨大负担,导致整体延迟较高。因此需要设计更加灵活高效的协同感知方案,提高系统性能。
2、通感一体化(integrated communication and sensing,isac)设备在协同感知中起着关键作用。这类设备可以同时执行雷达感知和通信功能,为协同感知提供必要的硬件基础。通过协调雷达和通信资源的利用,isac设备能够在感知和通信之间实现有效的平衡,为整个协同感知系统的性能优化提供重要支撑。然而,现有的isac设备在感知和通信性能平衡以及本地计算资源利用方面存在一些问题。由于感知和通信功能之间存在干扰,很难在二者之间实现最佳的资源配置。同时,没有考虑到车载计算能力的引入,导致整个协同感知过程中出现较高的时延。通过分析不同持续时间分配比率对感知和通信性能的影响,并结合车载计算能力,得出了cav和rsu最佳的时间分配比范围,可以降低了整个协同感知过程的时延。为isac设备在协同感知场景中的应用提供了一种灵活高效的解决方案。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于isac的车联网协同感知资源分配方法,能够实现对车联网协同感知资源分配策略的优化,降低协同感知的执行延迟。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于isac的车联网协同感知资源分配方法,其包括以下步骤:
4、s1、在车联网场景下构建基于相对位置的多层协同感知关心区域方案;
5、s2、根据当前车辆的感知关心区域与路测单元、其他车联网车辆的相对位置确认共同感知者;
6、s3、构建基于时分动态帧结构的通感一体化isac时间分配方案,获取共同感知者的雷达感测持续时间的总感知互信息smi、通信持续时间的平均通信速率以及各个处理方式的执行延迟;
7、s4、建立以最小化协同感知任务完成延迟为目标的感知任务分配、卸载和计算资源分配的联合问题;
8、s5、采用混合动作空间的多智能体深度确定性策略梯度算法求解优化问题得到最小任务完成延迟的资源分配方案。
9、进一步,在步骤s1中,车联网场景包括若干车联网自动车辆cav、若干路测单元rsu以及若干移动边缘服务器mes,cav通过各种传感器采集车内外数据,沿路部署的若干rsu通过高速有线链路相互连接,每个rsu均通过有线链路与mes连接;
10、当前cav根据感知关心区域中的rsu和其他cav的相对位置选择共同感知者,当前cav或共同感知者对于感知数据的处理包括本地处理和卸载处理;
11、设n={1,...,i,...,n}为系统中cav的集合,感知关心区域为ppac,prsu表示rsu的覆盖范围,当前车辆v1无法感知ppac中的所有区域,将ppac分为p1、pf和pb,p1为v1视野范围内的区域,pf和pb分别为v1前后的遮挡区域,则:
12、ppac=p1+pf+pb
13、将三个区域的感知任务分别定义为t1,tf,tb,cav感知关心区域的感知任务表示为:
14、tpac=t1+tf+tb
15、cav进行感知任务处理的方式包括本地处理或者卸载处理。
16、进一步,在步骤s2中,将当前车辆从当前rsu的覆盖范围转移到下一个rsu覆盖范围的过程分为以下五个阶段,每个阶段的共同感知者的选择范围为:
17、在第一个阶段,tpac完全处于rsuj的覆盖范围,其共同感知者可选择rsuj和处于pb,pf的cav;
18、
19、vf表示ppac中v1之前的cav,vb表示ppac中v1之后的cav,vf和vb可能有多个也可能没有,vv2v为v1通信范围内的cav集合,uj表示v1当前所处范围的rsuj,uj+1表示v1即将进入的rsuj+1;
20、在第二个阶段,tpac的pf部分进入rsuj+1的覆盖范围,共同感知者可选择rsuj、rsuj+1和处于pb,pf的cav;
21、
22、在第三个阶段,tpac的pf进入rsuj+1的覆盖范围,pb未进入,其共同感知者可选择rsuj、rsuj+1和处于pf的cav;
23、
24、在第四个阶段,tpac的pb部分进入rsuj+1的覆盖范围,其共同感知者可选择rsuj、rsuj+1和处于pb,pf的cav;
25、
26、在第五个阶段中,tpac的已经完全进入rsuj+1的覆盖范围。其共同感知者可选择rsuj+1和处于pb,pf的cav;
27、
28、将任务分配函数定义为y=ta(x),表明tpac中的协作任务分配给y,根据相对位置信息,在rsu和cav中选择一组共同感知者来协助v1完成感知任务;设ω表示选定的共同感知者的集合,其满足:
29、ω=ta(t1)∪taρ(tf)∪taρ(tb)
30、式中taρ(t1)、taρ(tf)、taρ(tb)分别表示能够感知t0、tf、tb的感知者,ρ=1,2,3,4,5表示所处的阶段。
31、进一步,在步骤s3中,首先构建包括s个感测子帧、p个计算子帧和q个通信子帧的可调帧格式,每个周期中有ns个子帧,设每个子帧的持续时间为τs,将每个车辆isac设备的时间分配决策描述为χvi={ai,bi,ci},其中,vi∈ωv,ai,bi,ci分别为vi对应的归一化感知持续时间、计算持续时间和感知持续时间,ai+bi+ci=1,其中,
32、雷达探测过程中,vi在雷达感测持续时间ai的平均感知互信息(sensing mutualinformation,smi)表示为:
33、
34、其中,bi表示为分配给vi的带宽;为vi的信号和干扰加噪声比,其表示为:
35、
36、式中pi是vi的发射功率,表示路径传播增益,nr-rad和nr-com分别表示其他cav对vi的雷达信号造成的雷达干扰和通信干扰;n0表示热噪声功率谱密度。
37、进一步,在步骤s3中,通信过程中,vi在通信持续时间ci过程的总通信数据量为:
38、
39、vi在通信持续时间ci的平均通信速率为:
40、
41、其中,表示vi通信信号的信噪比,其表示为:
42、
43、式中,gt和gr表示天线发射增益和天线接收增益,表示i到j的通信信道增益,和分别为所受雷达干扰和所受通信干扰。
44、进一步,在步骤s3中,对于各个执行时延,将感知任务描述为li={si,di,τi},si表示感知任务中需要提取的环境信息量,di表示处理一位环境信息需要的cpu周期数,τi表示整个感知任务完成的最大可容忍延迟,有:
45、车辆本地处理感知数据的执行延迟为:
46、
47、式中,表示分配给本地任务的cpu周期频率,定义有cav的最高cpu周期频率满足
48、车辆卸载到服务器的执行延迟为:
49、
50、式中,为rsuj的最高cpu周期频率,μvi表示分配给vi的计算资源的比例。
51、rsu侧的执行延迟为:
52、
53、式中,表示uj分配用于任务处理的计算资源的比例。
54、进一步,在步骤s4中,将协同感知任务分配、卸载和计算资源分配优化方案制定为最小化协同感知任务处理时延最小化问题,优化问题表示为:
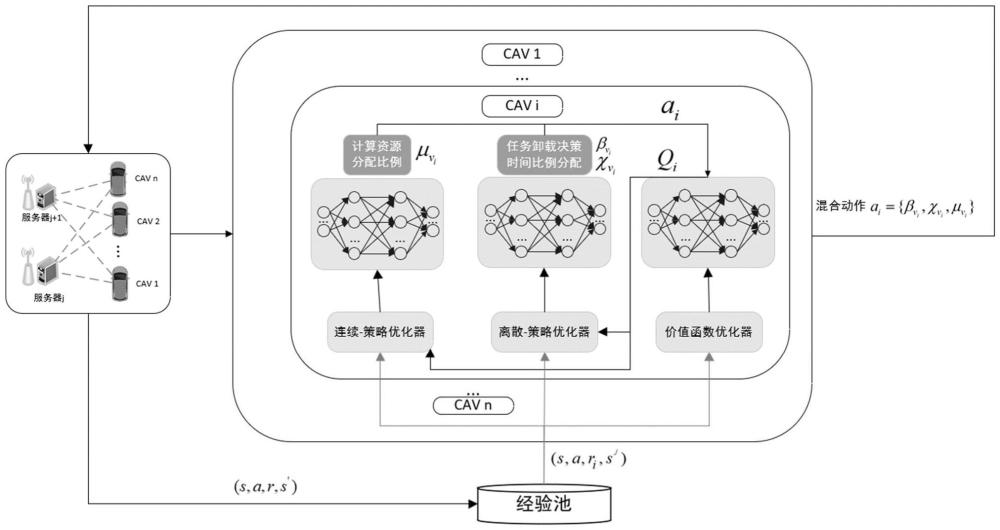
55、
56、其中为车辆卸载决策,为车辆isac设备时间分配比例,为mes为车辆分配的计算资源比例,ωv表示被选为共同感知者的cav,ωu表示被选为共同感知者的rsu;
57、c1表示选择共同感知者;c2表示vi和uj的总处理时间不能超过最大可容忍延迟;c3表示vi分配的归一化感知、通信和计算时间比例之和为1;c4表示在同一个周期内,通信的数据量不能超过感知的数据量;c5表示实际需要的感知、通信和计算的时间不大于分配的感知、通信和计算的时间;c6表示提供卸载服务的rsu分配的资源比例之和不大于1。
58、进一步,在步骤s5中,将优化问题转化为马尔可夫决策过程,状态空间设置为:
59、
60、其中,b,g,l分别表示mes的剩余计算资源状态、cav和mes之间的通信链路的信道增益、cav和mes之间的连接状态;
61、动作空间:
62、以卸载决策βvi、时间比例分配的离散动作和计算资源分配比例μ的连续变量共同作为cav的混合动作
63、奖励:
64、
65、其中β为常数,当延迟降低时,奖励增大;
66、训练价值网络的目标是最小化状态-动作价值函数的预测误差,假设每个cav的参数为θ={θ1,θ2,,...,θi...,θn},对每个cavi,使用目标网络计算目标值;计算目标动作a'j,其中a'j=μ'j(s')表示第j个智能体在下一状态s'j下的目标动作,j∈{1,2,...,n},则目标值为:
67、yi=ri+γq'i(s',ai)
68、其中q'i为cavi的目标价值网络;
69、通过最小化均方误差损失来更新价值网络参数θi:
70、
71、其中b为从经验回放区中抽取的一个批次;
72、训练策略网络时,假设每个cav的策略网络参数为ω={ω1,ω2,...ωi,...ωn},对于每个cavi,使用策略梯度更新策略网络,策略梯度为:
73、
74、使用梯度上升法更新策略网络参数ωi;
75、对于价值网络和策略网络的目标网络参数,使用软更新:
76、θi'=τθi'+(1-τ)θi
77、ωi'=τωi'+(1-τ)ωi
78、其中,τ表示软更新参数。
79、进一步,在步骤s5中,采用混合动作空间的多智能体深度确定性策略梯度算法求解优化问题的具体过程包括:
80、s51:初始化每个cav的actor网络和critic网络;
81、s52:在每次迭代中,初始化一个随机进程用于动作探索,获取每个cav的初始观测即环境的初始状态;
82、s53:在每个时隙,根据当前的策略和状态,每个cav选择动作并执行;
83、s54:在每个时隙,所有cav与环境交互获得各自的奖励并且跳到下一状态,将经验数据储存在经验回放池中;
84、s55:对每个cav,从经验池中随机抽取小批量的样本;
85、s56:对每个cav,计算critic的目标状态值,计算损失函数,并最小化损失来更新critic网络,计算策略梯度,更新actor网络;
86、s57:完成每个cav后软更新价值网络和策略网络的目标网络参数,然后返回s53,否则返回s55;
87、s58:完成每个时隙后返回s52,否则返回s53;
88、s59:完成迭代后停止,否则返回s52。
89、本发明的有益效果在于:
90、本发明针对现有车联网中协同感知融合方案带宽和计算资源利用率饱和或不足、生成全局地图数据量大,以及isac设计未能平衡感知和通信性能而导致系统高延迟的问题,提出了一种基于isac的车联网协同感知资源分配方案。首先,为减少传输数据量并合理利用带宽和计算资源,提出一种基于相对位置的多层协同感知关心区域方案。其次,提出基于时分动态帧结构的isac感知、通信和计算时间分配方案,分析不同时间分配比对感知和通信互信息(mi)的影响,并根据cav的计算能力进行时间分配。本发明能够实现对车联网协同感知资源分配策略的优化,降低协同感知的执行延迟。
91、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
本文地址:https://www.jishuxx.com/zhuanli/20250110/351540.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。